 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Rate-Distortion-Perception-Classification Tradeoff: Joint Source Coding and Modulation via Inverse-Domain GANs
Dec 22, 2023The joint source coding and modulation (JSCM) framework was enabled by recent developments in deep learning, which allows to automatically learn from data, and in an end-to-end fashion, the best compression codes and modulation schemes. In this paper, we show the existence of a strict tradeoff between channel rate, distortion, perception, and classification accuracy in a JSCM scenario. We then propose two image compression methods to navigate that tradeoff: an inverse-domain generative adversarial network (ID-GAN), which achieves extreme compression, and a simpler, heuristic method that reveals insights about the performance of ID-GAN. Experiment results not only corroborate the theoretical findings, but also demonstrate that the proposed ID-GAN algorithm significantly improves system performance compared to traditional separation-based methods and recent deep JSCM architectures.
SE#PCFG: Semantically Enhanced PCFG for Password Analysis and Cracking
Jun 12, 2023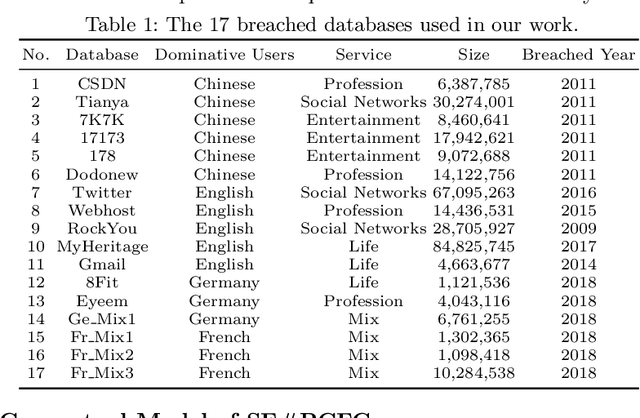
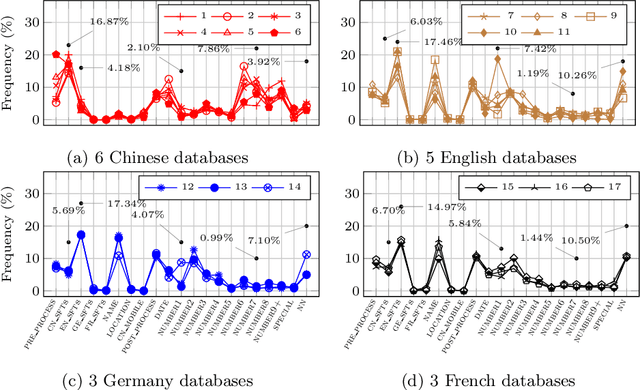

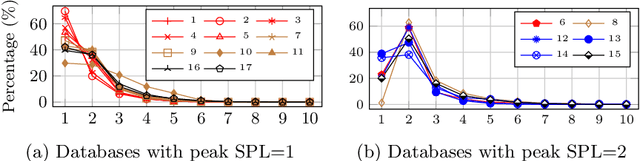
Much research has been done on user-generated textual passwords. Surprisingly, semantic information in such passwords remain underinvestigated, with passwords created by English- and/or Chinese-speaking users being more studied with limited semantics. This paper fills this gap by proposing a general framework based on semantically enhanced PCFG (probabilistic context-free grammars) named SE#PCFG. It allowed us to consider 43 types of semantic information, the richest set considered so far, for semantic password analysis. Applying SE#PCFG to 17 large leaked password databases of user speaking four languages (English, Chinese, German and French), we demonstrate its usefulness and report a wide range of new insights about password semantics at different levels such as cross-website password correlations. Furthermore, based on SE#PCFG and a new systematic smoothing method, we proposed the Semantically Enhanced Password Cracking Architecture (SEPCA). To compare the performance of SEPCA against three state-of-the-art (SOTA) benchmarks in terms of the password coverage rate: two other PCFG variants and FLA. Our experimental results showed that SEPCA outperformed all the three benchmarks consistently and significantly across 52 test cases, by up to 21.53%, 52.55% and 7.86%, respectively, at the user level (with duplicate passwords). At the level of unique passwords, SEPCA also beats the three benchmarks by up to 33.32%, 86.19% and 10.46%, respectively. The results demonstrated the power of SEPCA as a new password cracking framework.
ForceFormer: Exploring Social Force and Transformer for Pedestrian Trajectory Prediction
Feb 15, 2023Predicting trajectories of pedestrians based on goal information in highly interactive scenes is a crucial step toward Intelligent Transportation Systems and Autonomous Driving. The challenges of this task come from two key sources: (1) complex social interactions in high pedestrian density scenarios and (2) limited utilization of goal information to effectively associate with past motion information. To address these difficulties, we integrate social forces into a Transformer-based stochastic generative model backbone and propose a new goal-based trajectory predictor called ForceFormer. Differentiating from most prior works that simply use the destination position as an input feature, we leverage the driving force from the destination to efficiently simulate the guidance of a target on a pedestrian. Additionally, repulsive forces are used as another input feature to describe the avoidance action among neighboring pedestrians. Extensive experiments show that our proposed method achieves on-par performance measured by distance errors with the state-of-the-art models but evidently decreases collisions, especially in dense pedestrian scenarios on widely used pedestrian datasets.
DEXTER: Deep Encoding of External Knowledge for Named Entity Recognition in Virtual Assistants
Aug 15, 2021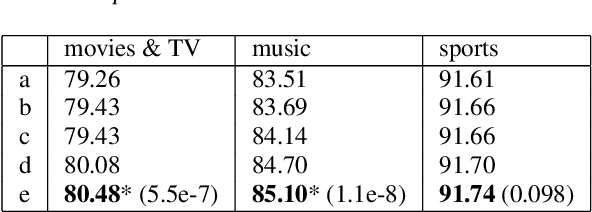
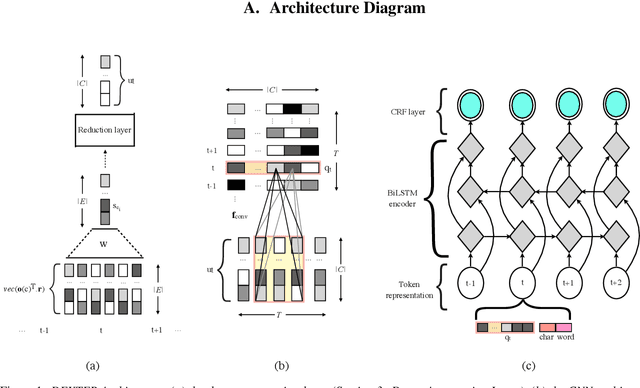
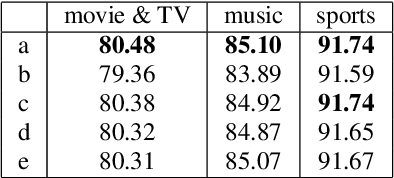
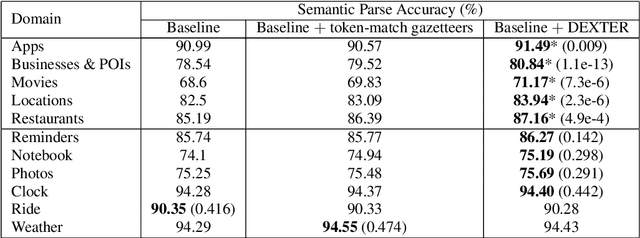
Named entity recognition (NER) is usually developed and tested on text from well-written sources. However, in intelligent voice assistants, where NER is an important component, input to NER may be noisy because of user or speech recognition error. In applications, entity labels may change frequently, and non-textual properties like topicality or popularity may be needed to choose among alternatives. We describe a NER system intended to address these problems. We test and train this system on a proprietary user-derived dataset. We compare with a baseline text-only NER system; the baseline enhanced with external gazetteers; and the baseline enhanced with the search and indirect labelling techniques we describe below. The final configuration gives around 6% reduction in NER error rate. We also show that this technique improves related tasks, such as semantic parsing, with an improvement of up to 5% in error rate.