 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing LLMs for Automated Privacy Policy Analysis: Prompt Engineering, Fine-Tuning and Explainability
Paper and Code
Mar 16, 2025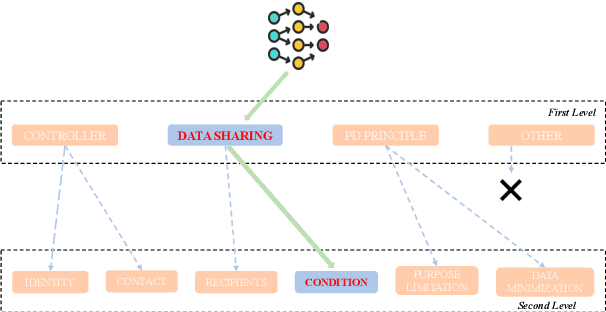
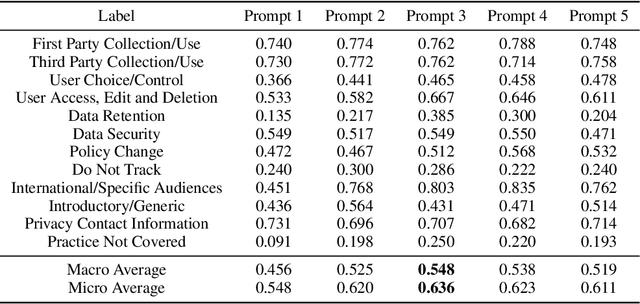
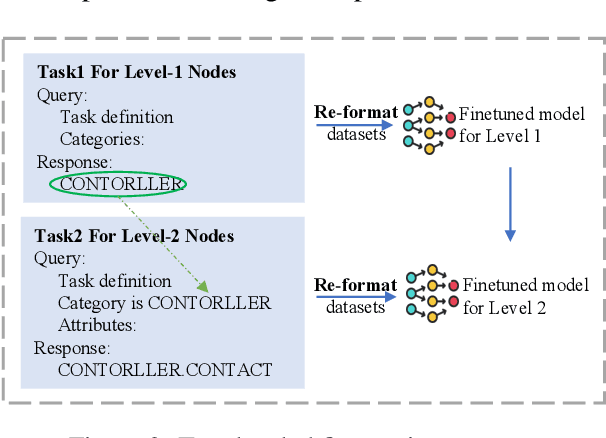
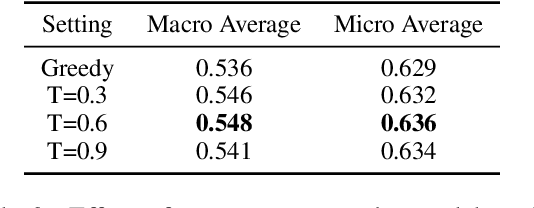
Privacy policies are widely used by digital services and often required for legal purposes. Many machine learning based classifiers have been developed to automate detection of different concepts in a given privacy policy, which can help facilitate other automated tasks such as producing a more reader-friendly summary and detecting legal compliance issues. Despite the successful applications of large language models (LLMs) to many NLP tasks in various domains, there is very little work studying the use of LLMs for automated privacy policy analysis, therefore, if and how LLMs can help automate privacy policy analysis remains under-explored. To fill this research gap, we conducted a comprehensive evaluation of LLM-based privacy policy concept classifiers, employing both prompt engineering and LoRA (low-rank adaptation) fine-tuning, on four state-of-the-art (SOTA) privacy policy corpora and taxonomies. Our experimental results demonstrated that combining prompt engineering and fine-tuning can make LLM-based classifiers outperform other SOTA methods, \emph{significantly} and \emph{consistently} across privacy policy corpora/taxonomies and concepts. Furthermore, we evaluated the explainability of the LLM-based classifiers using three metrics: completeness, logicality, and comprehensibility. For all three metrics, a score exceeding 91.1\% was observed in our evaluation, indicating that LLMs are not only useful to improve the classification performance, but also to enhance the explainability of detection results.