 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayerFlow: Layer-wise Exploration of LLM Embeddings using Uncertainty-aware Interlinked Projections
Apr 09, 2025
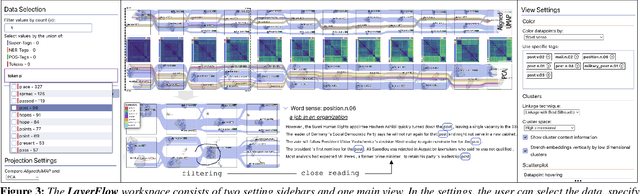

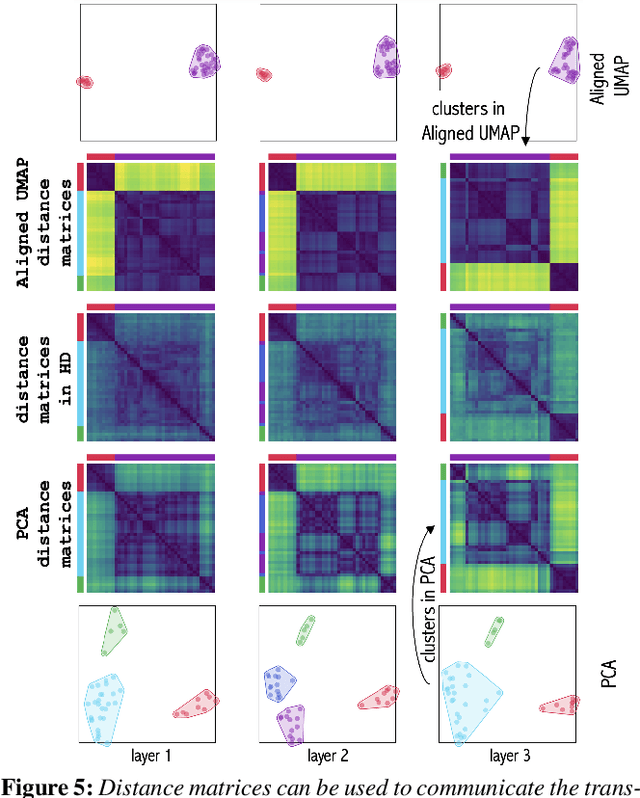
Large language models (LLMs) represent words through contextual word embeddings encoding different language properties like semantics and syntax. Understanding these properties is crucial, especially for researchers investigating language model capabilities, employing embeddings for tasks related to text similarity, or evaluating the reasons behind token importance as measured through attribution methods. Applications for embedding exploration frequently involve dimensionality reduction techniques, which reduce high-dimensional vectors to two dimensions used as coordinates in a scatterplot. This data transformation step introduces uncertainty that can be propagated to the visual representation and influence users' interpretation of the data. To communicate such uncertainties, we present LayerFlow - a visual analytics workspace that displays embeddings in an interlinked projection design and communicates the transformation, representation, and interpretation uncertainty. In particular, to hint at potential data distortions and uncertainties, the workspace includes several visual components, such as convex hulls showing 2D and HD clusters, data point pairwise distances, cluster summaries, and projection quality metrics. We show the usability of the presented workspace through replication and expert case studies that highlight the need to communicate uncertainty through multiple visual components and different data perspectives.
iNNspector: Visual, Interactive Deep Model Debugging
Jul 25, 2024Deep learning model design, development, and debugging is a process driven by best practices, guidelines, trial-and-error, and the personal experiences of model developers. At multiple stages of this process, performance and internal model data can be logged and made available. However, due to the sheer complexity and scale of this data and process, model developers often resort to evaluating their model performance based on abstract metrics like accuracy and loss. We argue that a structured analysis of data along the model's architecture and at multiple abstraction levels can considerably streamline the debugging process. Such a systematic analysis can further connect the developer's design choices to their impacts on the model behavior, facilitating the understanding, diagnosis, and refinement of deep learning models. Hence, in this paper, we (1) contribute a conceptual framework structuring the data space of deep learning experiments. Our framework, grounded in literature analysis and requirements interviews, captures design dimensions and proposes mechanisms to make this data explorable and tractable. To operationalize our framework in a ready-to-use application, we (2) present the iNNspector system. iNNspector enables tracking of deep learning experiments and provides interactive visualizations of the data on all levels of abstraction from multiple models to individual neurons. Finally, we (3) evaluate our approach with three real-world use-cases and a user study with deep learning developers and data analysts, proving its effectiveness and usability.
generAItor: Tree-in-the-Loop Text Generation for Language Model Explainability and Adaptation
Mar 12, 2024



Large language models (LLMs) are widely deployed in various downstream tasks, e.g., auto-completion, aided writing, or chat-based text generation. However, the considered output candidates of the underlying search algorithm are under-explored and under-explained. We tackle this shortcoming by proposing a tree-in-the-loop approach, where a visual representation of the beam search tree is the central component for analyzing, explaining, and adapting the generated outputs. To support these tasks, we present generAItor, a visual analytics technique, augmenting the central beam search tree with various task-specific widgets, providing targeted visualizations and interaction possibilities. Our approach allows interactions on multiple levels and offers an iterative pipeline that encompasses generating, exploring, and comparing output candidates, as well as fine-tuning the model based on adapted data. Our case study shows that our tool generates new insights in gender bias analysis beyond state-of-the-art template-based methods. Additionally, we demonstrate the applicability of our approach in a qualitative user study. Finally, we quantitatively evaluate the adaptability of the model to few samples, as occurring in text-generation use cases.
Revealing the Unwritten: Visual Investigation of Beam Search Trees to Address Language Model Prompting Challenges
Oct 17, 2023



The growing popularity of generative language models has amplified interest in interactive methods to guide model outputs. Prompt refinement is considered one of the most effective means to influence output among these methods. We identify several challenges associated with prompting large language models, categorized into data- and model-specific, linguistic, and socio-linguistic challenges. A comprehensive examination of model outputs, including runner-up candidates and their corresponding probabilities, is needed to address these issues. The beam search tree, the prevalent algorithm to sample model outputs, can inherently supply this information. Consequently, we introduce an interactive visual method for investigating the beam search tree, facilitating analysis of the decisions made by the model during generation. We quantitatively show the value of exposing the beam search tree and present five detailed analysis scenarios addressing the identified challenges. Our methodology validates existing results and offers additional insights.
explAIner: A Visual Analytics Framework for Interactive and Explainable Machine Learning
Jul 29, 2019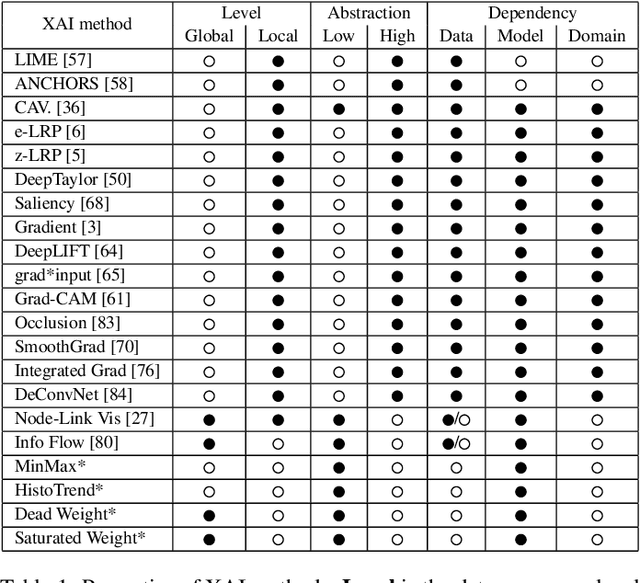
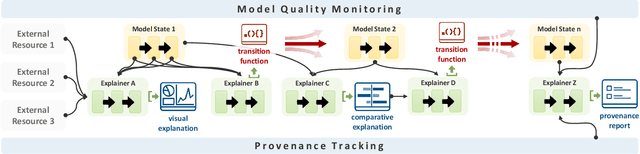
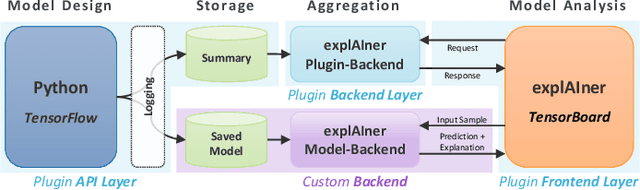
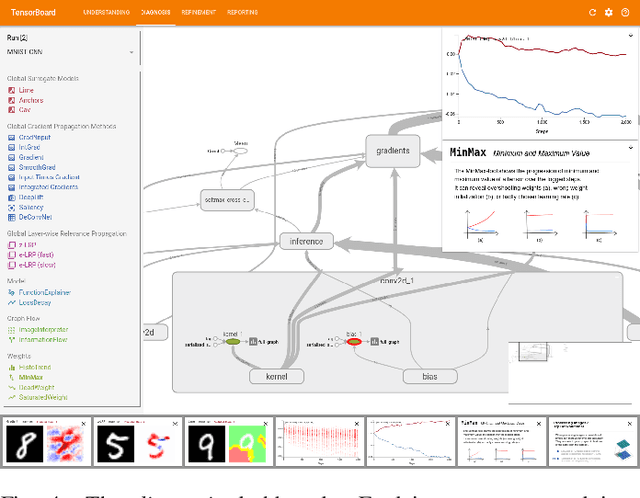
We propose a framework for interactive and explainable machine learning that enables users to (1) understand machine learning models; (2) diagnose model limitations using different explainable AI methods; as well as (3) refine and optimize the models. Our framework combines an iterative XAI pipeline with eight global monitoring and steering mechanisms, including quality monitoring, provenance tracking, model comparison, and trust building. To operationalize the framework, we present explAIner, a visual analytics system for interactive and explainable machine learning that instantiates all phases of the suggested pipeline within the commonly used TensorBoard environment. We performed a user-study with nine participants across different expertise levels to examine their perception of our workflow and to collect suggestions to fill the gap between our system and framework. The evaluation confirms that our tightly integrated system leads to an informed machine learning process while disclosing opportunities for further extensions.
Uncertainty-Aware Principal Component Analysis
May 03, 2019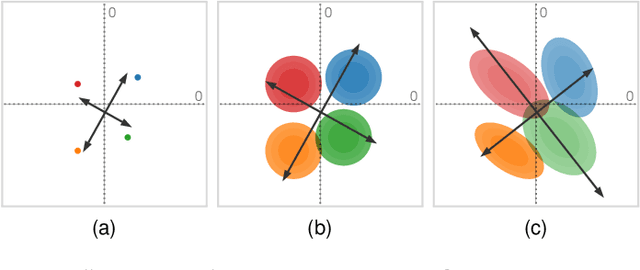
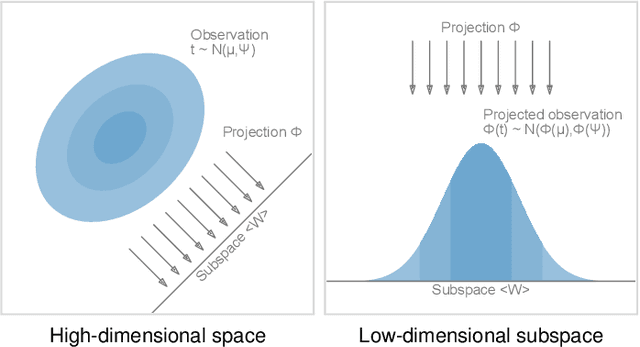
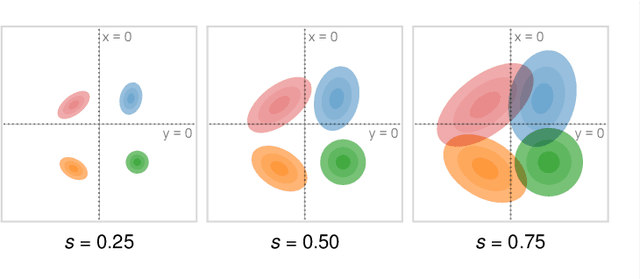
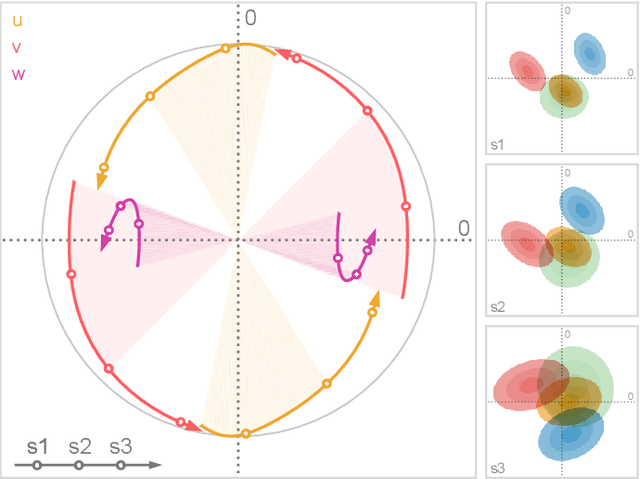
We present a technique to perform dimensionality reduction on data that is subject to uncertainty. Our method is a generalization of traditional principal component analysis (PCA) to multivariate probability distributions. In comparison to non-linear methods, linear dimensionality reduction techniques have the advantage that the characteristics of such probability distributions remain intact after projection. We derive a representation of the covariance matrix that respects potential uncertainty in each of the observations, building the mathematical foundation of our new method uncertainty-aware PCA. In addition to the accuracy and performance gained by our approach over sampling-based strategies, our formulation allows us to perform sensitivity analysis with regard to the uncertainty in the data. For this, we propose factor traces as a novel visualization that enables us to better understand the influence of uncertainty on the chosen principal components. We provide multiple examples of our technique using real-world datasets and show how to propagate multivariate normal distributions through PCA in closed-form. Furthermore, we discuss extensions and limitations of our approach.