 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Tunable Parameters State-Dependent in Weather and Climate Models with Reinforcement Learning
Jan 07, 2026Weather and climate models rely on parametrisations to represent unresolved sub-grid processes. Traditional schemes rely on fixed coefficients that are weakly constrained and tuned offline, contributing to persistent biases that limit their ability to adapt to the underlying physics. This study presents a framework that learns components of parametrisation schemes online as a function of the evolving model state using reinforcement learning (RL) and evaluates the resulting RL-driven parameter updates across a hierarchy of idealised testbeds spanning a simple climate bias correction (SCBC), a radiative-convective equilibrium (RCE), and a zonal mean energy balance model (EBM) with both single-agent and federated multi-agent settings. Across nine RL algorithms, Truncated Quantile Critics (TQC), Deep Deterministic Policy Gradient (DDPG), and Twin Delayed DDPG (TD3) achieved the highest skill and the most stable convergence across configurations, with performance assessed against a static baseline using area-weighted RMSE, temperature profile and pressure-level diagnostics. For the EBM, single-agent RL outperformed static parameter tuning with the strongest gains in tropical and mid-latitude bands, while federated RL on multi-agent setups enabled geographically specialised control and faster convergence, with a six-agent DDPG configuration using frequent aggregation yielding the lowest area-weighted RMSE across the tropics and mid-latitudes. The learnt corrections were also physically meaningful as agents modulated EBM radiative parameters to reduce meridional biases, adjusted RCE lapse rates to match vertical temperature errors, and stabilised SCBC heating increments to limit drift. Overall, results highlight RL to deliver skilful state-dependent, and regime-aware parametrisations, offering a scalable pathway for online learning within numerical models.
FedRAIN-Lite: Federated Reinforcement Algorithms for Improving Idealised Numerical Weather and Climate Models
Aug 19, 2025Sub-grid parameterisations in climate models are traditionally static and tuned offline, limiting adaptability to evolving states. This work introduces FedRAIN-Lite, a federated reinforcement learning (FedRL) framework that mirrors the spatial decomposition used in general circulation models (GCMs) by assigning agents to latitude bands, enabling local parameter learning with periodic global aggregation. Using a hierarchy of simplified energy-balance climate models, from a single-agent baseline (ebm-v1) to multi-agent ensemble (ebm-v2) and GCM-like (ebm-v3) setups, we benchmark three RL algorithms under different FedRL configurations. Results show that Deep Deterministic Policy Gradient (DDPG) consistently outperforms both static and single-agent baselines, with faster convergence and lower area-weighted RMSE in tropical and mid-latitude zones across both ebm-v2 and ebm-v3 setups. DDPG's ability to transfer across hyperparameters and low computational cost make it well-suited for geographically adaptive parameter learning. This capability offers a scalable pathway towards high-complexity GCMs and provides a prototype for physically aligned, online-learning climate models that can evolve with a changing climate. Code accessible at https://github.com/p3jitnath/climate-rl-fedrl.
Finetuning a Weather Foundation Model with Lightweight Decoders for Unseen Physical Processes
Jun 23, 2025Recent advances in AI weather forecasting have led to the emergence of so-called "foundation models", typically defined by expensive pretraining and minimal fine-tuning for downstream tasks. However, in the natural sciences, a desirable foundation model should also encode meaningful statistical relationships between the underlying physical variables. This study evaluates the performance of the state-of-the-art Aurora foundation model in predicting hydrological variables, which were not considered during pretraining. We introduce a lightweight approach using shallow decoders trained on the latent representations of the pretrained model to predict these new variables. As a baseline, we compare this to fine-tuning the full model, which allows further optimization of the latent space while incorporating new variables into both inputs and outputs. The decoder-based approach requires 50% less training time and 35% less memory, while achieving strong accuracy across various hydrological variables and preserving desirable properties of the foundation model, such as autoregressive stability. Notably, decoder accuracy depends on the physical correlation between the new variables and those used during pretraining, indicating that Aurora's latent space captures meaningful physical relationships. In this sense, we argue that an important quality metric for foundation models in Earth sciences is their ability to be extended to new variables without a full fine-tuning. This provides a new perspective for making foundation models more accessible to communities with limited computational resources, while supporting broader adoption in Earth sciences.
Building Machine Learning Limited Area Models: Kilometer-Scale Weather Forecasting in Realistic Settings
Apr 12, 2025



Machine learning is revolutionizing global weather forecasting, with models that efficiently produce highly accurate forecasts. Apart from global forecasting there is also a large value in high-resolution regional weather forecasts, focusing on accurate simulations of the atmosphere for a limited area. Initial attempts have been made to use machine learning for such limited area scenarios, but these experiments do not consider realistic forecasting settings and do not investigate the many design choices involved. We present a framework for building kilometer-scale machine learning limited area models with boundary conditions imposed through a flexible boundary forcing method. This enables boundary conditions defined either from reanalysis or operational forecast data. Our approach employs specialized graph constructions with rectangular and triangular meshes, along with multi-step rollout training strategies to improve temporal consistency. We perform systematic evaluation of different design choices, including the boundary width, graph construction and boundary forcing integration. Models are evaluated across both a Danish and a Swiss domain, two regions that exhibit different orographical characteristics. Verification is performed against both gridded analysis data and in-situ observations, including a case study for the storm Ciara in February 2020. Both models achieve skillful predictions across a wide range of variables, with our Swiss model outperforming the numerical weather prediction baseline for key surface variables. With their substantially lower computational cost, our findings demonstrate great potential for machine learning limited area models in the future of regional weather forecasting.
GraphFramEx: Towards Systematic Evaluation of Explainability Methods for Graph Neural Networks
Jun 30, 2022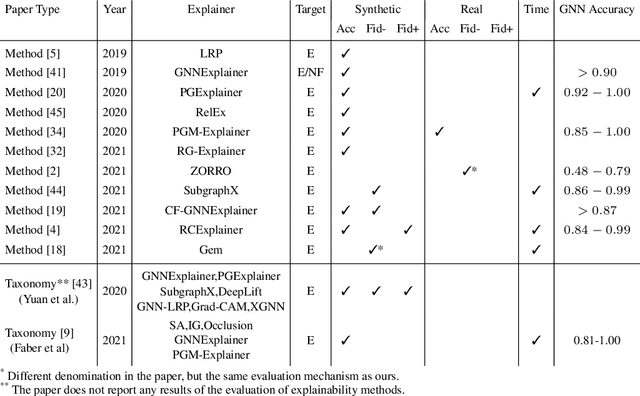
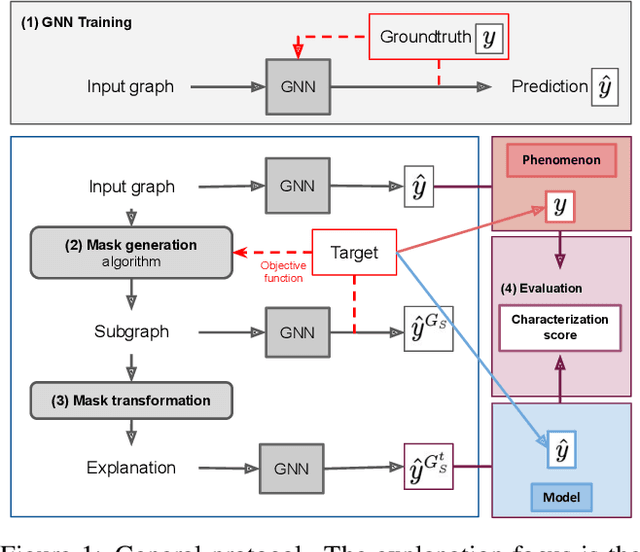
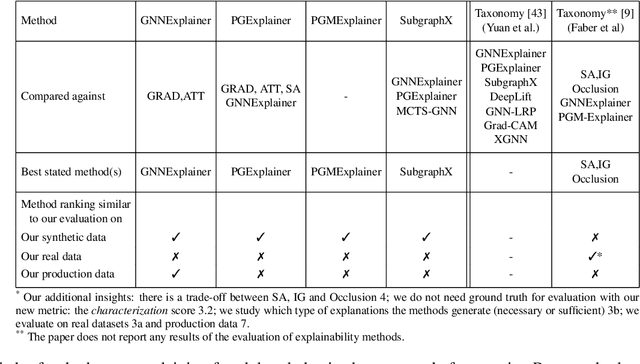
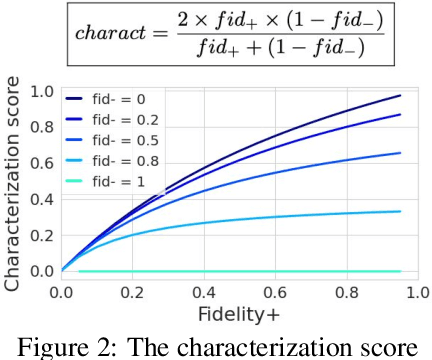
As one of the most popular machine learning models today, graph neural networks (GNNs) have attracted intense interest recently, and so does their explainability. Users are increasingly interested in a better understanding of GNN models and their outcomes. Unfortunately, today's evaluation frameworks for GNN explainability often rely on synthetic datasets, leading to conclusions of limited scope due to a lack of complexity in the problem instances. As GNN models are deployed to more mission-critical applications, we are in dire need for a common evaluation protocol of explainability methods of GNNs. In this paper, we propose, to our best knowledge, the first systematic evaluation framework for GNN explainability, considering explainability on three different "user needs:" explanation focus, mask nature, and mask transformation. We propose a unique metric that combines the fidelity measures and classify explanations based on their quality of being sufficient or necessary. We scope ourselves to node classification tasks and compare the most representative techniques in the field of input-level explainability for GNNs. For the widely used synthetic benchmarks, surprisingly shallow techniques such as personalized PageRank have the best performance for a minimum computation time. But when the graph structure is more complex and nodes have meaningful features, gradient-based methods, in particular Saliency, are the best according to our evaluation criteria. However, none dominates the others on all evaluation dimensions and there is always a trade-off. We further apply our evaluation protocol in a case study on eBay graphs to reflect the production environment.