 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Mapper: Charting LLM Embedding Spaces Using Perturbation-Based Explanation and Verification Agents
Jul 24, 2025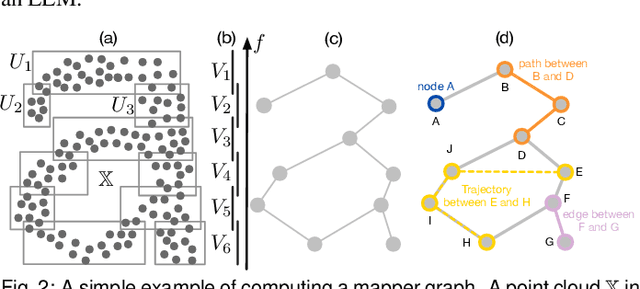
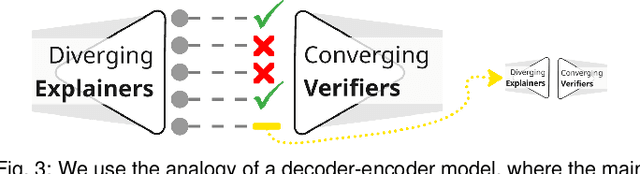
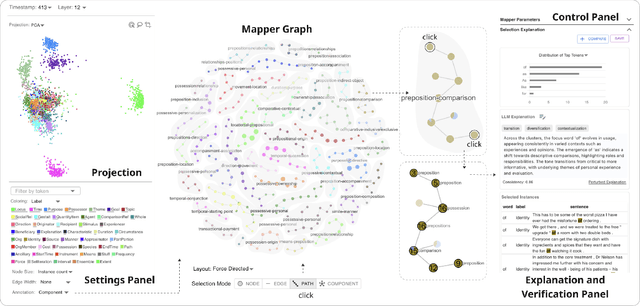
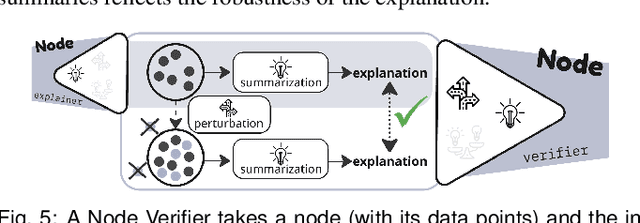
Large language models (LLMs) produce high-dimensional embeddings that capture rich semantic and syntactic relationships between words, sentences, and concepts. Investigating the topological structures of LLM embedding spaces via mapper graphs enables us to understand their underlying structures. Specifically, a mapper graph summarizes the topological structure of the embedding space, where each node represents a topological neighborhood (containing a cluster of embeddings), and an edge connects two nodes if their corresponding neighborhoods overlap. However, manually exploring these embedding spaces to uncover encoded linguistic properties requires considerable human effort. To address this challenge, we introduce a framework for semi-automatic annotation of these embedding properties. To organize the exploration process, we first define a taxonomy of explorable elements within a mapper graph such as nodes, edges, paths, components, and trajectories. The annotation of these elements is executed through two types of customizable LLM-based agents that employ perturbation techniques for scalable and automated analysis. These agents help to explore and explain the characteristics of mapper elements and verify the robustness of the generated explanations. We instantiate the framework within a visual analytics workspace and demonstrate its effectiveness through case studies. In particular, we replicate findings from prior research on BERT's embedding properties across various layers of its architecture and provide further observations into the linguistic properties of topological neighborhoods.
Concept-Level Explainability for Auditing & Steering LLM Responses
May 12, 2025As large language models (LLMs) become widely deployed, concerns about their safety and alignment grow. An approach to steer LLM behavior, such as mitigating biases or defending against jailbreaks, is to identify which parts of a prompt influence specific aspects of the model's output. Token-level attribution methods offer a promising solution, but still struggle in text generation, explaining the presence of each token in the output separately, rather than the underlying semantics of the entire LLM response. We introduce ConceptX, a model-agnostic, concept-level explainability method that identifies the concepts, i.e., semantically rich tokens in the prompt, and assigns them importance based on the outputs' semantic similarity. Unlike current token-level methods, ConceptX also offers to preserve context integrity through in-place token replacements and supports flexible explanation goals, e.g., gender bias. ConceptX enables both auditing, by uncovering sources of bias, and steering, by modifying prompts to shift the sentiment or reduce the harmfulness of LLM responses, without requiring retraining. Across three LLMs, ConceptX outperforms token-level methods like TokenSHAP in both faithfulness and human alignment. Steering tasks boost sentiment shift by 0.252 versus 0.131 for random edits and lower attack success rates from 0.463 to 0.242, outperforming attribution and paraphrasing baselines. While prompt engineering and self-explaining methods sometimes yield safer responses, ConceptX offers a transparent and faithful alternative for improving LLM safety and alignment, demonstrating the practical value of attribution-based explainability in guiding LLM behavior.
LayerFlow: Layer-wise Exploration of LLM Embeddings using Uncertainty-aware Interlinked Projections
Apr 09, 2025
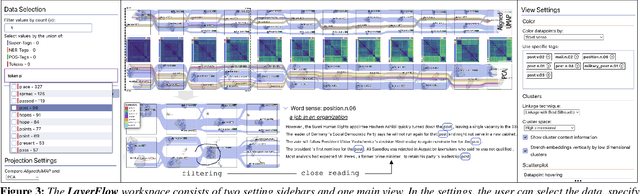

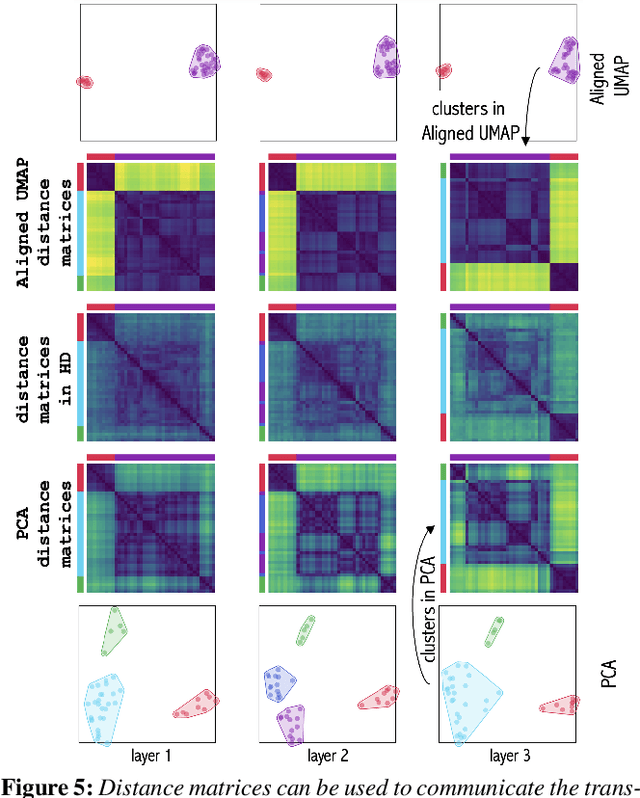
Large language models (LLMs) represent words through contextual word embeddings encoding different language properties like semantics and syntax. Understanding these properties is crucial, especially for researchers investigating language model capabilities, employing embeddings for tasks related to text similarity, or evaluating the reasons behind token importance as measured through attribution methods. Applications for embedding exploration frequently involve dimensionality reduction techniques, which reduce high-dimensional vectors to two dimensions used as coordinates in a scatterplot. This data transformation step introduces uncertainty that can be propagated to the visual representation and influence users' interpretation of the data. To communicate such uncertainties, we present LayerFlow - a visual analytics workspace that displays embeddings in an interlinked projection design and communicates the transformation, representation, and interpretation uncertainty. In particular, to hint at potential data distortions and uncertainties, the workspace includes several visual components, such as convex hulls showing 2D and HD clusters, data point pairwise distances, cluster summaries, and projection quality metrics. We show the usability of the presented workspace through replication and expert case studies that highlight the need to communicate uncertainty through multiple visual components and different data perspectives.
Feature Clock: High-Dimensional Effects in Two-Dimensional Plots
Aug 06, 2024



Humans struggle to perceive and interpret high-dimensional data. Therefore, high-dimensional data are often projected into two dimensions for visualization. Many applications benefit from complex nonlinear dimensionality reduction techniques, but the effects of individual high-dimensional features are hard to explain in the two-dimensional space. Most visualization solutions use multiple two-dimensional plots, each showing the effect of one high-dimensional feature in two dimensions; this approach creates a need for a visual inspection of k plots for a k-dimensional input space. Our solution, Feature Clock, provides a novel approach that eliminates the need to inspect these k plots to grasp the influence of original features on the data structure depicted in two dimensions. Feature Clock enhances the explainability and compactness of visualizations of embedded data and is available in an open-source Python library.
Challenges and Opportunities in Text Generation Explainability
May 14, 2024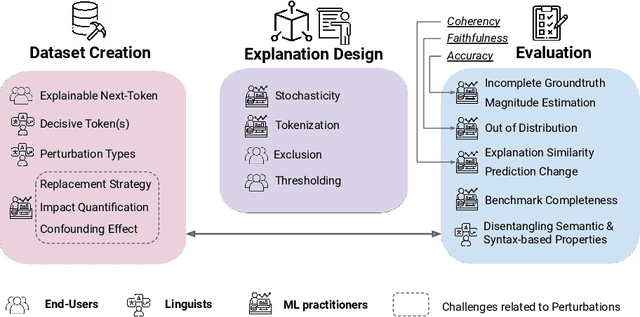
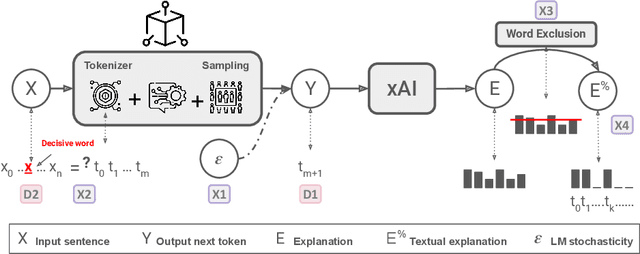
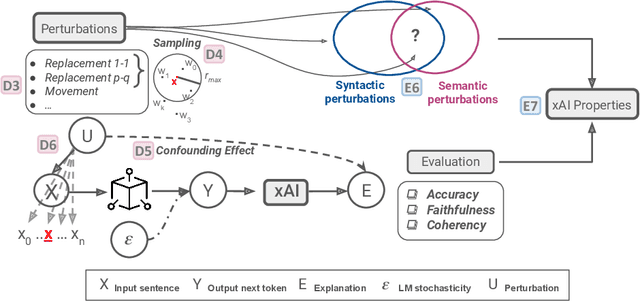
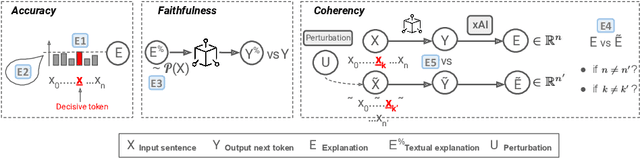
The necessity for interpretability in natural language processing (NLP) has risen alongside the growing prominence of large language models. Among the myriad tasks within NLP, text generation stands out as a primary objective of autoregressive models. The NLP community has begun to take a keen interest in gaining a deeper understanding of text generation, leading to the development of model-agnostic explainable artificial intelligence (xAI) methods tailored to this task. The design and evaluation of explainability methods are non-trivial since they depend on many factors involved in the text generation process, e.g., the autoregressive model and its stochastic nature. This paper outlines 17 challenges categorized into three groups that arise during the development and assessment of attribution-based explainability methods. These challenges encompass issues concerning tokenization, defining explanation similarity, determining token importance and prediction change metrics, the level of human intervention required, and the creation of suitable test datasets. The paper illustrates how these challenges can be intertwined, showcasing new opportunities for the community. These include developing probabilistic word-level explainability methods and engaging humans in the explainability pipeline, from the data design to the final evaluation, to draw robust conclusions on xAI methods.
generAItor: Tree-in-the-Loop Text Generation for Language Model Explainability and Adaptation
Mar 12, 2024



Large language models (LLMs) are widely deployed in various downstream tasks, e.g., auto-completion, aided writing, or chat-based text generation. However, the considered output candidates of the underlying search algorithm are under-explored and under-explained. We tackle this shortcoming by proposing a tree-in-the-loop approach, where a visual representation of the beam search tree is the central component for analyzing, explaining, and adapting the generated outputs. To support these tasks, we present generAItor, a visual analytics technique, augmenting the central beam search tree with various task-specific widgets, providing targeted visualizations and interaction possibilities. Our approach allows interactions on multiple levels and offers an iterative pipeline that encompasses generating, exploring, and comparing output candidates, as well as fine-tuning the model based on adapted data. Our case study shows that our tool generates new insights in gender bias analysis beyond state-of-the-art template-based methods. Additionally, we demonstrate the applicability of our approach in a qualitative user study. Finally, we quantitatively evaluate the adaptability of the model to few samples, as occurring in text-generation use cases.
SyntaxShap: Syntax-aware Explainability Method for Text Generation
Feb 14, 2024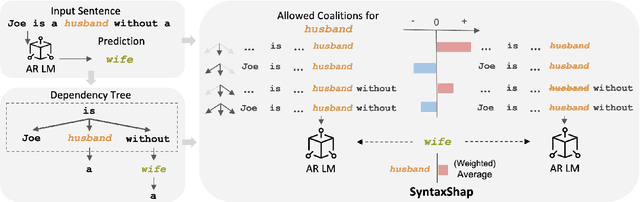
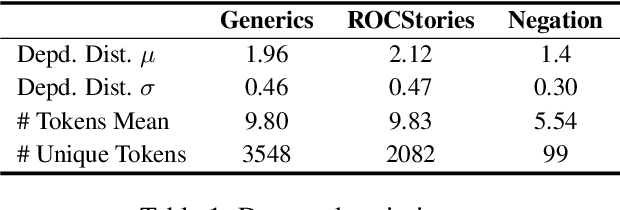

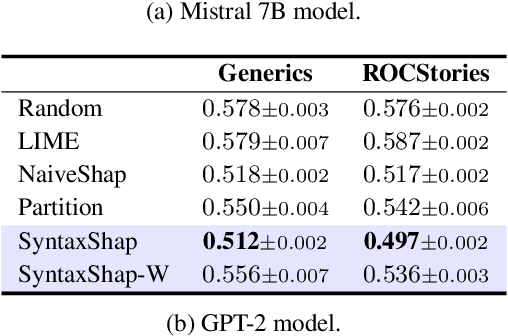
To harness the power of large language models in safety-critical domains we need to ensure the explainability of their predictions. However, despite the significant attention to model interpretability, there remains an unexplored domain in explaining sequence-to-sequence tasks using methods tailored for textual data. This paper introduces SyntaxShap, a local, model-agnostic explainability method for text generation that takes into consideration the syntax in the text data. The presented work extends Shapley values to account for parsing-based syntactic dependencies. Taking a game theoric approach, SyntaxShap only considers coalitions constraint by the dependency tree. We adopt a model-based evaluation to compare SyntaxShap and its weighted form to state-of-the-art explainability methods adapted to text generation tasks, using diverse metrics including faithfulness, complexity, coherency, and semantic alignment of the explanations to the model. We show that our syntax-aware method produces explanations that help build more faithful, coherent, and interpretable explanations for predictions by autoregressive models.
Revealing the Unwritten: Visual Investigation of Beam Search Trees to Address Language Model Prompting Challenges
Oct 17, 2023



The growing popularity of generative language models has amplified interest in interactive methods to guide model outputs. Prompt refinement is considered one of the most effective means to influence output among these methods. We identify several challenges associated with prompting large language models, categorized into data- and model-specific, linguistic, and socio-linguistic challenges. A comprehensive examination of model outputs, including runner-up candidates and their corresponding probabilities, is needed to address these issues. The beam search tree, the prevalent algorithm to sample model outputs, can inherently supply this information. Consequently, we introduce an interactive visual method for investigating the beam search tree, facilitating analysis of the decisions made by the model during generation. We quantitatively show the value of exposing the beam search tree and present five detailed analysis scenarios addressing the identified challenges. Our methodology validates existing results and offers additional insights.
Negation, Coordination, and Quantifiers in Contextualized Language Models
Sep 16, 2022
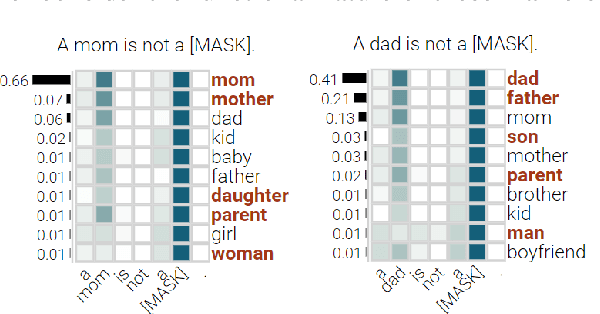
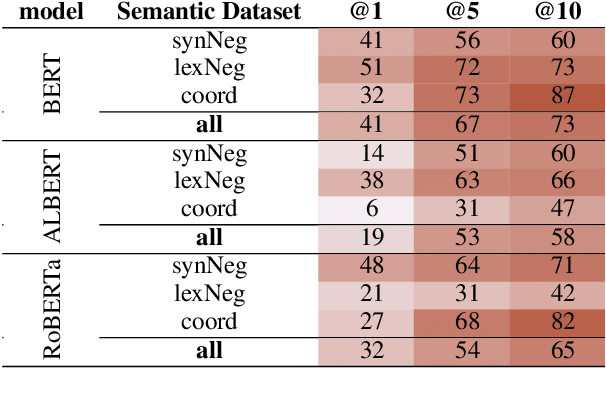
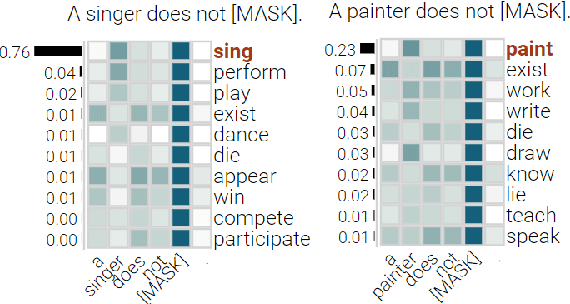
With the success of contextualized language models, much research explores what these models really learn and in which cases they still fail. Most of this work focuses on specific NLP tasks and on the learning outcome. Little research has attempted to decouple the models' weaknesses from specific tasks and focus on the embeddings per se and their mode of learning. In this paper, we take up this research opportunity: based on theoretical linguistic insights, we explore whether the semantic constraints of function words are learned and how the surrounding context impacts their embeddings. We create suitable datasets, provide new insights into the inner workings of LMs vis-a-vis function words and implement an assisting visual web interface for qualitative analysis.
Visual Comparison of Language Model Adaptation
Aug 17, 2022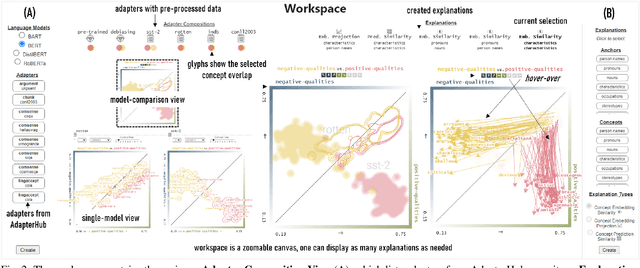
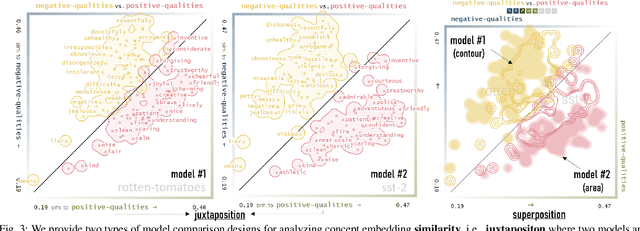
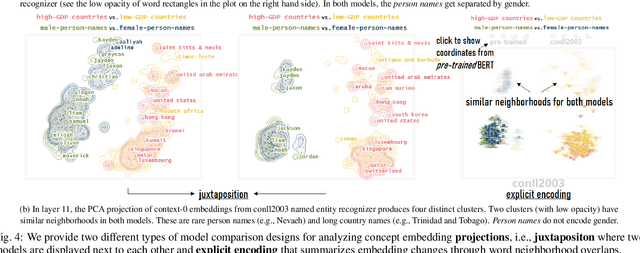
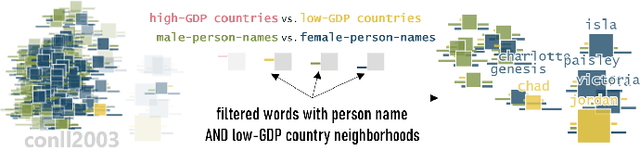
Neural language models are widely used; however, their model parameters often need to be adapted to the specific domains and tasks of an application, which is time- and resource-consuming. Thus, adapters have recently been introduced as a lightweight alternative for model adaptation. They consist of a small set of task-specific parameters with a reduced training time and simple parameter composition. The simplicity of adapter training and composition comes along with new challenges, such as maintaining an overview of adapter properties and effectively comparing their produced embedding spaces. To help developers overcome these challenges, we provide a twofold contribution. First, in close collaboration with NLP researchers, we conducted a requirement analysis for an approach supporting adapter evaluation and detected, among others, the need for both intrinsic (i.e., embedding similarity-based) and extrinsic (i.e., prediction-based) explanation methods. Second, motivated by the gathered requirements, we designed a flexible visual analytics workspace that enables the comparison of adapter properties. In this paper, we discuss several design iterations and alternatives for interactive, comparative visual explanation methods. Our comparative visualizations show the differences in the adapted embedding vectors and prediction outcomes for diverse human-interpretable concepts (e.g., person names, human qualities). We evaluate our workspace through case studies and show that, for instance, an adapter trained on the language debiasing task according to context-0 (decontextualized) embeddings introduces a new type of bias where words (even gender-independent words such as countries) become more similar to female than male pronouns. We demonstrate that these are artifacts of context-0 embeddings.