 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedding Privacy in Computational Social Science and Artificial Intelligence Research
Apr 17, 2024Privacy is a human right. It ensures that individuals are free to engage in discussions, participate in groups, and form relationships online or offline without fear of their data being inappropriately harvested, analyzed, or otherwise used to harm them. Preserving privacy has emerged as a critical factor in research, particularly in the computational social science (CSS), artificial intelligence (AI) and data science domains, given their reliance on individuals' data for novel insights. The increasing use of advanced computational models stands to exacerbate privacy concerns because, if inappropriately used, they can quickly infringe privacy rights and lead to adverse effects for individuals - especially vulnerable groups - and society. We have already witnessed a host of privacy issues emerge with the advent of large language models (LLMs), such as ChatGPT, which further demonstrate the importance of embedding privacy from the start. This article contributes to the field by discussing the role of privacy and the primary issues that researchers working in CSS, AI, data science and related domains are likely to face. It then presents several key considerations for researchers to ensure participant privacy is best preserved in their research design, data collection and use, analysis, and dissemination of research results.
A Comprehensive Survey of Natural Language Generation Advances from the Perspective of Digital Deception
Aug 11, 2022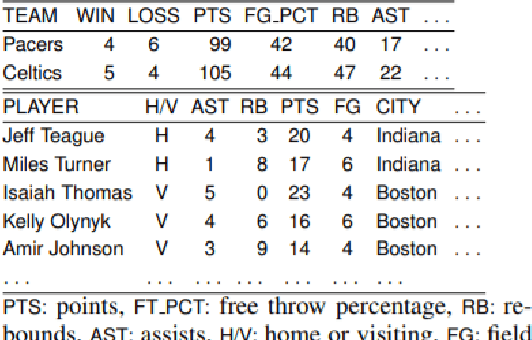


In recent years there has been substantial growth in the capabilities of systems designed to generate text that mimics the fluency and coherence of human language. From this, there has been considerable research aimed at examining the potential uses of these natural language generators (NLG) towards a wide number of tasks. The increasing capabilities of powerful text generators to mimic human writing convincingly raises the potential for deception and other forms of dangerous misuse. As these systems improve, and it becomes ever harder to distinguish between human-written and machine-generated text, malicious actors could leverage these powerful NLG systems to a wide variety of ends, including the creation of fake news and misinformation, the generation of fake online product reviews, or via chatbots as means of convincing users to divulge private information. In this paper, we provide an overview of the NLG field via the identification and examination of 119 survey-like papers focused on NLG research. From these identified papers, we outline a proposed high-level taxonomy of the central concepts that constitute NLG, including the methods used to develop generalised NLG systems, the means by which these systems are evaluated, and the popular NLG tasks and subtasks that exist. In turn, we provide an overview and discussion of each of these items with respect to current research and offer an examination of the potential roles of NLG in deception and detection systems to counteract these threats. Moreover, we discuss the broader challenges of NLG, including the risks of bias that are often exhibited by existing text generation systems. This work offers a broad overview of the field of NLG with respect to its potential for misuse, aiming to provide a high-level understanding of this rapidly developing area of research.
Are You Robert or RoBERTa? Deceiving Online Authorship Attribution Models Using Neural Text Generators
Mar 18, 2022
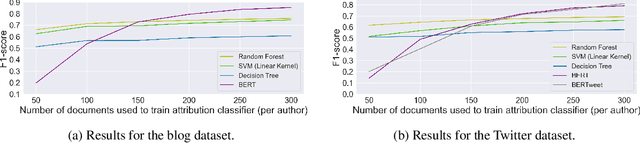

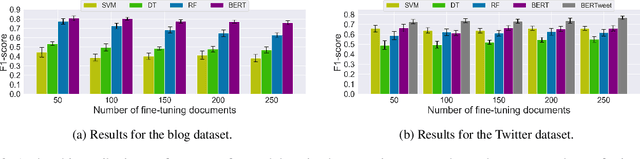
Recently, there has been a rise in the development of powerful pre-trained natural language models, including GPT-2, Grover, and XLM. These models have shown state-of-the-art capabilities towards a variety of different NLP tasks, including question answering, content summarisation, and text generation. Alongside this, there have been many studies focused on online authorship attribution (AA). That is, the use of models to identify the authors of online texts. Given the power of natural language models in generating convincing texts, this paper examines the degree to which these language models can generate texts capable of deceiving online AA models. Experimenting with both blog and Twitter data, we utilise GPT-2 language models to generate texts using the existing posts of online users. We then examine whether these AI-based text generators are capable of mimicking authorial style to such a degree that they can deceive typical AA models. From this, we find that current AI-based text generators are able to successfully mimic authorship, showing capabilities towards this on both datasets. Our findings, in turn, highlight the current capacity of powerful natural language models to generate original online posts capable of mimicking authorial style sufficiently to deceive popular AA methods; a key finding given the proposed role of AA in real world applications such as spam-detection and forensic investigation.
Out of the Shadows: Analyzing Anonymous' Twitter Resurgence during the 2020 Black Lives Matter Protests
Jul 22, 2021
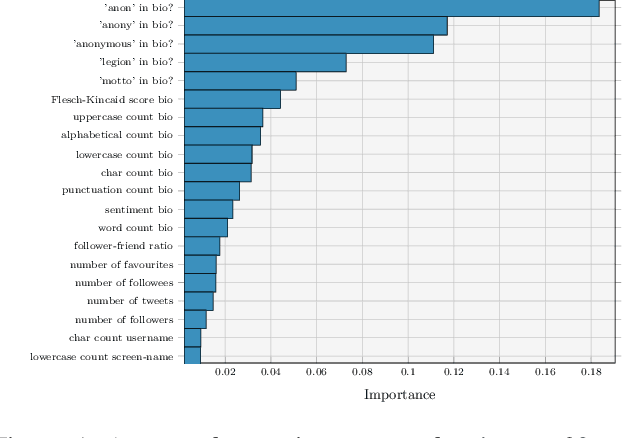
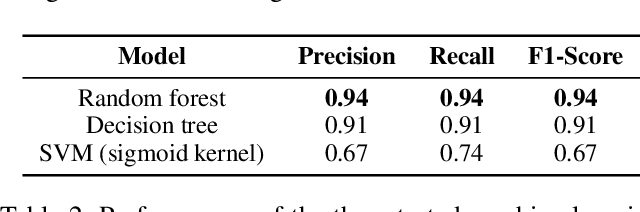
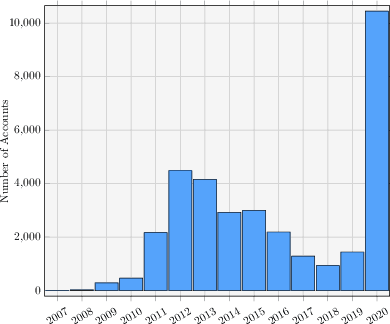
Recently, there had been little notable activity from the once prominent hacktivist group, Anonymous. The group, responsible for activist-based cyber attacks on major businesses and governments, appeared to have fragmented after key members were arrested in 2013. In response to the major Black Lives Matter (BLM) protests that occurred after the killing of George Floyd, however, reports indicated that the group was back. To examine this apparent resurgence, we conduct a large-scale study of Anonymous affiliates on Twitter. To this end, we first use machine learning to identify a significant network of more than 33,000 Anonymous accounts. Through topic modelling of tweets collected from these accounts, we find evidence of sustained interest in topics related to BLM. We then use sentiment analysis on tweets focused on these topics, finding evidence of a united approach amongst the group, with positive tweets typically being used to express support towards BLM, and negative tweets typically being used to criticize police actions. Finally, we examine the presence of automation in the network, identifying indications of bot-like behavior across the majority of Anonymous accounts. These findings show that whilst the group has seen a resurgence during the protests, bot activity may be responsible for exaggerating the extent of this resurgence.
The Shadowy Lives of Emojis: An Analysis of a Hacktivist Collective's Use of Emojis on Twitter
May 07, 2021
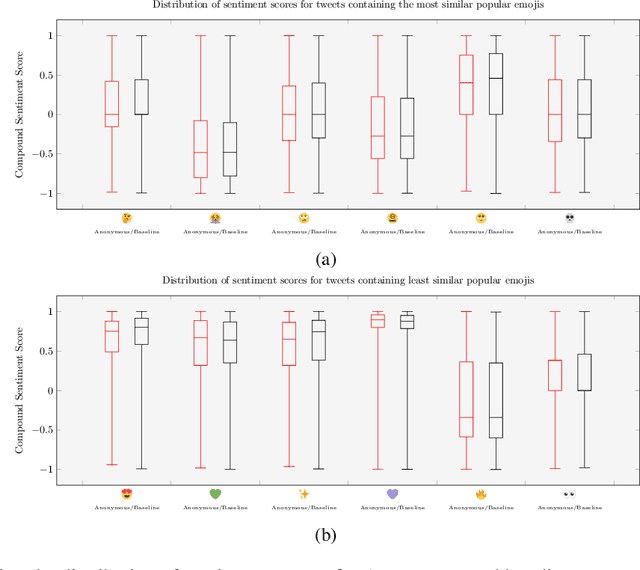
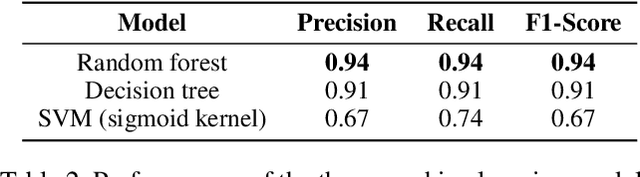

Emojis have established themselves as a popular means of communication in online messaging. Despite the apparent ubiquity in these image-based tokens, however, interpretation and ambiguity may allow for unique uses of emojis to appear. In this paper, we present the first examination of emoji usage by hacktivist groups via a study of the Anonymous collective on Twitter. This research aims to identify whether Anonymous affiliates have evolved their own approach to using emojis. To do this, we compare a large dataset of Anonymous tweets to a baseline tweet dataset from randomly sampled Twitter users using computational and qualitative analysis to compare their emoji usage. We utilise Word2Vec language models to examine the semantic relationships between emojis, identifying clear distinctions in the emoji-emoji relationships of Anonymous users. We then explore how emojis are used as a means of conveying emotions, finding that despite little commonality in emoji-emoji semantic ties, Anonymous emoji usage displays similar patterns of emotional purpose to the emojis of baseline Twitter users. Finally, we explore the textual context in which these emojis occur, finding that although similarities exist between the emoji usage of our Anonymous and baseline Twitter datasets, Anonymous users appear to have adopted more specific interpretations of certain emojis. This includes the use of emojis as a means of expressing adoration and infatuation towards notable Anonymous affiliates. These findings indicate that emojis appear to retain a considerable degree of similarity within Anonymous accounts as compared to more typical Twitter users. However, their are signs that emoji usage in Anonymous accounts has evolved somewhat, gaining additional group-specific associations that reveal new insights into the behaviours of this unusual collective.
Behind the Mask: A Computational Study of Anonymous' Presence on Twitter
Jun 15, 2020


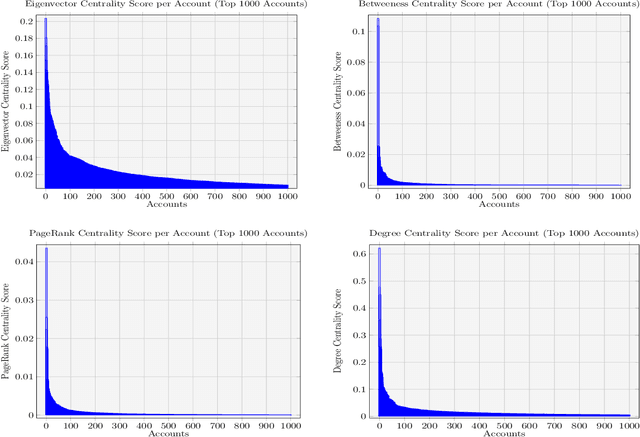
The hacktivist group Anonymous is unusual in its public-facing nature. Unlike other cybercriminal groups, which rely on secrecy and privacy for protection, Anonymous is prevalent on the social media site, Twitter. In this paper we re-examine some key findings reported in previous small-scale qualitative studies of the group using a large-scale computational analysis of Anonymous' presence on Twitter. We specifically refer to reports which reject the group's claims of leaderlessness, and indicate a fracturing of the group after the arrests of prominent members in 2011-2013. In our research, we present the first attempts to use machine learning to identify and analyse the presence of a network of over 20,000 Anonymous accounts spanning from 2008-2019 on the Twitter platform. In turn, this research utilises social network analysis (SNA) and centrality measures to examine the distribution of influence within this large network, identifying the presence of a small number of highly influential accounts. Moreover, we present the first study of tweets from some of the identified key influencer accounts and, through the use of topic modelling, demonstrate a similarity in overarching subjects of discussion between these prominent accounts. These findings provide robust, quantitative evidence to support the claims of smaller-scale, qualitative studies of the Anonymous collective.
* 12 pages, 5 figures. Published in the proceedings of the fourteenth International AAAI Conference on Web and Social Media