 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Spatio-Temporal Feature Representations for Video-Based Gaze Estimation
Dec 19, 2025



Video-based gaze estimation methods aim to capture the inherently temporal dynamics of human eye gaze from multiple image frames. However, since models must capture both spatial and temporal relationships, performance is limited by the feature representations within a frame but also between multiple frames. We propose the Spatio-Temporal Gaze Network (ST-Gaze), a model that combines a CNN backbone with dedicated channel attention and self-attention modules to fuse eye and face features optimally. The fused features are then treated as a spatial sequence, allowing for the capture of an intra-frame context, which is then propagated through time to model inter-frame dynamics. We evaluated our method on the EVE dataset and show that ST-Gaze achieves state-of-the-art performance both with and without person-specific adaptation. Additionally, our ablation study provides further insights into the model performance, showing that preserving and modelling intra-frame spatial context with our spatio-temporal recurrence is fundamentally superior to premature spatial pooling. As such, our results pave the way towards more robust video-based gaze estimation using commonly available cameras.
HAIFAI: Human-AI Collaboration for Mental Face Reconstruction
Dec 09, 2024We present HAIFAI - a novel collaborative human-AI system to tackle the challenging task of reconstructing a visual representation of a face that exists only in a person's mind. Users iteratively rank images presented by the AI system based on their resemblance to a mental image. These rankings, in turn, allow the system to extract relevant image features, fuse them into a unified feature vector, and use a generative model to reconstruct the mental image. We also propose an extension called HAIFAI-X that allows users to manually refine and further improve the reconstruction using an easy-to-use slider interface. To avoid the need for tedious human data collection for model training, we introduce a computational user model of human ranking behaviour. For this, we collected a small face ranking dataset through an online crowd-sourcing study containing data from 275 participants. We evaluate HAIFAI and HAIFAI-X in a 12-participant user study and show that HAIFAI outperforms the previous state of the art regarding reconstruction quality, usability, perceived workload, and reconstruction speed. HAIFAI-X achieves even better reconstruction quality at the cost of reduced usability, perceived workload, and increased reconstruction time. We further validate the reconstructions in a subsequent face ranking study with 18 participants and show that HAIFAI-X achieves a new state-of-the-art identification rate of 60.6%. These findings represent a significant advancement towards developing new collaborative intelligent systems capable of reliably and effortlessly reconstructing a user's mental image.
Learning User Embeddings from Human Gaze for Personalised Saliency Prediction
Mar 26, 2024



Reusable embeddings of user behaviour have shown significant performance improvements for the personalised saliency prediction task. However, prior works require explicit user characteristics and preferences as input, which are often difficult to obtain. We present a novel method to extract user embeddings from pairs of natural images and corresponding saliency maps generated from a small amount of user-specific eye tracking data. At the core of our method is a Siamese convolutional neural encoder that learns the user embeddings by contrasting the image and personal saliency map pairs of different users. Evaluations on two public saliency datasets show that the generated embeddings have high discriminative power, are effective at refining universal saliency maps to the individual users, and generalise well across users and images. Finally, based on our model's ability to encode individual user characteristics, our work points towards other applications that can benefit from reusable embeddings of gaze behaviour.
DiffGaze: A Diffusion Model for Continuous Gaze Sequence Generation on 360° Images
Mar 26, 2024
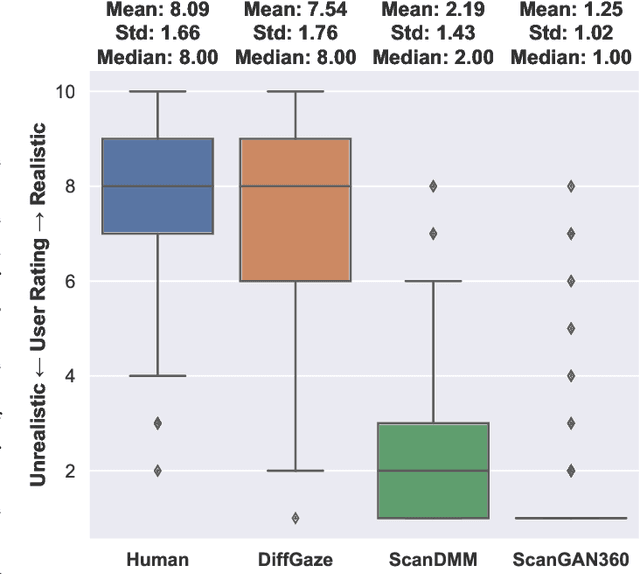


We present DiffGaze, a novel method for generating realistic and diverse continuous human gaze sequences on 360{\deg} images based on a conditional score-based denoising diffusion model. Generating human gaze on 360{\deg} images is important for various human-computer interaction and computer graphics applications, e.g. for creating large-scale eye tracking datasets or for realistic animation of virtual humans. However, existing methods are limited to predicting discrete fixation sequences or aggregated saliency maps, thereby neglecting crucial parts of natural gaze behaviour. Our method uses features extracted from 360{\deg} images as condition and uses two transformers to model the temporal and spatial dependencies of continuous human gaze. We evaluate DiffGaze on two 360{\deg} image benchmarks for gaze sequence generation as well as scanpath prediction and saliency prediction. Our evaluations show that DiffGaze outperforms state-of-the-art methods on all tasks on both benchmarks. We also report a 21-participant user study showing that our method generates gaze sequences that are indistinguishable from real human sequences.
SeFFeC: Semantic Facial Feature Control for Fine-grained Face Editing
Mar 26, 2024



We propose Semantic Facial Feature Control (SeFFeC) - a novel method for fine-grained face shape editing. Our method enables the manipulation of human-understandable, semantic face features, such as nose length or mouth width, which are defined by different groups of facial landmarks. In contrast to existing methods, the use of facial landmarks enables precise measurement of the facial features, which then enables training SeFFeC without any manually annotated labels. SeFFeC consists of a transformer-based encoder network that takes a latent vector of a pre-trained generative model and a facial feature embedding as input, and learns to modify the latent vector to perform the desired face edit operation. To ensure that the desired feature measurement is changed towards the target value without altering uncorrelated features, we introduced a novel semantic face feature loss. Qualitative and quantitative results show that SeFFeC enables precise and fine-grained control of 23 facial features, some of which could not previously be controlled by other methods, without requiring manual annotations. Unlike existing methods, SeFFeC also provides deterministic control over the exact values of the facial features and more localised and disentangled face edits.
Int-HRL: Towards Intention-based Hierarchical Reinforcement Learning
Jun 20, 2023While deep reinforcement learning (RL) agents outperform humans on an increasing number of tasks, training them requires data equivalent to decades of human gameplay. Recent hierarchical RL methods have increased sample efficiency by incorporating information inherent to the structure of the decision problem but at the cost of having to discover or use human-annotated sub-goals that guide the learning process. We show that intentions of human players, i.e. the precursor of goal-oriented decisions, can be robustly predicted from eye gaze even for the long-horizon sparse rewards task of Montezuma's Revenge - one of the most challenging RL tasks in the Atari2600 game suite. We propose Int-HRL: Hierarchical RL with intention-based sub-goals that are inferred from human eye gaze. Our novel sub-goal extraction pipeline is fully automatic and replaces the need for manual sub-goal annotation by human experts. Our evaluations show that replacing hand-crafted sub-goals with automatically extracted intentions leads to a HRL agent that is significantly more sample efficient than previous methods.
Neuro-Symbolic Visual Dialog
Aug 22, 2022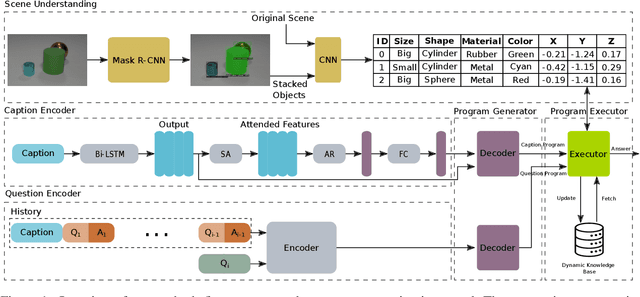
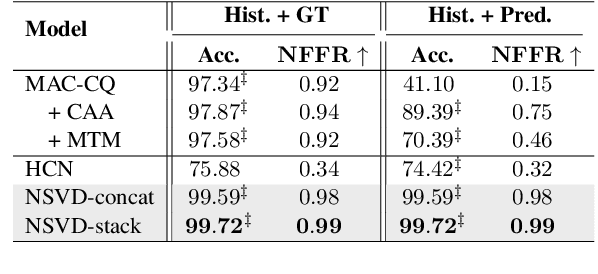
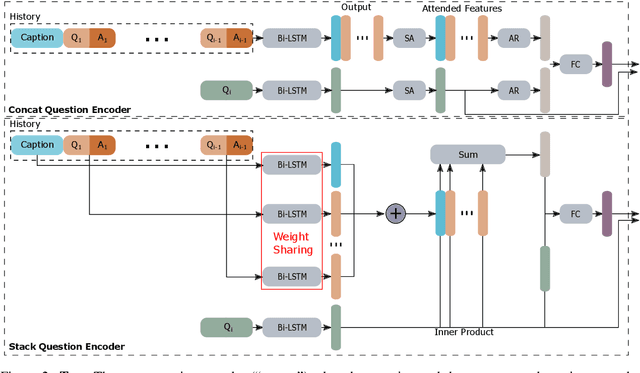
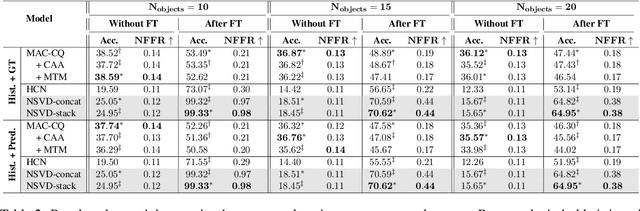
We propose Neuro-Symbolic Visual Dialog (NSVD) -the first method to combine deep learning and symbolic program execution for multi-round visually-grounded reasoning. NSVD significantly outperforms existing purely-connectionist methods on two key challenges inherent to visual dialog: long-distance co-reference resolution as well as vanishing question-answering performance. We demonstrate the latter by proposing a more realistic and stricter evaluation scheme in which we use predicted answers for the full dialog history when calculating accuracy. We describe two variants of our model and show that using this new scheme, our best model achieves an accuracy of 99.72% on CLEVR-Dialog -a relative improvement of more than 10% over the state of the art while only requiring a fraction of training data. Moreover, we demonstrate that our neuro-symbolic models have a higher mean first failure round, are more robust against incomplete dialog histories, and generalise better not only to dialogs that are up to three times longer than those seen during training but also to unseen question types and scenes.
Scanpath Prediction on Information Visualisations
Dec 04, 2021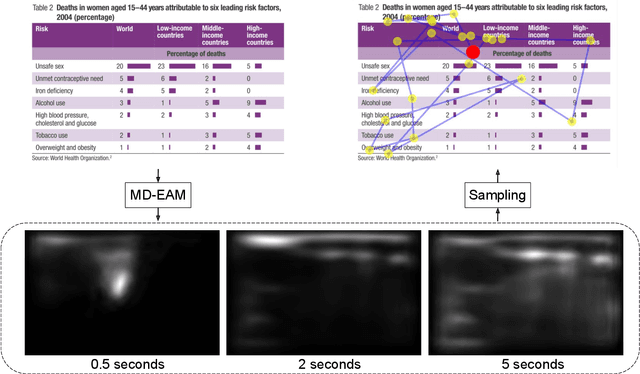
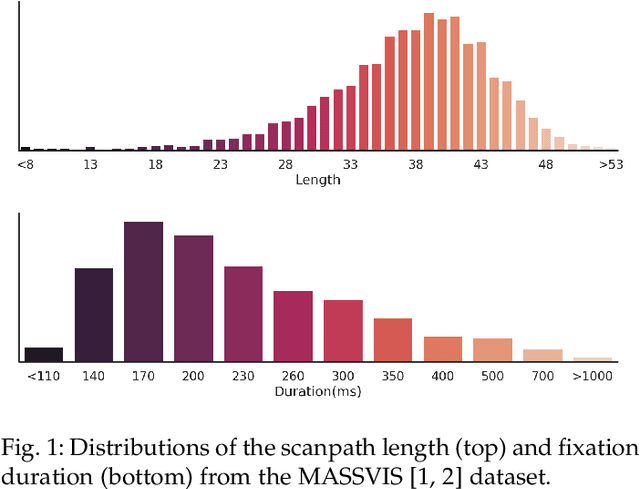
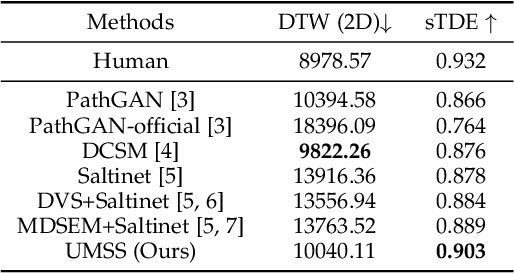
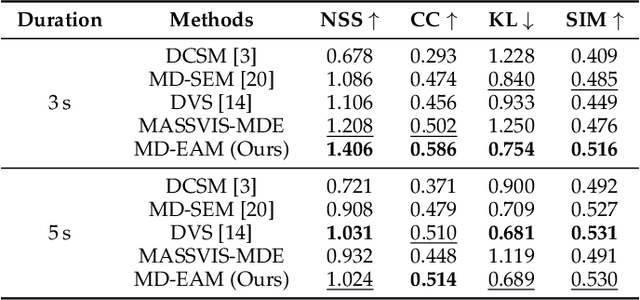
We propose Unified Model of Saliency and Scanpaths (UMSS) -- a model that learns to predict visual saliency and scanpaths (i.e. sequences of eye fixations) on information visualisations. Although scanpaths provide rich information about the importance of different visualisation elements during the visual exploration process, prior work has been limited to predicting aggregated attention statistics, such as visual saliency. We present in-depth analyses of gaze behaviour for different information visualisation elements (e.g. Title, Label, Data) on the popular MASSVIS dataset. We show that while, overall, gaze patterns are surprisingly consistent across visualisations and viewers, there are also structural differences in gaze dynamics for different elements. Informed by our analyses, UMSS first predicts multi-duration element-level saliency maps, then probabilistically samples scanpaths from them. Extensive experiments on MASSVIS show that our method consistently outperforms state-of-the-art methods with respect to several, widely used scanpath and saliency evaluation metrics. Our method achieves a relative improvement in sequence score of 11.5% for scanpath prediction, and a relative improvement in Pearson correlation coefficient of up to 23.6% for saliency prediction. These results are auspicious and point towards richer user models and simulations of visual attention on visualisations without the need for any eye tracking equipment.
Neural Photofit: Gaze-based Mental Image Reconstruction
Aug 17, 2021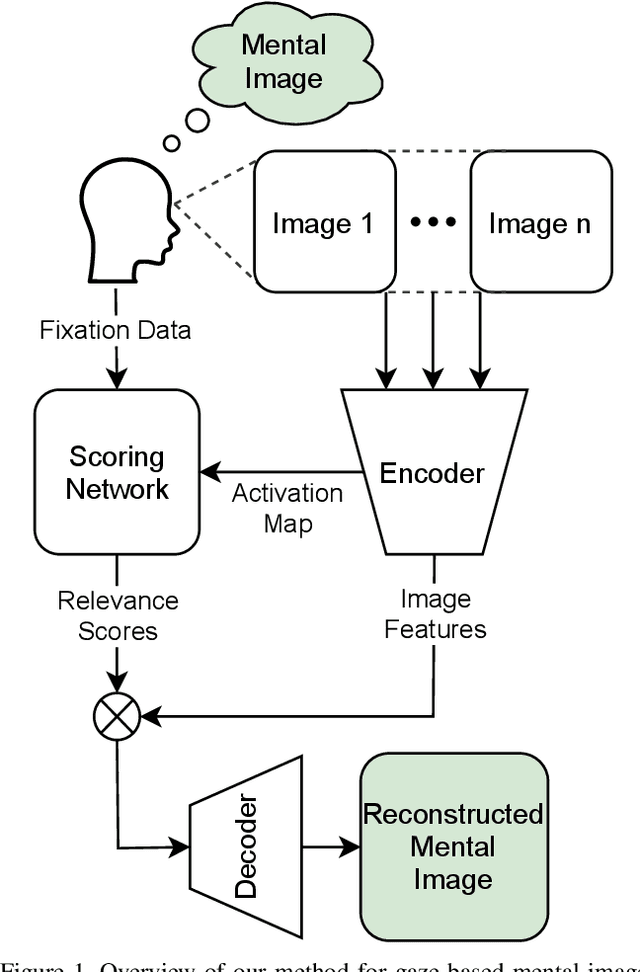
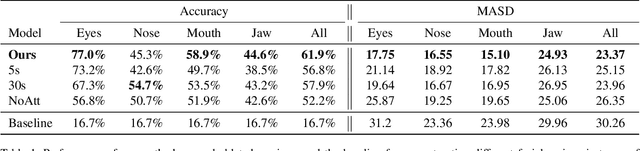

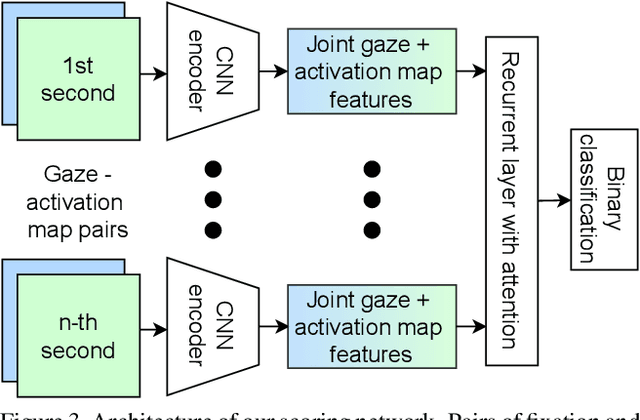
We propose a novel method that leverages human fixations to visually decode the image a person has in mind into a photofit (facial composite). Our method combines three neural networks: An encoder, a scoring network, and a decoder. The encoder extracts image features and predicts a neural activation map for each face looked at by a human observer. A neural scoring network compares the human and neural attention and predicts a relevance score for each extracted image feature. Finally, image features are aggregated into a single feature vector as a linear combination of all features weighted by relevance which a decoder decodes into the final photofit. We train the neural scoring network on a novel dataset containing gaze data of 19 participants looking at collages of synthetic faces. We show that our method significantly outperforms a mean baseline predictor and report on a human study that shows that we can decode photofits that are visually plausible and close to the observer's mental image.
Accurate and Robust Eye Contact Detection During Everyday Mobile Device Interactions
Jul 25, 2019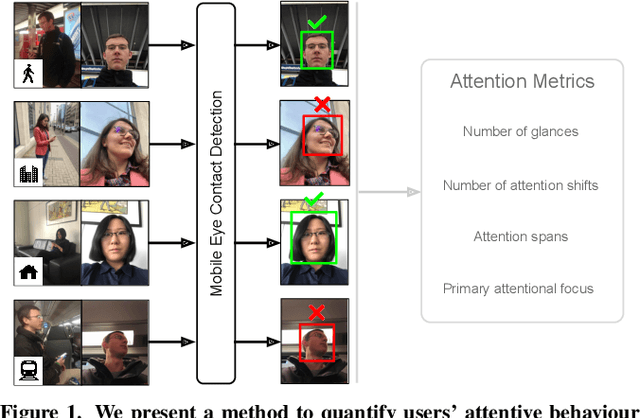

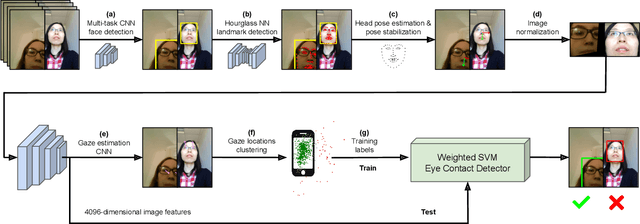

Quantification of human attention is key to several tasks in mobile human-computer interaction (HCI), such as predicting user interruptibility, estimating noticeability of user interface content, or measuring user engagement. Previous works to study mobile attentive behaviour required special-purpose eye tracking equipment or constrained users' mobility. We propose a novel method to sense and analyse visual attention on mobile devices during everyday interactions. We demonstrate the capabilities of our method on the sample task of eye contact detection that has recently attracted increasing research interest in mobile HCI. Our method builds on a state-of-the-art method for unsupervised eye contact detection and extends it to address challenges specific to mobile interactive scenarios. Through evaluation on two current datasets, we demonstrate significant performance improvements for eye contact detection across mobile devices, users, or environmental conditions. Moreover, we discuss how our method enables the calculation of additional attention metrics that, for the first time, enable researchers from different domains to study and quantify attention allocation during mobile interactions in the wild.