 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandomized algorithms and PAC bounds for inverse reinforcement learning in continuous spaces
May 24, 2024This work studies discrete-time discounted Markov decision processes with continuous state and action spaces and addresses the inverse problem of inferring a cost function from observed optimal behavior. We first consider the case in which we have access to the entire expert policy and characterize the set of solutions to the inverse problem by using occupation measures, linear duality, and complementary slackness conditions. To avoid trivial solutions and ill-posedness, we introduce a natural linear normalization constraint. This results in an infinite-dimensional linear feasibility problem, prompting a thorough analysis of its properties. Next, we use linear function approximators and adopt a randomized approach, namely the scenario approach and related probabilistic feasibility guarantees, to derive epsilon-optimal solutions for the inverse problem. We further discuss the sample complexity for a desired approximation accuracy. Finally, we deal with the more realistic case where we only have access to a finite set of expert demonstrations and a generative model and provide bounds on the error made when working with samples.
Regularized Q-learning through Robust Averaging
May 03, 2024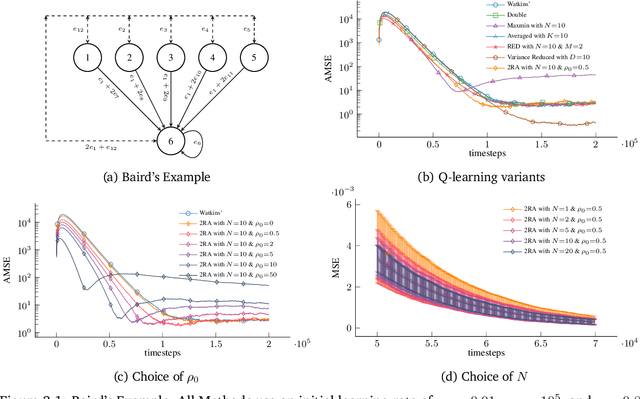
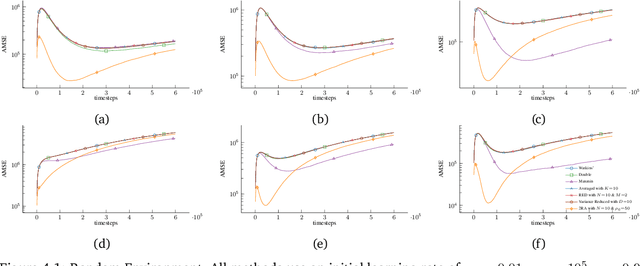
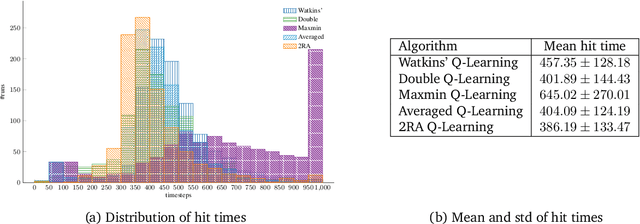
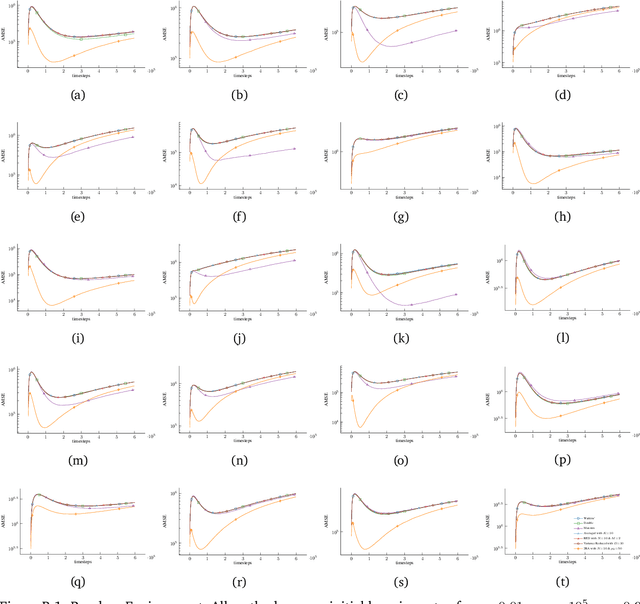
We propose a new Q-learning variant, called 2RA Q-learning, that addresses some weaknesses of existing Q-learning methods in a principled manner. One such weakness is an underlying estimation bias which cannot be controlled and often results in poor performance. We propose a distributionally robust estimator for the maximum expected value term, which allows us to precisely control the level of estimation bias introduced. The distributionally robust estimator admits a closed-form solution such that the proposed algorithm has a computational cost per iteration comparable to Watkins' Q-learning. For the tabular case, we show that 2RA Q-learning converges to the optimal policy and analyze its asymptotic mean-squared error. Lastly, we conduct numerical experiments for various settings, which corroborate our theoretical findings and indicate that 2RA Q-learning often performs better than existing methods.