 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenges and Opportunities in Text Generation Explainability
Paper and Code
May 14, 2024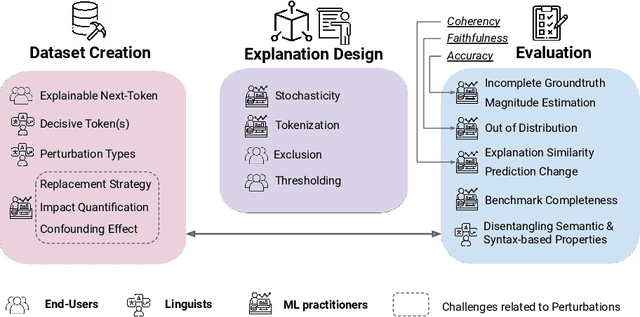
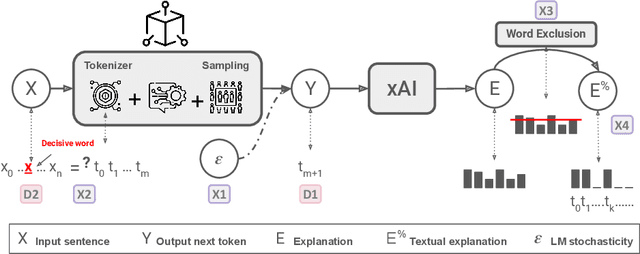
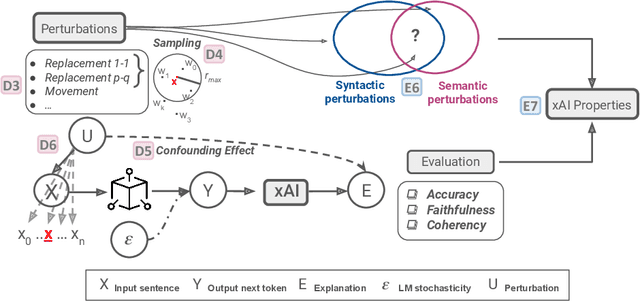
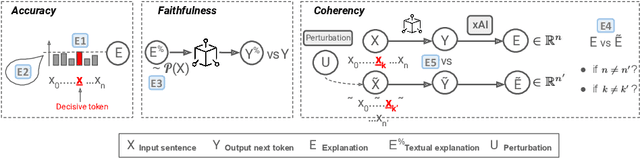
The necessity for interpretability in natural language processing (NLP) has risen alongside the growing prominence of large language models. Among the myriad tasks within NLP, text generation stands out as a primary objective of autoregressive models. The NLP community has begun to take a keen interest in gaining a deeper understanding of text generation, leading to the development of model-agnostic explainable artificial intelligence (xAI) methods tailored to this task. The design and evaluation of explainability methods are non-trivial since they depend on many factors involved in the text generation process, e.g., the autoregressive model and its stochastic nature. This paper outlines 17 challenges categorized into three groups that arise during the development and assessment of attribution-based explainability methods. These challenges encompass issues concerning tokenization, defining explanation similarity, determining token importance and prediction change metrics, the level of human intervention required, and the creation of suitable test datasets. The paper illustrates how these challenges can be intertwined, showcasing new opportunities for the community. These include developing probabilistic word-level explainability methods and engaging humans in the explainability pipeline, from the data design to the final evaluation, to draw robust conclusions on xAI methods.