 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcept-Level Explainability for Auditing & Steering LLM Responses
May 12, 2025As large language models (LLMs) become widely deployed, concerns about their safety and alignment grow. An approach to steer LLM behavior, such as mitigating biases or defending against jailbreaks, is to identify which parts of a prompt influence specific aspects of the model's output. Token-level attribution methods offer a promising solution, but still struggle in text generation, explaining the presence of each token in the output separately, rather than the underlying semantics of the entire LLM response. We introduce ConceptX, a model-agnostic, concept-level explainability method that identifies the concepts, i.e., semantically rich tokens in the prompt, and assigns them importance based on the outputs' semantic similarity. Unlike current token-level methods, ConceptX also offers to preserve context integrity through in-place token replacements and supports flexible explanation goals, e.g., gender bias. ConceptX enables both auditing, by uncovering sources of bias, and steering, by modifying prompts to shift the sentiment or reduce the harmfulness of LLM responses, without requiring retraining. Across three LLMs, ConceptX outperforms token-level methods like TokenSHAP in both faithfulness and human alignment. Steering tasks boost sentiment shift by 0.252 versus 0.131 for random edits and lower attack success rates from 0.463 to 0.242, outperforming attribution and paraphrasing baselines. While prompt engineering and self-explaining methods sometimes yield safer responses, ConceptX offers a transparent and faithful alternative for improving LLM safety and alignment, demonstrating the practical value of attribution-based explainability in guiding LLM behavior.
Why context matters in VQA and Reasoning: Semantic interventions for VLM input modalities
Oct 02, 2024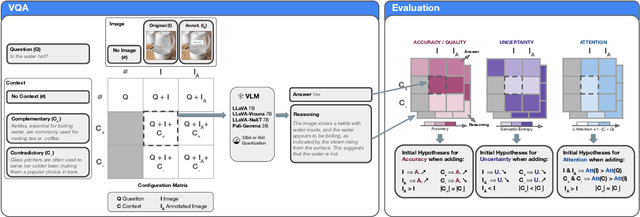

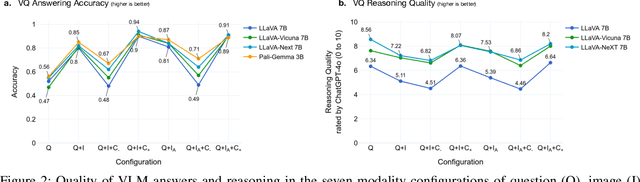
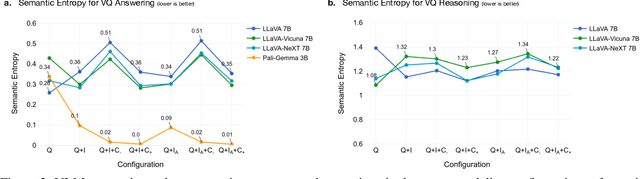
The various limitations of Generative AI, such as hallucinations and model failures, have made it crucial to understand the role of different modalities in Visual Language Model (VLM) predictions. Our work investigates how the integration of information from image and text modalities influences the performance and behavior of VLMs in visual question answering (VQA) and reasoning tasks. We measure this effect through answer accuracy, reasoning quality, model uncertainty, and modality relevance. We study the interplay between text and image modalities in different configurations where visual content is essential for solving the VQA task. Our contributions include (1) the Semantic Interventions (SI)-VQA dataset, (2) a benchmark study of various VLM architectures under different modality configurations, and (3) the Interactive Semantic Interventions (ISI) tool. The SI-VQA dataset serves as the foundation for the benchmark, while the ISI tool provides an interface to test and apply semantic interventions in image and text inputs, enabling more fine-grained analysis. Our results show that complementary information between modalities improves answer and reasoning quality, while contradictory information harms model performance and confidence. Image text annotations have minimal impact on accuracy and uncertainty, slightly increasing image relevance. Attention analysis confirms the dominant role of image inputs over text in VQA tasks. In this study, we evaluate state-of-the-art VLMs that allow us to extract attention coefficients for each modality. A key finding is PaliGemma's harmful overconfidence, which poses a higher risk of silent failures compared to the LLaVA models. This work sets the foundation for rigorous analysis of modality integration, supported by datasets specifically designed for this purpose.
Challenges and Opportunities in Text Generation Explainability
May 14, 2024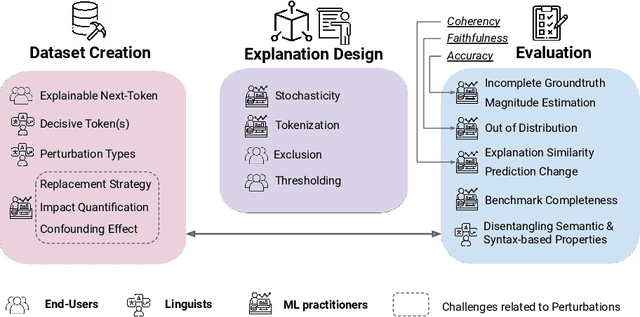
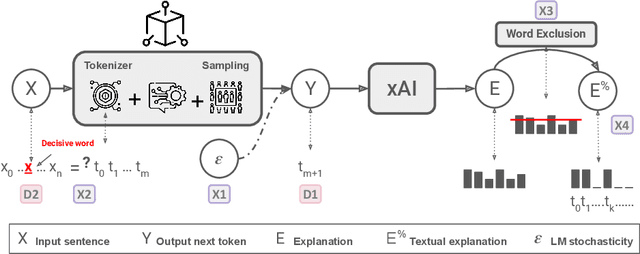
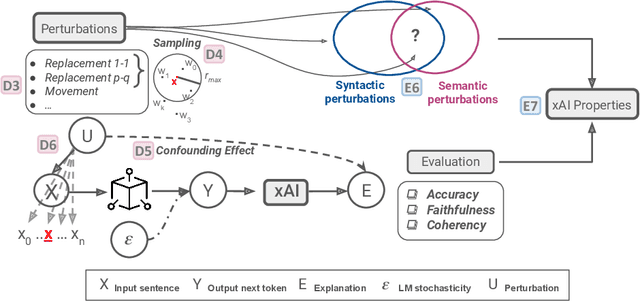
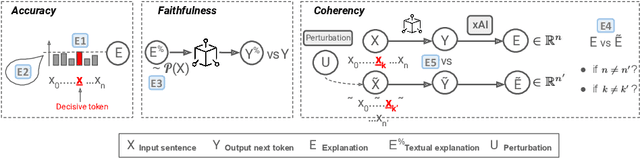
The necessity for interpretability in natural language processing (NLP) has risen alongside the growing prominence of large language models. Among the myriad tasks within NLP, text generation stands out as a primary objective of autoregressive models. The NLP community has begun to take a keen interest in gaining a deeper understanding of text generation, leading to the development of model-agnostic explainable artificial intelligence (xAI) methods tailored to this task. The design and evaluation of explainability methods are non-trivial since they depend on many factors involved in the text generation process, e.g., the autoregressive model and its stochastic nature. This paper outlines 17 challenges categorized into three groups that arise during the development and assessment of attribution-based explainability methods. These challenges encompass issues concerning tokenization, defining explanation similarity, determining token importance and prediction change metrics, the level of human intervention required, and the creation of suitable test datasets. The paper illustrates how these challenges can be intertwined, showcasing new opportunities for the community. These include developing probabilistic word-level explainability methods and engaging humans in the explainability pipeline, from the data design to the final evaluation, to draw robust conclusions on xAI methods.
SyntaxShap: Syntax-aware Explainability Method for Text Generation
Feb 14, 2024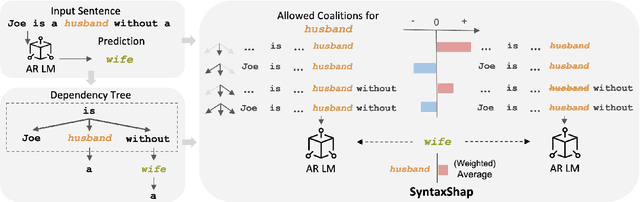
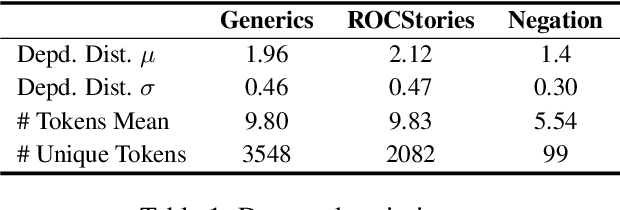

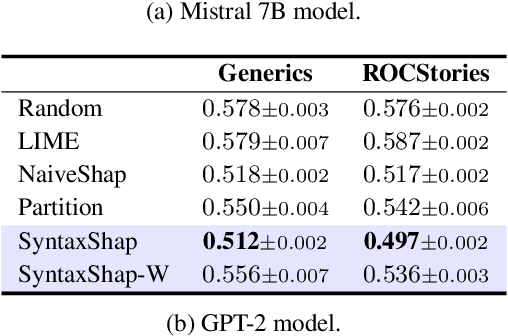
To harness the power of large language models in safety-critical domains we need to ensure the explainability of their predictions. However, despite the significant attention to model interpretability, there remains an unexplored domain in explaining sequence-to-sequence tasks using methods tailored for textual data. This paper introduces SyntaxShap, a local, model-agnostic explainability method for text generation that takes into consideration the syntax in the text data. The presented work extends Shapley values to account for parsing-based syntactic dependencies. Taking a game theoric approach, SyntaxShap only considers coalitions constraint by the dependency tree. We adopt a model-based evaluation to compare SyntaxShap and its weighted form to state-of-the-art explainability methods adapted to text generation tasks, using diverse metrics including faithfulness, complexity, coherency, and semantic alignment of the explanations to the model. We show that our syntax-aware method produces explanations that help build more faithful, coherent, and interpretable explanations for predictions by autoregressive models.
PowerGraph: A power grid benchmark dataset for graph neural networks
Feb 05, 2024



Public Graph Neural Networks (GNN) benchmark datasets facilitate the use of GNN and enhance GNN applicability to diverse disciplines. The community currently lacks public datasets of electrical power grids for GNN applications. Indeed, GNNs can potentially capture complex power grid phenomena over alternative machine learning techniques. Power grids are complex engineered networks that are naturally amenable to graph representations. Therefore, GNN have the potential for capturing the behavior of power grids over alternative machine learning techniques. To this aim, we develop a graph dataset for cascading failure events, which are the major cause of blackouts in electric power grids. Historical blackout datasets are scarce and incomplete. The assessment of vulnerability and the identification of critical components are usually conducted via computationally expensive offline simulations of cascading failures. Instead, we propose using machine learning models for the online detection of cascading failures leveraging the knowledge of the system state at the onset of the cascade. We develop PowerGraph, a graph dataset modeling cascading failures in power grids, designed for two purposes, namely, i) training GNN models for different graph-level tasks including multi-class classification, binary classification, and regression, and ii) explaining GNN models. The dataset generated via a physics-based cascading failure model ensures the generality of the operating and environmental conditions by spanning diverse failure scenarios. In addition, we foster the use of the dataset to benchmark GNN explainability methods by assigning ground-truth edge-level explanations. PowerGraph helps the development of better GNN models for graph-level tasks and explainability, critical in many domains ranging from chemistry to biology, where the systems and processes can be described as graphs.
Generative Explanations for Graph Neural Network: Methods and Evaluations
Nov 09, 2023

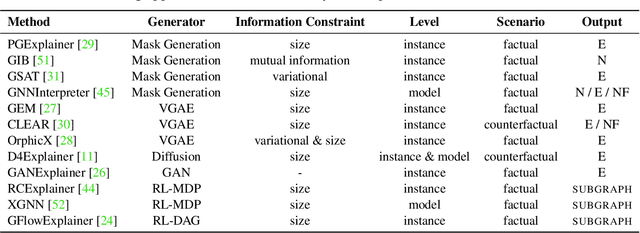

Graph Neural Networks (GNNs) achieve state-of-the-art performance in various graph-related tasks. However, the black-box nature often limits their interpretability and trustworthiness. Numerous explainability methods have been proposed to uncover the decision-making logic of GNNs, by generating underlying explanatory substructures. In this paper, we conduct a comprehensive review of the existing explanation methods for GNNs from the perspective of graph generation. Specifically, we propose a unified optimization objective for generative explanation methods, comprising two sub-objectives: Attribution and Information constraints. We further demonstrate their specific manifestations in various generative model architectures and different explanation scenarios. With the unified objective of the explanation problem, we reveal the shared characteristics and distinctions among current methods, laying the foundation for future methodological advancements. Empirical results demonstrate the advantages and limitations of different explainability approaches in terms of explanation performance, efficiency, and generalizability.
GInX-Eval: Towards In-Distribution Evaluation of Graph Neural Network Explanations
Sep 28, 2023Diverse explainability methods of graph neural networks (GNN) have recently been developed to highlight the edges and nodes in the graph that contribute the most to the model predictions. However, it is not clear yet how to evaluate the correctness of those explanations, whether it is from a human or a model perspective. One unaddressed bottleneck in the current evaluation procedure is the problem of out-of-distribution explanations, whose distribution differs from those of the training data. This important issue affects existing evaluation metrics such as the popular faithfulness or fidelity score. In this paper, we show the limitations of faithfulness metrics. We propose GInX-Eval (Graph In-distribution eXplanation Evaluation), an evaluation procedure of graph explanations that overcomes the pitfalls of faithfulness and offers new insights on explainability methods. Using a retraining strategy, the GInX score measures how informative removed edges are for the model and the EdgeRank score evaluates if explanatory edges are correctly ordered by their importance. GInX-Eval verifies if ground-truth explanations are instructive to the GNN model. In addition, it shows that many popular methods, including gradient-based methods, produce explanations that are not better than a random designation of edges as important subgraphs, challenging the findings of current works in the area. Results with GInX-Eval are consistent across multiple datasets and align with human evaluation.
GraphFramEx: Towards Systematic Evaluation of Explainability Methods for Graph Neural Networks
Jun 30, 2022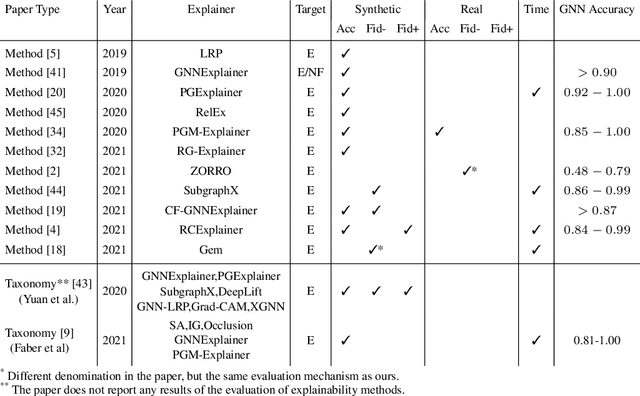
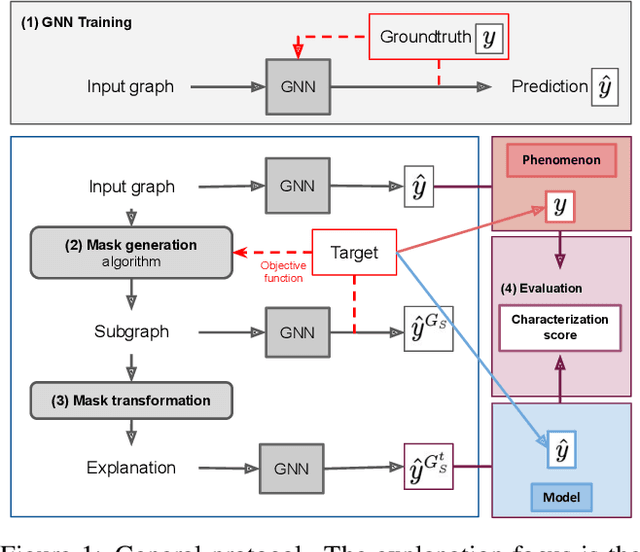
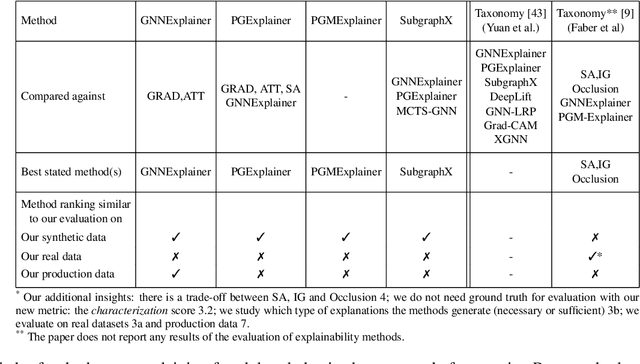
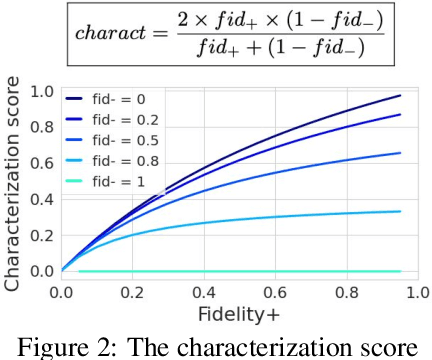
As one of the most popular machine learning models today, graph neural networks (GNNs) have attracted intense interest recently, and so does their explainability. Users are increasingly interested in a better understanding of GNN models and their outcomes. Unfortunately, today's evaluation frameworks for GNN explainability often rely on synthetic datasets, leading to conclusions of limited scope due to a lack of complexity in the problem instances. As GNN models are deployed to more mission-critical applications, we are in dire need for a common evaluation protocol of explainability methods of GNNs. In this paper, we propose, to our best knowledge, the first systematic evaluation framework for GNN explainability, considering explainability on three different "user needs:" explanation focus, mask nature, and mask transformation. We propose a unique metric that combines the fidelity measures and classify explanations based on their quality of being sufficient or necessary. We scope ourselves to node classification tasks and compare the most representative techniques in the field of input-level explainability for GNNs. For the widely used synthetic benchmarks, surprisingly shallow techniques such as personalized PageRank have the best performance for a minimum computation time. But when the graph structure is more complex and nodes have meaningful features, gradient-based methods, in particular Saliency, are the best according to our evaluation criteria. However, none dominates the others on all evaluation dimensions and there is always a trade-off. We further apply our evaluation protocol in a case study on eBay graphs to reflect the production environment.
ReforesTree: A Dataset for Estimating Tropical Forest Carbon Stock with Deep Learning and Aerial Imagery
Jan 26, 2022
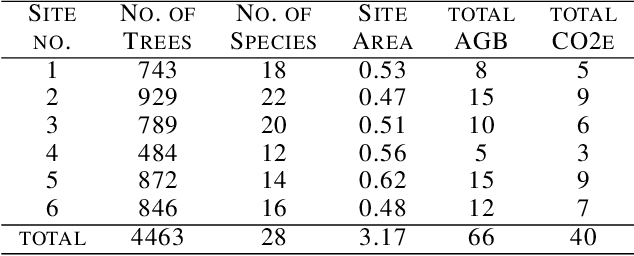
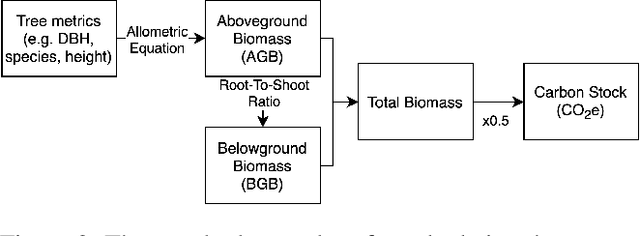
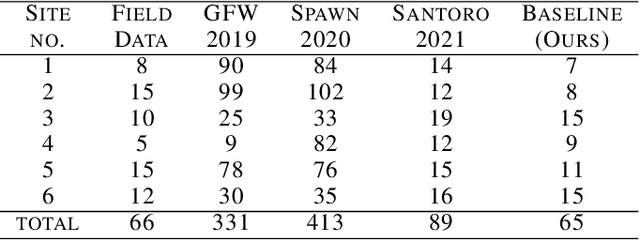
Forest biomass is a key influence for future climate, and the world urgently needs highly scalable financing schemes, such as carbon offsetting certifications, to protect and restore forests. Current manual forest carbon stock inventory methods of measuring single trees by hand are time, labour, and cost-intensive and have been shown to be subjective. They can lead to substantial overestimation of the carbon stock and ultimately distrust in forest financing. The potential for impact and scale of leveraging advancements in machine learning and remote sensing technologies is promising but needs to be of high quality in order to replace the current forest stock protocols for certifications. In this paper, we present ReforesTree, a benchmark dataset of forest carbon stock in six agro-forestry carbon offsetting sites in Ecuador. Furthermore, we show that a deep learning-based end-to-end model using individual tree detection from low cost RGB-only drone imagery is accurately estimating forest carbon stock within official carbon offsetting certification standards. Additionally, our baseline CNN model outperforms state-of-the-art satellite-based forest biomass and carbon stock estimates for this type of small-scale, tropical agro-forestry sites. We present this dataset to encourage machine learning research in this area to increase accountability and transparency of monitoring, verification and reporting (MVR) in carbon offsetting projects, as well as scaling global reforestation financing through accurate remote sensing.
Nearest neighbor search with compact codes: A decoder perspective
Dec 17, 2021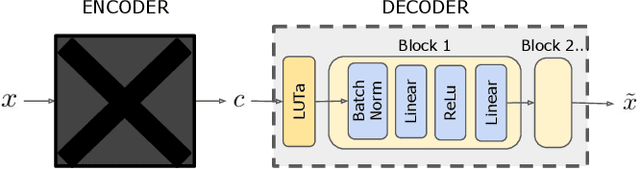
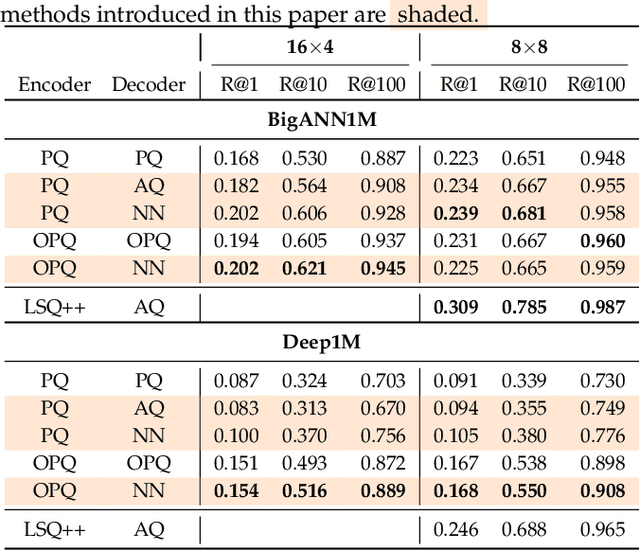
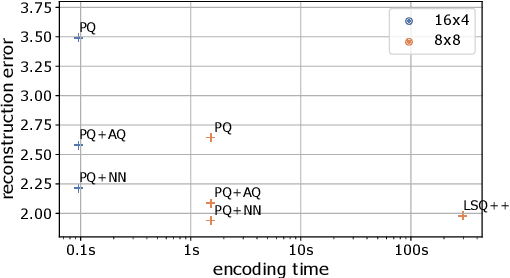
Modern approaches for fast retrieval of similar vectors on billion-scaled datasets rely on compressed-domain approaches such as binary sketches or product quantization. These methods minimize a certain loss, typically the mean squared error or other objective functions tailored to the retrieval problem. In this paper, we re-interpret popular methods such as binary hashing or product quantizers as auto-encoders, and point out that they implicitly make suboptimal assumptions on the form of the decoder. We design backward-compatible decoders that improve the reconstruction of the vectors from the same codes, which translates to a better performance in nearest neighbor search. Our method significantly improves over binary hashing methods or product quantization on popular benchmarks.