 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Event Visual Odometry
Dec 15, 2023



Event cameras offer the exciting possibility of tracking the camera's pose during high-speed motion and in adverse lighting conditions. Despite this promise, existing event-based monocular visual odometry (VO) approaches demonstrate limited performance on recent benchmarks. To address this limitation, some methods resort to additional sensors such as IMUs, stereo event cameras, or frame-based cameras. Nonetheless, these additional sensors limit the application of event cameras in real-world devices since they increase cost and complicate system requirements. Moreover, relying on a frame-based camera makes the system susceptible to motion blur and HDR. To remove the dependency on additional sensors and to push the limits of using only a single event camera, we present Deep Event VO (DEVO), the first monocular event-only system with strong performance on a large number of real-world benchmarks. DEVO sparsely tracks selected event patches over time. A key component of DEVO is a novel deep patch selection mechanism tailored to event data. We significantly decrease the pose tracking error on seven real-world benchmarks by up to 97% compared to event-only methods and often surpass or are close to stereo or inertial methods. Code is available at https://github.com/tum-vision/DEVO
Masked Event Modeling: Self-Supervised Pretraining for Event Cameras
Dec 20, 2022Event cameras offer the capacity to asynchronously capture brightness changes with low latency, high temporal resolution, and high dynamic range. Deploying deep learning methods for classification or other tasks to these sensors typically requires large labeled datasets. Since the amount of labeled event data is tiny compared to the bulk of labeled RGB imagery, the progress of event-based vision has remained limited. To reduce the dependency on labeled event data, we introduce Masked Event Modeling (MEM), a self-supervised pretraining framework for events. Our method pretrains a neural network on unlabeled events, which can originate from any event camera recording. Subsequently, the pretrained model is finetuned on a downstream task leading to an overall better performance while requiring fewer labels. Our method outperforms the state-of-the-art on N-ImageNet, N-Cars, and N-Caltech101, increasing the object classification accuracy on N-ImageNet by 7.96%. We demonstrate that Masked Event Modeling is superior to RGB-based pretraining on a real world dataset.
E-NeRF: Neural Radiance Fields from a Moving Event Camera
Aug 24, 2022
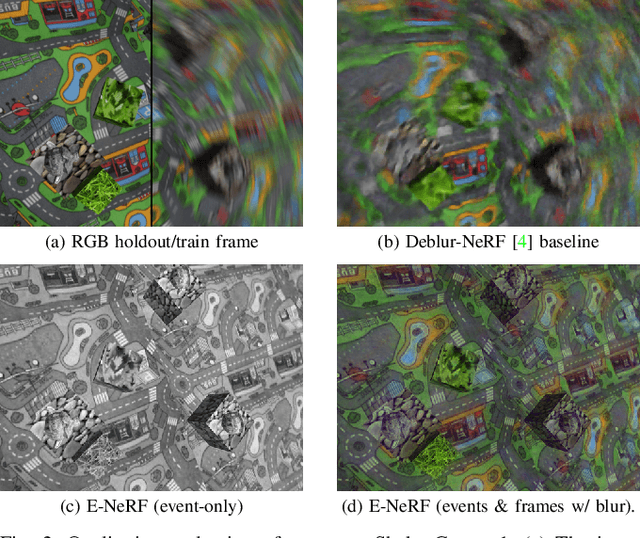


Estimating neural radiance fields (NeRFs) from ideal images has been extensively studied in the computer vision community. Most approaches assume optimal illumination and slow camera motion. These assumptions are often violated in robotic applications, where images contain motion blur and the scene may not have suitable illumination. This can cause significant problems for downstream tasks such as navigation, inspection or visualization of the scene. To alleviate these problems we present E-NeRF, the first method which estimates a volumetric scene representation in the form of a NeRF from a fast-moving event camera. Our method can recover NeRFs during very fast motion and in high dynamic range conditions, where frame-based approaches fail. We show that rendering high-quality frames is possible by only providing an event stream as input. Furthermore, by combining events and frames, we can estimate NeRFs of higher quality than state-of-the-art approaches under severe motion blur. We also show that combining events and frames can overcome failure cases of NeRF estimation in scenarios where only few input views are available, without requiring additional regularization.
TUM-VIE: The TUM Stereo Visual-Inertial Event Dataset
Aug 16, 2021
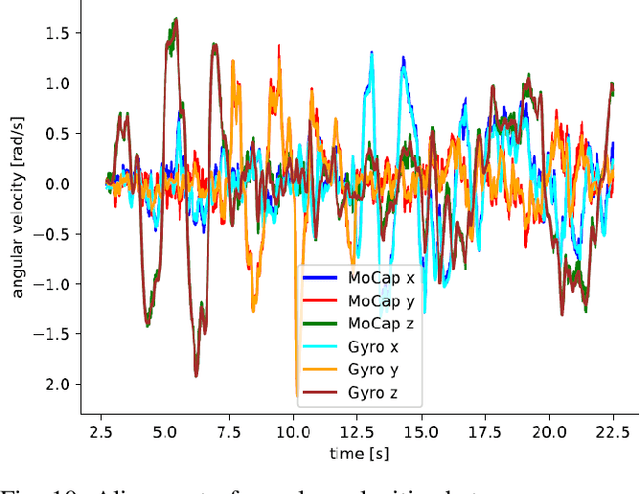
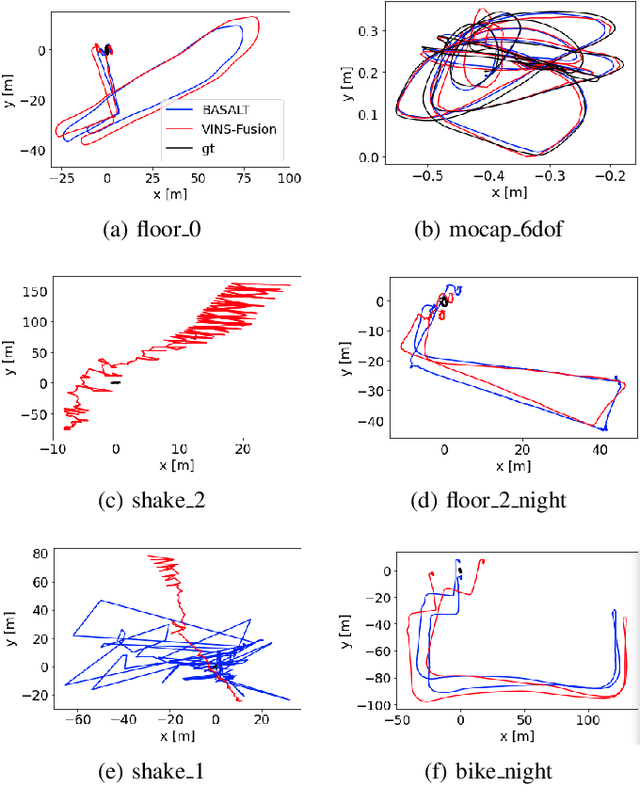

Event cameras are bio-inspired vision sensors which measure per pixel brightness changes. They offer numerous benefits over traditional, frame-based cameras, including low latency, high dynamic range, high temporal resolution and low power consumption. Thus, these sensors are suited for robotics and virtual reality applications. To foster the development of 3D perception and navigation algorithms with event cameras, we present the TUM-VIE dataset. It consists of a large variety of handheld and head-mounted sequences in indoor and outdoor environments, including rapid motion during sports and high dynamic range scenarios. The dataset contains stereo event data, stereo grayscale frames at 20Hz as well as IMU data at 200Hz. Timestamps between all sensors are synchronized in hardware. The event cameras contain a large sensor of 1280x720 pixels, which is significantly larger than the sensors used in existing stereo event datasets (at least by a factor of ten). We provide ground truth poses from a motion capture system at 120Hz during the beginning and end of each sequence, which can be used for trajectory evaluation. TUM-VIE includes challenging sequences where state-of-the art visual SLAM algorithms either fail or result in large drift. Hence, our dataset can help to push the boundary of future research on event-based visual-inertial perception algorithms.
Event-Based Feature Tracking in Continuous Time with Sliding Window Optimization
Jul 09, 2021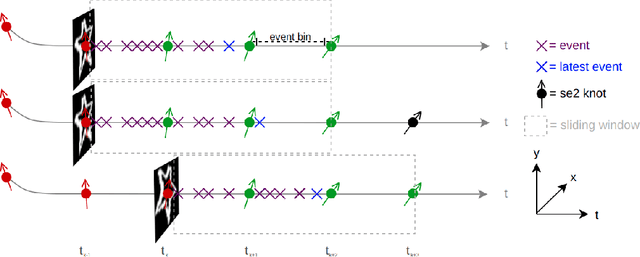
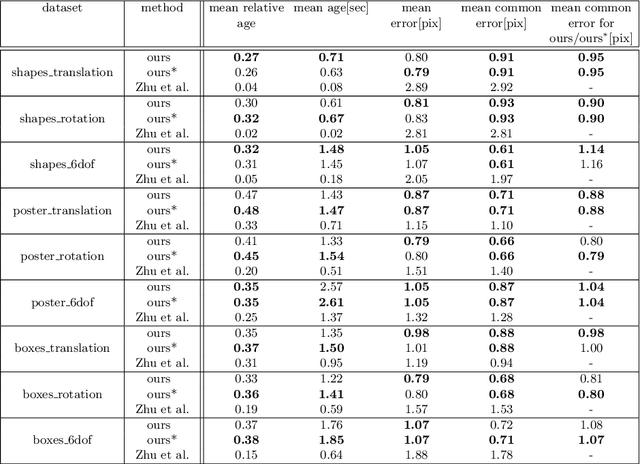
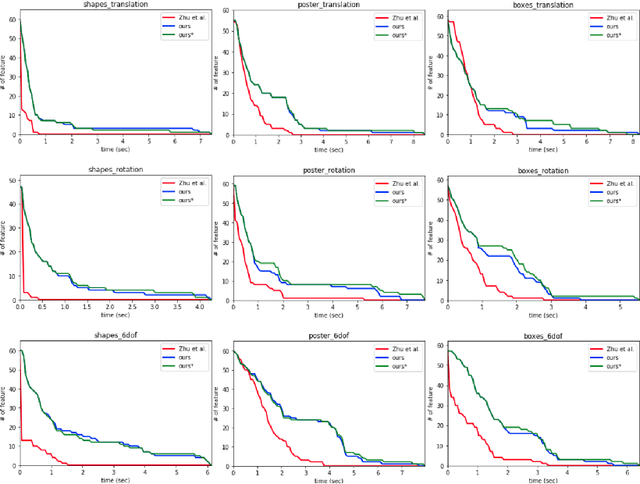

We propose a novel method for continuous-time feature tracking in event cameras. To this end, we track features by aligning events along an estimated trajectory in space-time such that the projection on the image plane results in maximally sharp event patch images. The trajectory is parameterized by $n^{th}$ order B-splines, which are continuous up to $(n-2)^{th}$ derivative. In contrast to previous work, we optimize the curve parameters in a sliding window fashion. On a public dataset we experimentally confirm that the proposed sliding-window B-spline optimization leads to longer and more accurate feature tracks than in previous work.