 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge4Seasons: Benchmarking Visual SLAM and Long-Term Localization for Autonomous Driving in Challenging Conditions
Dec 31, 2022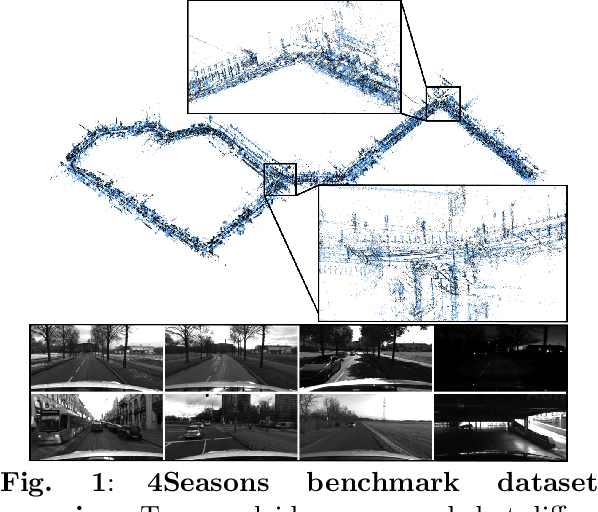
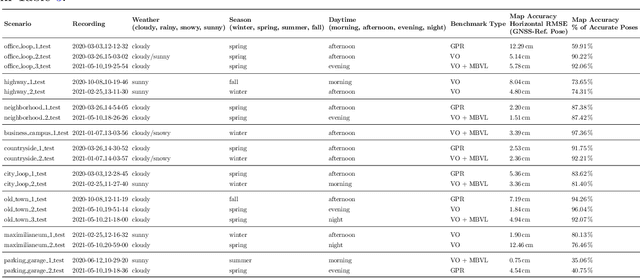

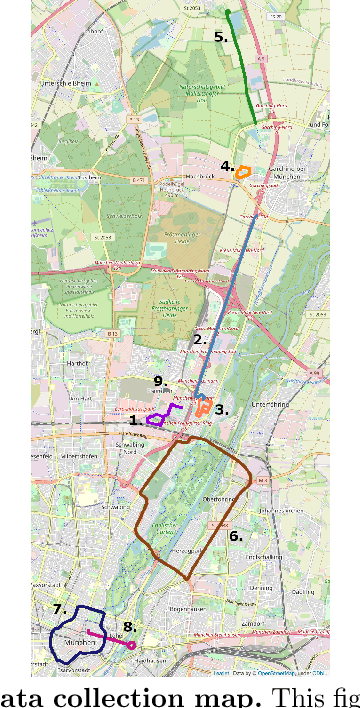
In this paper, we present a novel visual SLAM and long-term localization benchmark for autonomous driving in challenging conditions based on the large-scale 4Seasons dataset. The proposed benchmark provides drastic appearance variations caused by seasonal changes and diverse weather and illumination conditions. While significant progress has been made in advancing visual SLAM on small-scale datasets with similar conditions, there is still a lack of unified benchmarks representative of real-world scenarios for autonomous driving. We introduce a new unified benchmark for jointly evaluating visual odometry, global place recognition, and map-based visual localization performance which is crucial to successfully enable autonomous driving in any condition. The data has been collected for more than one year, resulting in more than 300 km of recordings in nine different environments ranging from a multi-level parking garage to urban (including tunnels) to countryside and highway. We provide globally consistent reference poses with up to centimeter-level accuracy obtained from the fusion of direct stereo-inertial odometry with RTK GNSS. We evaluate the performance of several state-of-the-art visual odometry and visual localization baseline approaches on the benchmark and analyze their properties. The experimental results provide new insights into current approaches and show promising potential for future research. Our benchmark and evaluation protocols will be available at https://www.4seasons-dataset.com/.
Self-Supervised Steering Angle Prediction for Vehicle Control Using Visual Odometry
Mar 20, 2021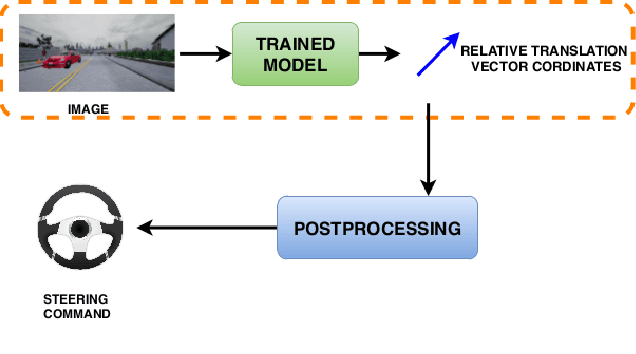
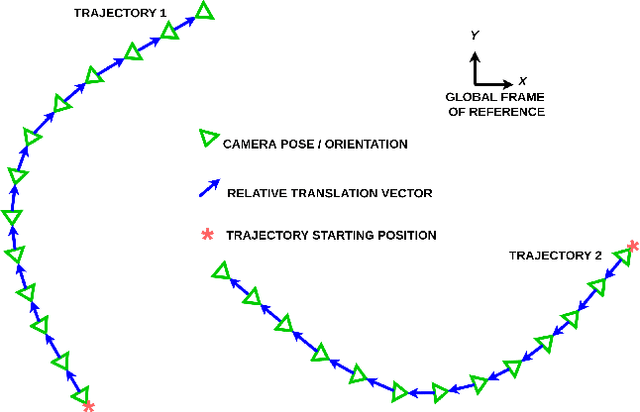
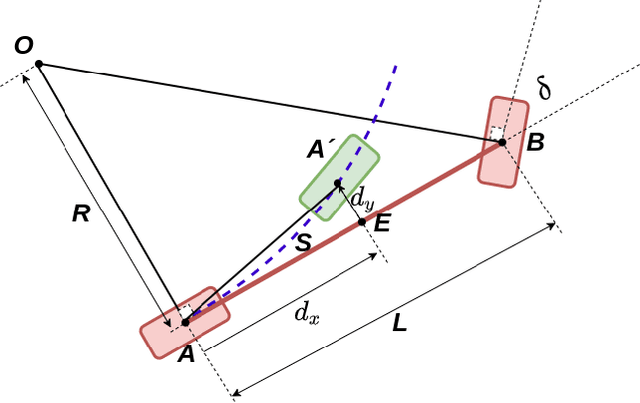
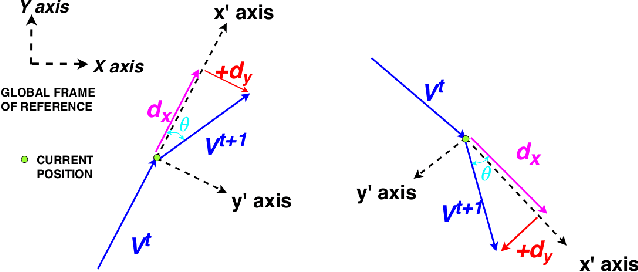
Vision-based learning methods for self-driving cars have primarily used supervised approaches that require a large number of labels for training. However, those labels are usually difficult and expensive to obtain. In this paper, we demonstrate how a model can be trained to control a vehicle's trajectory using camera poses estimated through visual odometry methods in an entirely self-supervised fashion. We propose a scalable framework that leverages trajectory information from several different runs using a camera setup placed at the front of a car. Experimental results on the CARLA simulator demonstrate that our proposed approach performs at par with the model trained with supervision.
Vision-Based Mobile Robotics Obstacle Avoidance With Deep Reinforcement Learning
Mar 08, 2021
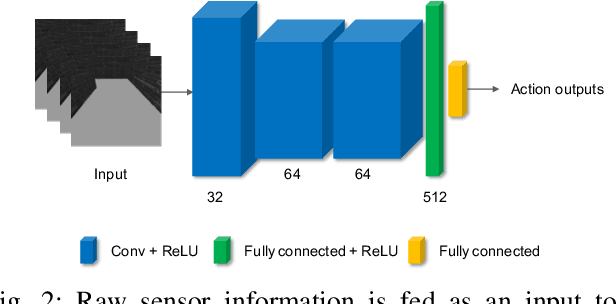

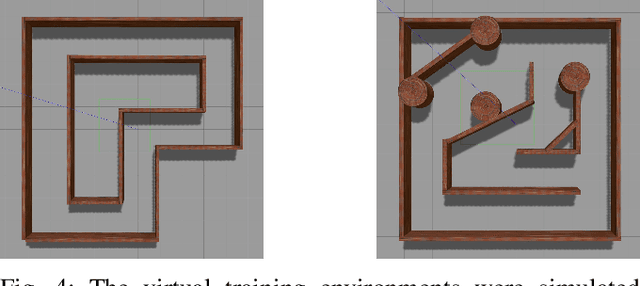
Obstacle avoidance is a fundamental and challenging problem for autonomous navigation of mobile robots. In this paper, we consider the problem of obstacle avoidance in simple 3D environments where the robot has to solely rely on a single monocular camera. In particular, we are interested in solving this problem without relying on localization, mapping, or planning techniques. Most of the existing work consider obstacle avoidance as two separate problems, namely obstacle detection, and control. Inspired by the recent advantages of deep reinforcement learning in Atari games and understanding highly complex situations in Go, we tackle the obstacle avoidance problem as a data-driven end-to-end deep learning approach. Our approach takes raw images as input and generates control commands as output. We show that discrete action spaces are outperforming continuous control commands in terms of expected average reward in maze-like environments. Furthermore, we show how to accelerate the learning and increase the robustness of the policy by incorporating predicted depth maps by a generative adversarial network.
LM-Reloc: Levenberg-Marquardt Based Direct Visual Relocalization
Oct 13, 2020


We present LM-Reloc -- a novel approach for visual relocalization based on direct image alignment. In contrast to prior works that tackle the problem with a feature-based formulation, the proposed method does not rely on feature matching and RANSAC. Hence, the method can utilize not only corners but any region of the image with gradients. In particular, we propose a loss formulation inspired by the classical Levenberg-Marquardt algorithm to train LM-Net. The learned features significantly improve the robustness of direct image alignment, especially for relocalization across different conditions. To further improve the robustness of LM-Net against large image baselines, we propose a pose estimation network, CorrPoseNet, which regresses the relative pose to bootstrap the direct image alignment. Evaluations on the CARLA and Oxford RobotCar relocalization tracking benchmark show that our approach delivers more accurate results than previous state-of-the-art methods while being comparable in terms of robustness.
4Seasons: A Cross-Season Dataset for Multi-Weather SLAM in Autonomous Driving
Sep 14, 2020
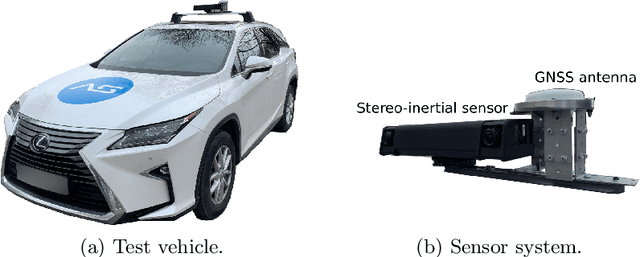


We present a novel dataset covering seasonal and challenging perceptual conditions for autonomous driving. Among others, it enables research on visual odometry, global place recognition, and map-based re-localization tracking. The data was collected in different scenarios and under a wide variety of weather conditions and illuminations, including day and night. This resulted in more than 350 km of recordings in nine different environments ranging from multi-level parking garage over urban (including tunnels) to countryside and highway. We provide globally consistent reference poses with up-to centimeter accuracy obtained from the fusion of direct stereo visual-inertial odometry with RTK-GNSS. The full dataset is available at www.4seasons-dataset.com.
Towards Generalizing Sensorimotor Control Across Weather Conditions
Jul 25, 2019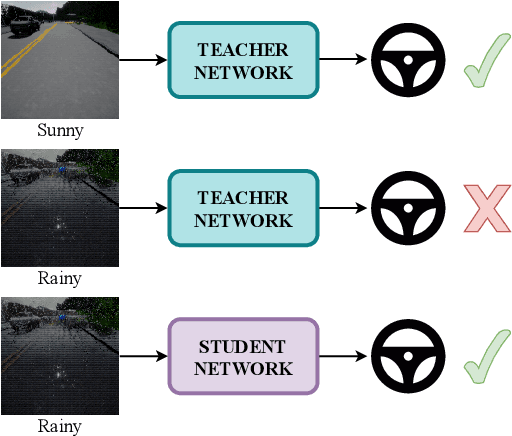



The ability of deep learning models to generalize well across different scenarios depends primarily on the quality and quantity of annotated data. Labeling large amounts of data for all possible scenarios that a model may encounter would not be feasible; if even possible. We propose a framework to deal with limited labeled training data and demonstrate it on the application of vision-based vehicle control. We show how limited steering angle data available for only one condition can be transferred to multiple different weather scenarios. This is done by leveraging unlabeled images in a teacher-student learning paradigm complemented with an image-to-image translation network. The translation network transfers the images to a new domain, whereas the teacher provides soft supervised targets to train the student on this domain. Furthermore, we demonstrate how utilization of auxiliary networks can reduce the size of a model at inference time, without affecting the accuracy. The experiments show that our approach generalizes well across multiple different weather conditions using only ground truth labels from one domain.
GN-Net: The Gauss-Newton Loss for Deep Direct SLAM
Apr 26, 2019
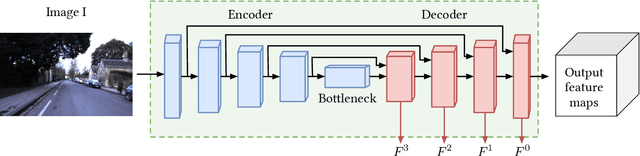


Direct methods for SLAM have shown exceptional performance on odometry tasks. However, they still suffer from dynamic lighting/weather changes and from a bad initialization on large baselines. To mitigate both of these effects, we propose an approach which feeds deep visual descriptors for each pixel as input to the SLAM system. In this work, we introduce GN-Net: a network optimized with the novel Gauss-Newton loss for training deep features. It is designed to maximize the probability of the correct pixel correspondence inside the Gauss-Newton algorithm. This results in features with a larger convergence basin when compared with single-channel grayscale images generally used in SLAM-based approaches. Our network can be trained with ground-truth pixel correspondences between different images, produced either from simulation data or by any state-of-the-art SLAM algorithm. We show that our approach is more robust against bad initialization, variations in day-time, and weather changes thereby outperforming state-of-the-art direct and indirect methods. Furthermore, we release an evaluation benchmark for what we refer to as relocalization tracking. It has been created using the CARLA simulator as well as sequences taken from the Oxford RobotCar Dataset.
Towards Self-Supervised High Level Sensor Fusion
Feb 12, 2019
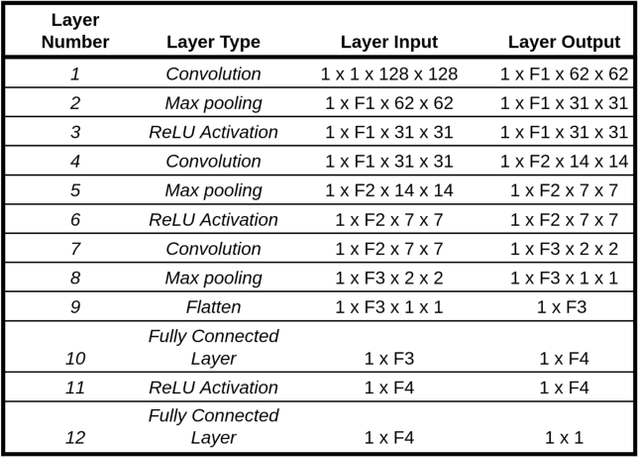


In this paper, we present a framework to control a self-driving car by fusing raw information from RGB images and depth maps. A deep neural network architecture is used for mapping the vision and depth information, respectively, to steering commands. This fusion of information from two sensor sources allows to provide redundancy and fault tolerance in the presence of sensor failures. Even if one of the input sensors fails to produce the correct output, the other functioning sensor would still be able to maneuver the car. Such redundancy is crucial in the critical application of self-driving cars. The experimental results have showed that our method is capable of learning to use the relevant sensor information even when one of the sensors fail without any explicit signal.
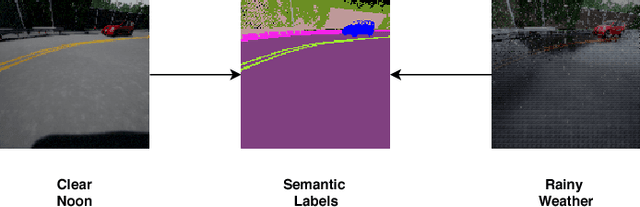
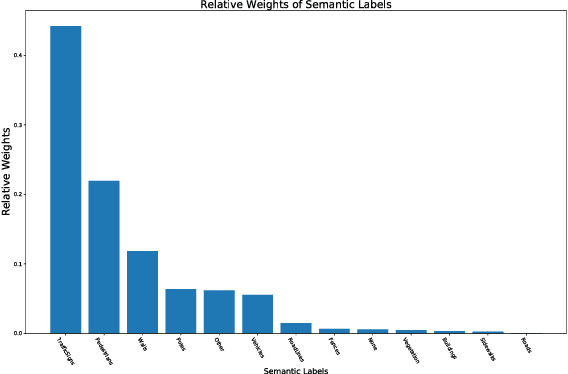
Semantic Label Reduction Techniques for Autonomous Driving
Feb 11, 2019

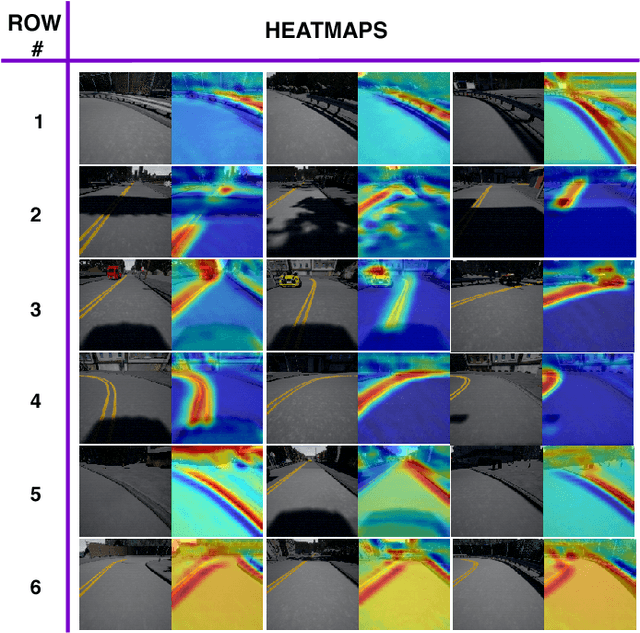

Semantic segmentation maps can be used as input to models for maneuvering the controls of a car. However, not all labels may be necessary for making the control decision. One would expect that certain labels such as road lanes or sidewalks would be more critical in comparison with labels for vegetation or buildings which may not have a direct influence on the car's driving decision. In this appendix, we evaluate and quantify how sensitive and important the different semantic labels are for controlling the car. Labels that do not influence the driving decision are remapped to other classes, thereby simplifying the task by reducing to only labels critical for driving of the vehicle.
Latent Space Reinforcement Learning for Steering Angle Prediction
Feb 11, 2019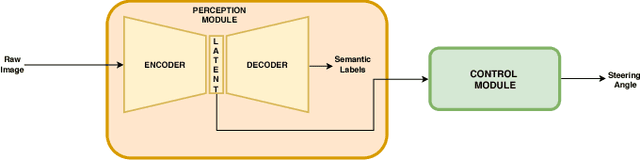

Model-free reinforcement learning has recently been shown to successfully learn navigation policies from raw sensor data. In this work, we address the problem of learning driving policies for an autonomous agent in a high-fidelity simulator. Building upon recent research that applies deep reinforcement learning to navigation problems, we present a modular deep reinforcement learning approach to predict the steering angle of the car from raw images. The first module extracts a low-dimensional latent semantic representation of the image. The control module trained with reinforcement learning takes the latent vector as input to predict the correct steering angle. The experimental results have showed that our method is capable of learning to maneuver the car without any human control signals.