 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphFramEx: Towards Systematic Evaluation of Explainability Methods for Graph Neural Networks
Jun 30, 2022
As one of the most popular machine learning models today, graph neural networks (GNNs) have attracted intense interest recently, and so does their explainability. Users are increasingly interested in a better understanding of GNN models and their outcomes. Unfortunately, today's evaluation frameworks for GNN explainability often rely on synthetic datasets, leading to conclusions of limited scope due to a lack of complexity in the problem instances. As GNN models are deployed to more mission-critical applications, we are in dire need for a common evaluation protocol of explainability methods of GNNs. In this paper, we propose, to our best knowledge, the first systematic evaluation framework for GNN explainability, considering explainability on three different "user needs:" explanation focus, mask nature, and mask transformation. We propose a unique metric that combines the fidelity measures and classify explanations based on their quality of being sufficient or necessary. We scope ourselves to node classification tasks and compare the most representative techniques in the field of input-level explainability for GNNs. For the widely used synthetic benchmarks, surprisingly shallow techniques such as personalized PageRank have the best performance for a minimum computation time. But when the graph structure is more complex and nodes have meaningful features, gradient-based methods, in particular Saliency, are the best according to our evaluation criteria. However, none dominates the others on all evaluation dimensions and there is always a trade-off. We further apply our evaluation protocol in a case study on eBay graphs to reflect the production environment.
Stochastic Gradient Descent Works Really Well for Stress Minimization
Aug 24, 2020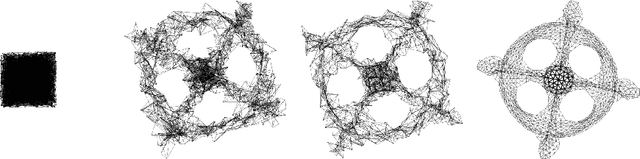
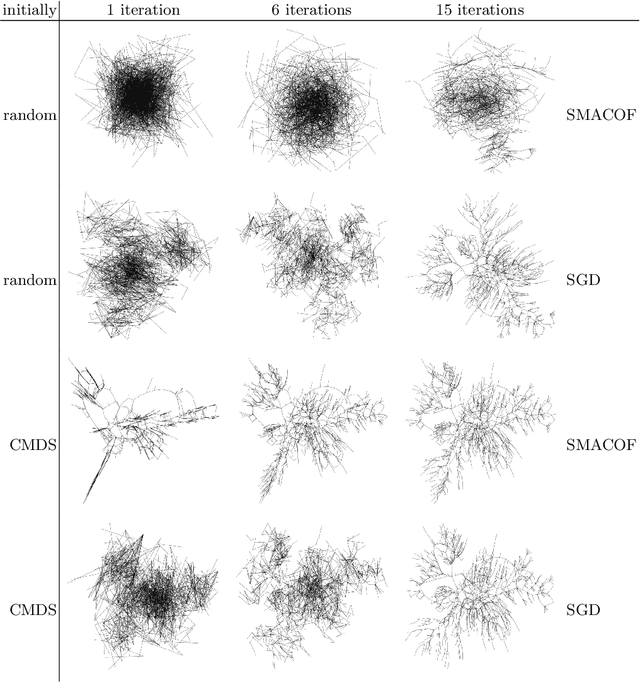
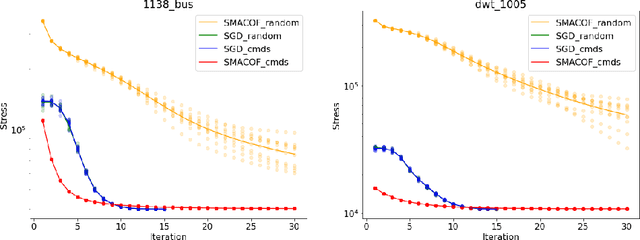
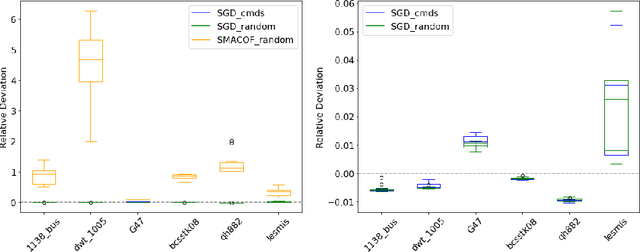
Stress minimization is among the best studied force-directed graph layout methods because it reliably yields high-quality layouts. It thus comes as a surprise that a novel approach based on stochastic gradient descent (Zheng, Pawar and Goodman, TVCG 2019) is claimed to improve on state-of-the-art approaches based on majorization. We present experimental evidence that the new approach does not actually yield better layouts, but that it is still to be preferred because it is simpler and robust against poor initialization.
Link Prediction with Social Vector Clocks
Apr 15, 2013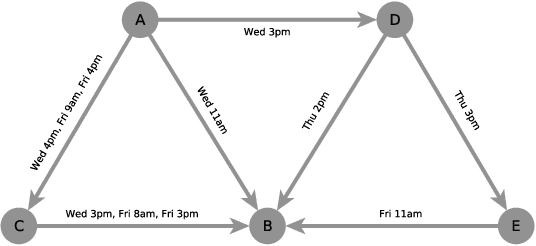
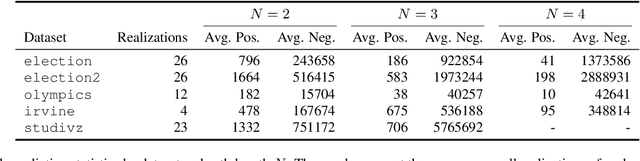
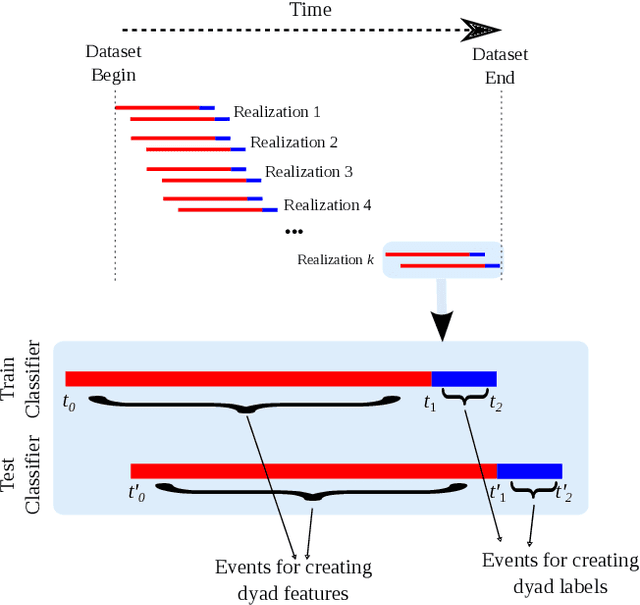
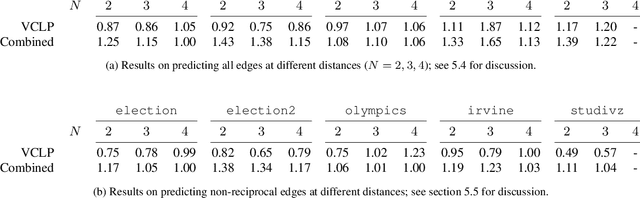
State-of-the-art link prediction utilizes combinations of complex features derived from network panel data. We here show that computationally less expensive features can achieve the same performance in the common scenario in which the data is available as a sequence of interactions. Our features are based on social vector clocks, an adaptation of the vector-clock concept introduced in distributed computing to social interaction networks. In fact, our experiments suggest that by taking into account the order and spacing of interactions, social vector clocks exploit different aspects of link formation so that their combination with previous approaches yields the most accurate predictor to date.