 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePassTSL: Modeling Human-Created Passwords through Two-Stage Learning
Jul 19, 2024Textual passwords are still the most widely used user authentication mechanism. Due to the close connections between textual passwords and natural languages, advanced technologies in natural language processing (NLP) and machine learning (ML) could be used to model passwords for different purposes such as studying human password-creation behaviors and developing more advanced password cracking methods for informing better defence mechanisms. In this paper, we propose PassTSL (modeling human-created Passwords through Two-Stage Learning), inspired by the popular pretraining-finetuning framework in NLP and deep learning (DL). We report how different pretraining settings affected PassTSL and proved its effectiveness by applying it to six large leaked password databases. Experimental results showed that it outperforms five state-of-the-art (SOTA) password cracking methods on password guessing by a significant margin ranging from 4.11% to 64.69% at the maximum point. Based on PassTSL, we also implemented a password strength meter (PSM), and our experiments showed that it was able to estimate password strength more accurately, causing fewer unsafe errors (overestimating the password strength) than two other SOTA PSMs when they produce the same rate of safe errors (underestimating the password strength): a neural-network based method and zxcvbn. Furthermore, we explored multiple finetuning settings, and our evaluations showed that, even a small amount of additional training data, e.g., only 0.1% of the pretrained data, can lead to over 3% improvement in password guessing on average. We also proposed a heuristic approach to selecting finetuning passwords based on JS (Jensen-Shannon) divergence and experimental results validated its usefulness. In summary, our contributions demonstrate the potential and feasibility of applying advanced NLP and ML methods to password modeling and cracking.
SE#PCFG: Semantically Enhanced PCFG for Password Analysis and Cracking
Jun 12, 2023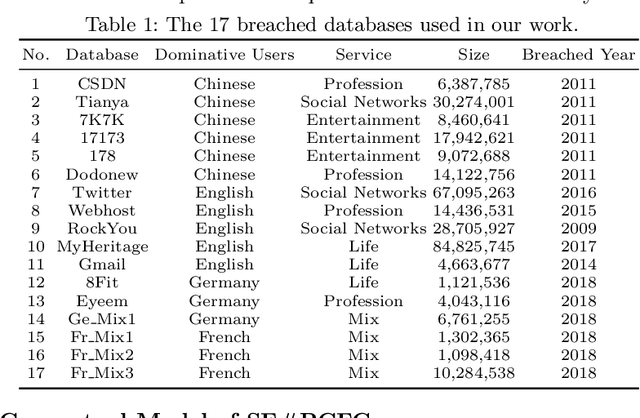
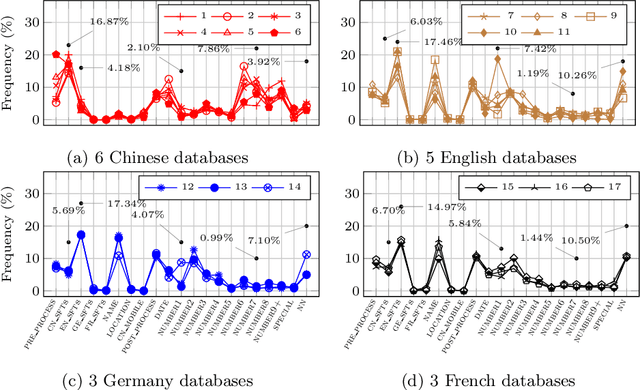

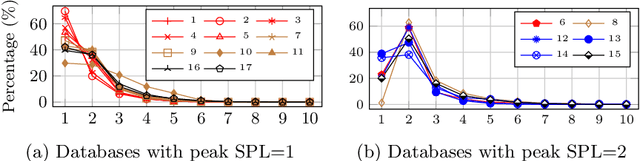
Much research has been done on user-generated textual passwords. Surprisingly, semantic information in such passwords remain underinvestigated, with passwords created by English- and/or Chinese-speaking users being more studied with limited semantics. This paper fills this gap by proposing a general framework based on semantically enhanced PCFG (probabilistic context-free grammars) named SE#PCFG. It allowed us to consider 43 types of semantic information, the richest set considered so far, for semantic password analysis. Applying SE#PCFG to 17 large leaked password databases of user speaking four languages (English, Chinese, German and French), we demonstrate its usefulness and report a wide range of new insights about password semantics at different levels such as cross-website password correlations. Furthermore, based on SE#PCFG and a new systematic smoothing method, we proposed the Semantically Enhanced Password Cracking Architecture (SEPCA). To compare the performance of SEPCA against three state-of-the-art (SOTA) benchmarks in terms of the password coverage rate: two other PCFG variants and FLA. Our experimental results showed that SEPCA outperformed all the three benchmarks consistently and significantly across 52 test cases, by up to 21.53%, 52.55% and 7.86%, respectively, at the user level (with duplicate passwords). At the level of unique passwords, SEPCA also beats the three benchmarks by up to 33.32%, 86.19% and 10.46%, respectively. The results demonstrated the power of SEPCA as a new password cracking framework.