 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Evaluation of Autonomous Systems under Adversarial Attacks
May 05, 2026Most evaluations of autonomous driving policies under adversarial conditions are conducted in simulation, due to cost efficiency and the absence of physical risk. However, purely virtual testing fails to capture structural inconsistencies, supervision constraints, and state-representation effects that arise in real-world data and fundamentally shape policy robustness. This work presents an offline trajectory-learning and adversarial robustness evaluation framework grounded in real-world intersection driving data. Within a controlled data contract, we train and compare three trajectory-learning paradigms: Multi-Layer Perceptron (MLP)-based Behavior Cloning (BC), Transformer-based object-tokenized BC, and inverse reinforcement learning (IRL) formulated within a Generative Adversarial Imitation Learning (GAIL) framework. Models are evaluated using Average Displacement Error (ADE) and Final Displacement Error (FDE). Inference-time robustness is assessed by subjecting trained policies to gradient-based adversarial perturbations across multiple intersection scenarios, yielding a structured robustness evaluation matrix. Results show that state-structure design and architectural inductive biases critically influence adversarial stability, leading to markedly different robustness profiles despite comparable nominal prediction accuracy (ADE < 0.08). Inference-time Projected Gradient Descent (PGD) attacks induce final displacement errors of up to approximately 8 meters. The proposed framework establishes a scalable benchmark for studying offline trajectory learning and adversarial robustness in real-world autonomous driving settings.
Embedding Arithmetic: A Lightweight, Tuning-Free Framework for Post-hoc Bias Mitigation in Text-to-Image Models
Apr 20, 2026Modern text-to-image (T2I) models amplify harmful societal biases, challenging their ethical deployment. We introduce an inference-time method that reliably mitigates social bias while keeping prompt semantics and visual context (background, layout, and style) intact. This ensures context persistency and provides a controllable parameter to adjust mitigation strength, giving practitioners fine-grained control over fairness-coherence trade-offs. Using Embedding Arithmetic, we analyze how bias is structured in the embedding space and correct it without altering model weights, prompts, or datasets. Experiments on FLUX 1.0-Dev and Stable Diffusion 3.5-Large show that the conditional embedding space forms a complex, entangled manifold rather than a grid of disentangled concepts. To rigorously assess semantic preservation beyond the circularity and bias limitations of of CLIP scores, we propose the Concept Coherence Score (CCS). Evaluated against this robust metric, our lightweight, tuning-free method significantly outperforms existing baselines in improving diversity while maintaining high concept coherence, effectively resolving the critical fairness-coherence trade-off. By characterizing how models represent social concepts, we establish geometric understanding of latent space as a principled path toward more transparent, controllable, and fair image generation.
Zwitscherkasten -- DIY Audiovisual bird monitoring
Feb 11, 2026This paper presents Zwitscherkasten, a DiY, multimodal system for bird species monitoring using audio and visual data on edge devices. Deep learning models for bioacoustic and image-based classification are deployed on resource-constrained hardware, enabling real-time, non-invasive monitoring. An acoustic activity detector reduces energy consumption, while visual recognition is performed using fine-grained detection and classification pipelines. Results show that accurate bird species identification is feasible on embedded platforms, supporting scalable biodiversity monitoring and citizen science applications.
DrivIng: A Large-Scale Multimodal Driving Dataset with Full Digital Twin Integration
Jan 21, 2026Perception is a cornerstone of autonomous driving, enabling vehicles to understand their surroundings and make safe, reliable decisions. Developing robust perception algorithms requires large-scale, high-quality datasets that cover diverse driving conditions and support thorough evaluation. Existing datasets often lack a high-fidelity digital twin, limiting systematic testing, edge-case simulation, sensor modification, and sim-to-real evaluations. To address this gap, we present DrivIng, a large-scale multimodal dataset with a complete geo-referenced digital twin of a ~18 km route spanning urban, suburban, and highway segments. Our dataset provides continuous recordings from six RGB cameras, one LiDAR, and high-precision ADMA-based localization, captured across day, dusk, and night. All sequences are annotated at 10 Hz with 3D bounding boxes and track IDs across 12 classes, yielding ~1.2 million annotated instances. Alongside the benefits of a digital twin, DrivIng enables a 1-to-1 transfer of real traffic into simulation, preserving agent interactions while enabling realistic and flexible scenario testing. To support reproducible research and robust validation, we benchmark DrivIng with state-of-the-art perception models and publicly release the dataset, digital twin, HD map, and codebase.
Advancing Robustness in Deep Reinforcement Learning with an Ensemble Defense Approach
Jul 22, 2025Recent advancements in Deep Reinforcement Learning (DRL) have demonstrated its applicability across various domains, including robotics, healthcare, energy optimization, and autonomous driving. However, a critical question remains: How robust are DRL models when exposed to adversarial attacks? While existing defense mechanisms such as adversarial training and distillation enhance the resilience of DRL models, there remains a significant research gap regarding the integration of multiple defenses in autonomous driving scenarios specifically. This paper addresses this gap by proposing a novel ensemble-based defense architecture to mitigate adversarial attacks in autonomous driving. Our evaluation demonstrates that the proposed architecture significantly enhances the robustness of DRL models. Compared to the baseline under FGSM attacks, our ensemble method improves the mean reward from 5.87 to 18.38 (over 213% increase) and reduces the mean collision rate from 0.50 to 0.09 (an 82% decrease) in the highway scenario and merge scenario, outperforming all standalone defense strategies.
Machine Learning Models for Soil Parameter Prediction Based on Satellite, Weather, Clay and Yield Data
Mar 28, 2025



Efficient nutrient management and precise fertilization are essential for advancing modern agriculture, particularly in regions striving to optimize crop yields sustainably. The AgroLens project endeavors to address this challenge by develop ing Machine Learning (ML)-based methodologies to predict soil nutrient levels without reliance on laboratory tests. By leveraging state of the art techniques, the project lays a foundation for acionable insights to improve agricultural productivity in resource-constrained areas, such as Africa. The approach begins with the development of a robust European model using the LUCAS Soil dataset and Sentinel-2 satellite imagery to estimate key soil properties, including phosphorus, potassium, nitrogen, and pH levels. This model is then enhanced by integrating supplementary features, such as weather data, harvest rates, and Clay AI-generated embeddings. This report details the methodological framework, data preprocessing strategies, and ML pipelines employed in this project. Advanced algorithms, including Random Forests, Extreme Gradient Boosting (XGBoost), and Fully Connected Neural Networks (FCNN), were implemented and finetuned for precise nutrient prediction. Results showcase robust model performance, with root mean square error values meeting stringent accuracy thresholds. By establishing a reproducible and scalable pipeline for soil nutrient prediction, this research paves the way for transformative agricultural applications, including precision fertilization and improved resource allocation in underresourced regions like Africa.
Gaussian-Based and Outside-the-Box Runtime Monitoring Join Forces
Oct 08, 2024Since neural networks can make wrong predictions even with high confidence, monitoring their behavior at runtime is important, especially in safety-critical domains like autonomous driving. In this paper, we combine ideas from previous monitoring approaches based on observing the activation values of hidden neurons. In particular, we combine the Gaussian-based approach, which observes whether the current value of each monitored neuron is similar to typical values observed during training, and the Outside-the-Box monitor, which creates clusters of the acceptable activation values, and, thus, considers the correlations of the neurons' values. Our experiments evaluate the achieved improvement.
Unlocking Past Information: Temporal Embeddings in Cooperative Bird's Eye View Prediction
Jan 25, 2024Accurate and comprehensive semantic segmentation of Bird's Eye View (BEV) is essential for ensuring safe and proactive navigation in autonomous driving. Although cooperative perception has exceeded the detection capabilities of single-agent systems, prevalent camera-based algorithms in cooperative perception neglect valuable information derived from historical observations. This limitation becomes critical during sensor failures or communication issues as cooperative perception reverts to single-agent perception, leading to degraded performance and incomplete BEV segmentation maps. This paper introduces TempCoBEV, a temporal module designed to incorporate historical cues into current observations, thereby improving the quality and reliability of BEV map segmentations. We propose an importance-guided attention architecture to effectively integrate temporal information that prioritizes relevant properties for BEV map segmentation. TempCoBEV is an independent temporal module that seamlessly integrates into state-of-the-art camera-based cooperative perception models. We demonstrate through extensive experiments on the OPV2V dataset that TempCoBEV performs better than non-temporal models in predicting current and future BEV map segmentations, particularly in scenarios involving communication failures. We show the efficacy of TempCoBEV and its capability to integrate historical cues into the current BEV map, improving predictions under optimal communication conditions by up to 2% and under communication failures by up to 19%. The code will be published on GitHub.
Generation of Realistic Synthetic Raw Radar Data for Automated Driving Applications using Generative Adversarial Networks
Aug 08, 2023The main approaches for simulating FMCW radar are based on ray tracing, which is usually computationally intensive and do not account for background noise. This work proposes a faster method for FMCW radar simulation capable of generating synthetic raw radar data using generative adversarial networks (GAN). The code and pre-trained weights are open-source and available on GitHub. This method generates 16 simultaneous chirps, which allows the generated data to be used for the further development of algorithms for processing radar data (filtering and clustering). This can increase the potential for data augmentation, e.g., by generating data in non-existent or safety-critical scenarios that are not reproducible in real life. In this work, the GAN was trained with radar measurements of a motorcycle and used to generate synthetic raw radar data of a motorcycle traveling in a straight line. For generating this data, the distance of the motorcycle and Gaussian noise are used as input to the neural network. The synthetic generated radar chirps were evaluated using the Frechet Inception Distance (FID). Then, the Range-Azimuth (RA) map is calculated twice: first, based on synthetic data using this GAN and, second, based on real data. Based on these RA maps, an algorithm with adaptive threshold and edge detection is used for object detection. The results have shown that the data is realistic in terms of coherent radar reflections of the motorcycle and background noise based on the comparison of chirps, the RA maps and the object detection results. Thus, the proposed method in this work has shown to minimize the simulation-to-reality gap for the generation of radar data.
VolNet: Estimating Human Body Part Volumes from a Single RGB Image
Jul 05, 2021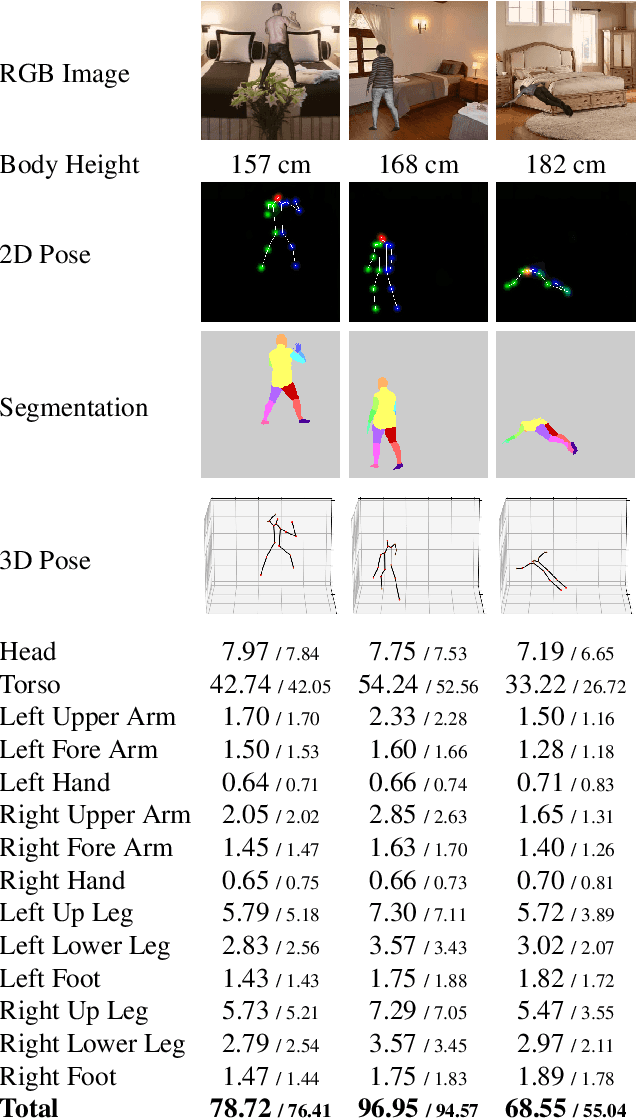

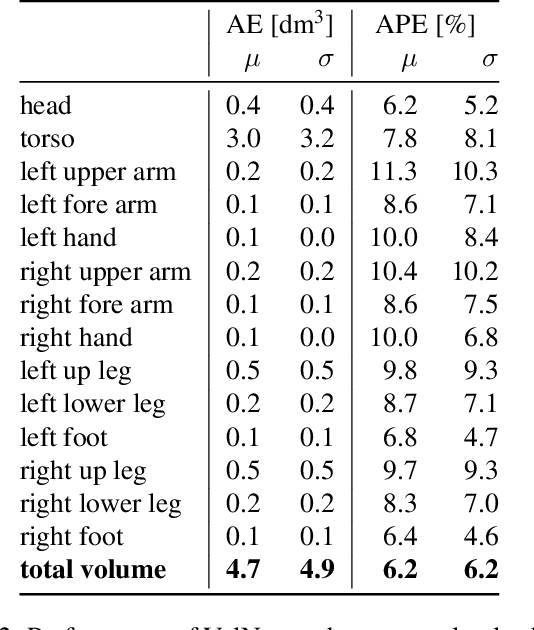
Human body volume estimation from a single RGB image is a challenging problem despite minimal attention from the research community. However VolNet, an architecture leveraging 2D and 3D pose estimation, body part segmentation and volume regression extracted from a single 2D RGB image combined with the subject's body height can be used to estimate the total body volume. VolNet is designed to predict the 2D and 3D pose as well as the body part segmentation in intermediate tasks. We generated a synthetic, large-scale dataset of photo-realistic images of human bodies with a wide range of body shapes and realistic poses called SURREALvols. By using Volnet and combining multiple stacked hourglass networks together with ResNeXt, our model correctly predicted the volume in ~82% of cases with a 10% tolerance threshold. This is a considerable improvement compared to state-of-the-art solutions such as BodyNet with only a ~38% success rate.