 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Machine Learning Limited Area Models: Kilometer-Scale Weather Forecasting in Realistic Settings
Apr 12, 2025



Machine learning is revolutionizing global weather forecasting, with models that efficiently produce highly accurate forecasts. Apart from global forecasting there is also a large value in high-resolution regional weather forecasts, focusing on accurate simulations of the atmosphere for a limited area. Initial attempts have been made to use machine learning for such limited area scenarios, but these experiments do not consider realistic forecasting settings and do not investigate the many design choices involved. We present a framework for building kilometer-scale machine learning limited area models with boundary conditions imposed through a flexible boundary forcing method. This enables boundary conditions defined either from reanalysis or operational forecast data. Our approach employs specialized graph constructions with rectangular and triangular meshes, along with multi-step rollout training strategies to improve temporal consistency. We perform systematic evaluation of different design choices, including the boundary width, graph construction and boundary forcing integration. Models are evaluated across both a Danish and a Swiss domain, two regions that exhibit different orographical characteristics. Verification is performed against both gridded analysis data and in-situ observations, including a case study for the storm Ciara in February 2020. Both models achieve skillful predictions across a wide range of variables, with our Swiss model outperforming the numerical weather prediction baseline for key surface variables. With their substantially lower computational cost, our findings demonstrate great potential for machine learning limited area models in the future of regional weather forecasting.
Multi-field Visualization: Trait design and trait-induced merge trees
Jan 08, 2025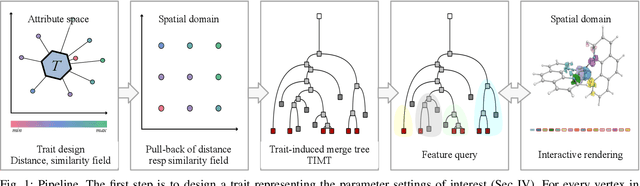
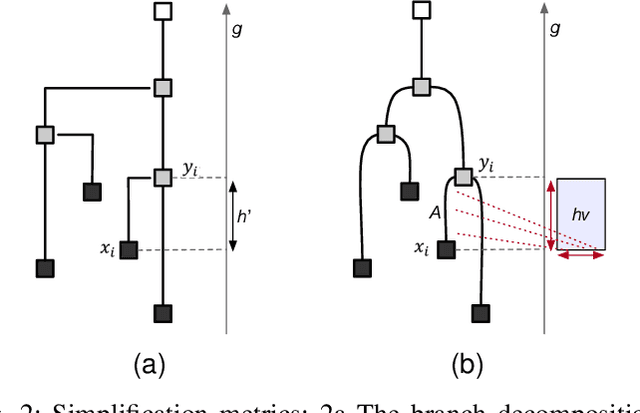
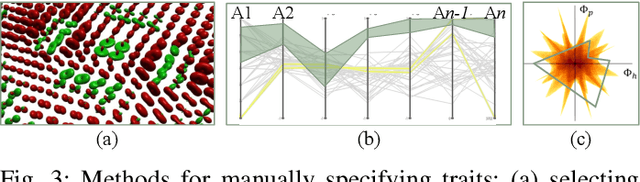
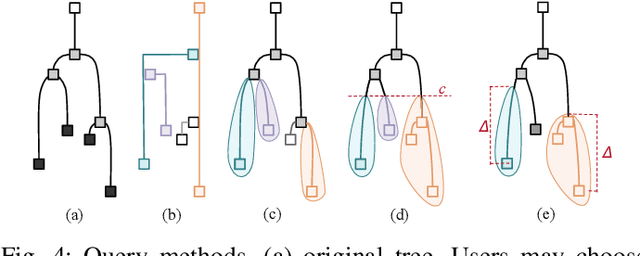
Feature level sets (FLS) have shown significant potential in the analysis of multi-field data by using traits defined in attribute space to specify features in the domain. In this work, we address key challenges in the practical use of FLS: trait design and feature selection for rendering. To simplify trait design, we propose a Cartesian decomposition of traits into simpler components, making the process more intuitive and computationally efficient. Additionally, we utilize dictionary learning results to automatically suggest point traits. To enhance feature selection, we introduce trait-induced merge trees (TIMTs), a generalization of merge trees for feature level sets, aimed at topologically analyzing tensor fields or general multi-variate data. The leaves in the TIMT represent areas in the input data that are closest to the defined trait, thereby most closely resembling the defined feature. This merge tree provides a hierarchy of features, enabling the querying of the most relevant and persistent features. Our method includes various query techniques for the tree, allowing the highlighting of different aspects. We demonstrate the cross-application capabilities of this approach through five case studies from different domains.