 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGSFix3D: Diffusion-Guided Repair of Novel Views in Gaussian Splatting
Aug 20, 2025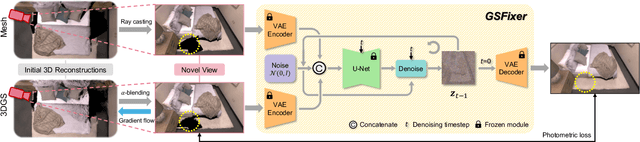
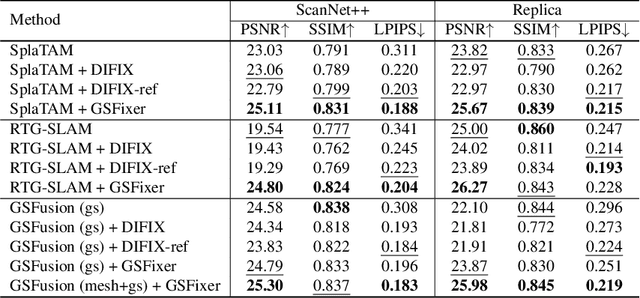
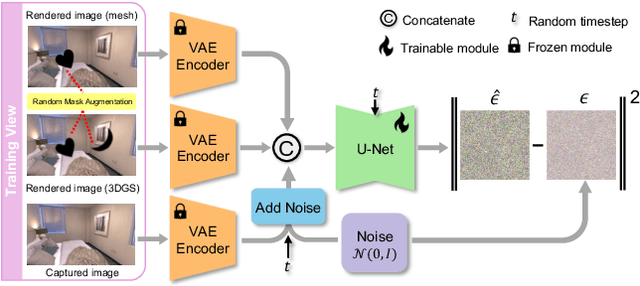

Recent developments in 3D Gaussian Splatting have significantly enhanced novel view synthesis, yet generating high-quality renderings from extreme novel viewpoints or partially observed regions remains challenging. Meanwhile, diffusion models exhibit strong generative capabilities, but their reliance on text prompts and lack of awareness of specific scene information hinder accurate 3D reconstruction tasks. To address these limitations, we introduce GSFix3D, a novel framework that improves the visual fidelity in under-constrained regions by distilling prior knowledge from diffusion models into 3D representations, while preserving consistency with observed scene details. At its core is GSFixer, a latent diffusion model obtained via our customized fine-tuning protocol that can leverage both mesh and 3D Gaussians to adapt pretrained generative models to a variety of environments and artifact types from different reconstruction methods, enabling robust novel view repair for unseen camera poses. Moreover, we propose a random mask augmentation strategy that empowers GSFixer to plausibly inpaint missing regions. Experiments on challenging benchmarks demonstrate that our GSFix3D and GSFixer achieve state-of-the-art performance, requiring only minimal scene-specific fine-tuning on captured data. Real-world test further confirms its resilience to potential pose errors. Our code and data will be made publicly available. Project page: https://gsfix3d.github.io.
FindAnything: Open-Vocabulary and Object-Centric Mapping for Robot Exploration in Any Environment
Apr 11, 2025Geometrically accurate and semantically expressive map representations have proven invaluable to facilitate robust and safe mobile robot navigation and task planning. Nevertheless, real-time, open-vocabulary semantic understanding of large-scale unknown environments is still an open problem. In this paper we present FindAnything, an open-world mapping and exploration framework that incorporates vision-language information into dense volumetric submaps. Thanks to the use of vision-language features, FindAnything bridges the gap between pure geometric and open-vocabulary semantic information for a higher level of understanding while allowing to explore any environment without the help of any external source of ground-truth pose information. We represent the environment as a series of volumetric occupancy submaps, resulting in a robust and accurate map representation that deforms upon pose updates when the underlying SLAM system corrects its drift, allowing for a locally consistent representation between submaps. Pixel-wise vision-language features are aggregated from efficient SAM (eSAM)-generated segments, which are in turn integrated into object-centric volumetric submaps, providing a mapping from open-vocabulary queries to 3D geometry that is scalable also in terms of memory usage. The open-vocabulary map representation of FindAnything achieves state-of-the-art semantic accuracy in closed-set evaluations on the Replica dataset. This level of scene understanding allows a robot to explore environments based on objects or areas of interest selected via natural language queries. Our system is the first of its kind to be deployed on resource-constrained devices, such as MAVs, leveraging vision-language information for real-world robotic tasks.
SuperEvent: Cross-Modal Learning of Event-based Keypoint Detection
Mar 31, 2025
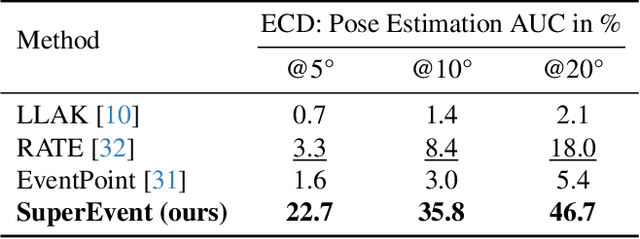
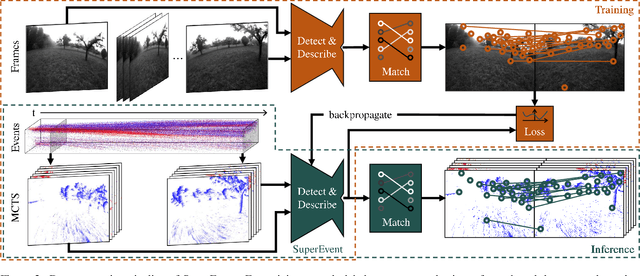
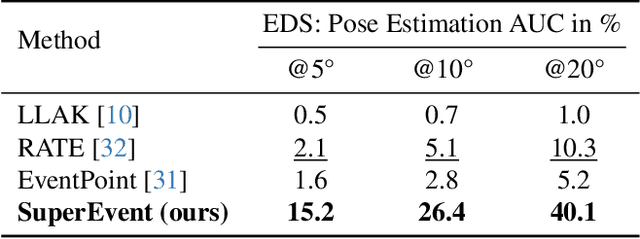
Event-based keypoint detection and matching holds significant potential, enabling the integration of event sensors into highly optimized Visual SLAM systems developed for frame cameras over decades of research. Unfortunately, existing approaches struggle with the motion-dependent appearance of keypoints and the complex noise prevalent in event streams, resulting in severely limited feature matching capabilities and poor performance on downstream tasks. To mitigate this problem, we propose SuperEvent, a data-driven approach to predict stable keypoints with expressive descriptors. Due to the absence of event datasets with ground truth keypoint labels, we leverage existing frame-based keypoint detectors on readily available event-aligned and synchronized gray-scale frames for self-supervision: we generate temporally sparse keypoint pseudo-labels considering that events are a product of both scene appearance and camera motion. Combined with our novel, information-rich event representation, we enable SuperEvent to effectively learn robust keypoint detection and description in event streams. Finally, we demonstrate the usefulness of SuperEvent by its integration into a modern sparse keypoint and descriptor-based SLAM framework originally developed for traditional cameras, surpassing the state-of-the-art in event-based SLAM by a wide margin. Source code and multimedia material are available at smartroboticslab.github.io/SuperEvent.
Online Tree Reconstruction and Forest Inventory on a Mobile Robotic System
Mar 26, 2024



Terrestrial laser scanning (TLS) is the standard technique used to create accurate point clouds for digital forest inventories. However, the measurement process is demanding, requiring up to two days per hectare for data collection, significant data storage, as well as resource-heavy post-processing of 3D data. In this work, we present a real-time mapping and analysis system that enables online generation of forest inventories using mobile laser scanners that can be mounted e.g. on mobile robots. Given incrementally created and locally accurate submaps-data payloads-our approach extracts tree candidates using a custom, Voronoi-inspired clustering algorithm. Tree candidates are reconstructed using an adapted Hough algorithm, which enables robust modeling of the tree stem. Further, we explicitly incorporate the incremental nature of the data collection by consistently updating the database using a pose graph LiDAR SLAM system. This enables us to refine our estimates of the tree traits if an area is revisited later during a mission. We demonstrate competitive accuracy to TLS or manual measurements using laser scanners that we mounted on backpacks or mobile robots operating in conifer, broad-leaf and mixed forests. Our results achieve RMSE of 1.93 cm, a bias of 0.65 cm and a standard deviation of 1.81 cm (averaged across these sequences)-with no post-processing required after the mission is complete.
SC-Diff: 3D Shape Completion with Latent Diffusion Models
Mar 19, 2024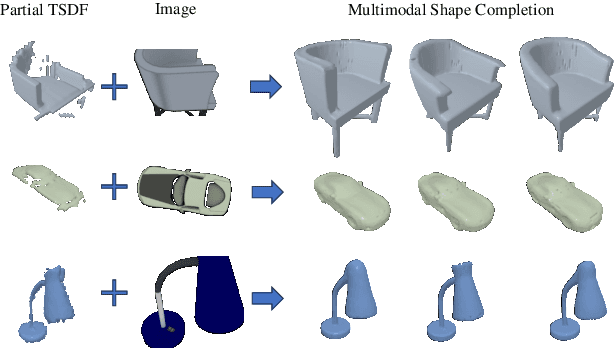
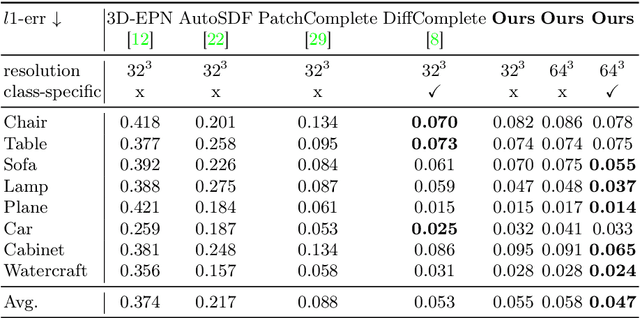
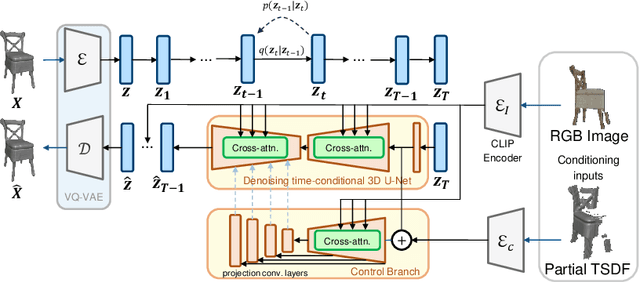
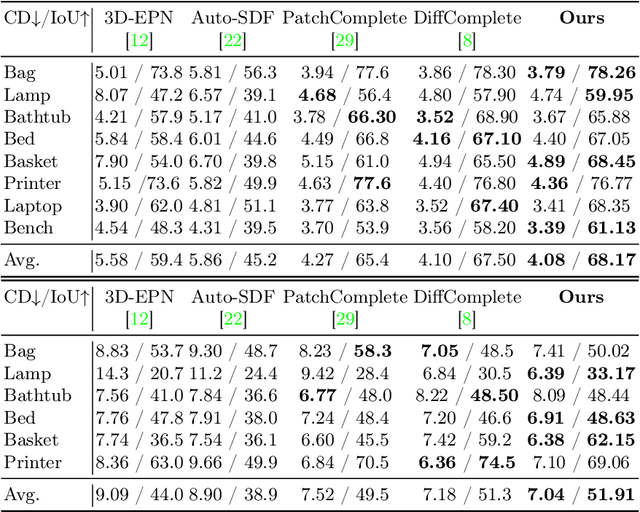
This paper introduces a 3D shape completion approach using a 3D latent diffusion model optimized for completing shapes, represented as Truncated Signed Distance Functions (TSDFs), from partial 3D scans. Our method combines image-based conditioning through cross-attention and spatial conditioning through the integration of 3D features from captured partial scans. This dual guidance enables high-fidelity, realistic shape completions at superior resolutions. At the core of our approach is the compression of 3D data into a low-dimensional latent space using an auto-encoder inspired by 2D latent diffusion models. This compression facilitates the processing of higher-resolution shapes and allows us to apply our model across multiple object classes, a significant improvement over other existing diffusion-based shape completion methods, which often require a separate diffusion model for each class. We validated our approach against two common benchmarks in the field of shape completion, demonstrating competitive performance in terms of accuracy and realism and performing on par with state-of-the-art methods despite operating at a higher resolution with a single model for all object classes. We present a comprehensive evaluation of our model, showcasing its efficacy in handling diverse shape completion challenges, even on unseen object classes. The code will be released upon acceptance.
DynamicGlue: Epipolar and Time-Informed Data Association in Dynamic Environments using Graph Neural Networks
Mar 19, 2024



The assumption of a static environment is common in many geometric computer vision tasks like SLAM but limits their applicability in highly dynamic scenes. Since these tasks rely on identifying point correspondences between input images within the static part of the environment, we propose a graph neural network-based sparse feature matching network designed to perform robust matching under challenging conditions while excluding keypoints on moving objects. We employ a similar scheme of attentional aggregation over graph edges to enhance keypoint representations as state-of-the-art feature-matching networks but augment the graph with epipolar and temporal information and vastly reduce the number of graph edges. Furthermore, we introduce a self-supervised training scheme to extract pseudo labels for image pairs in dynamic environments from exclusively unprocessed visual-inertial data. A series of experiments show the superior performance of our network as it excludes keypoints on moving objects compared to state-of-the-art feature matching networks while still achieving similar results regarding conventional matching metrics. When integrated into a SLAM system, our network significantly improves performance, especially in highly dynamic scenes.
Scalable Autonomous Drone Flight in the Forest with Visual-Inertial SLAM and Dense Submaps Built without LiDAR
Mar 14, 2024



Forestry constitutes a key element for a sustainable future, while it is supremely challenging to introduce digital processes to improve efficiency. The main limitation is the difficulty of obtaining accurate maps at high temporal and spatial resolution as a basis for informed forestry decision-making, due to the vast area forests extend over and the sheer number of trees. To address this challenge, we present an autonomous Micro Aerial Vehicle (MAV) system which purely relies on cost-effective and light-weight passive visual and inertial sensors to perform under-canopy autonomous navigation. We leverage visual-inertial simultaneous localization and mapping (VI-SLAM) for accurate MAV state estimates and couple it with a volumetric occupancy submapping system to achieve a scalable mapping framework which can be directly used for path planning. As opposed to a monolithic map, submaps inherently deal with inevitable drift and corrections from VI-SLAM, since they move with pose estimates as they are updated. To ensure the safety of the MAV during navigation, we also propose a novel reference trajectory anchoring scheme that moves and deforms the reference trajectory the MAV is tracking upon state updates from the VI-SLAM system in a consistent way, even upon large changes in state estimates due to loop-closures. We thoroughly validate our system in both real and simulated forest environments with high tree densities in excess of 400 trees per hectare and at speeds up to 3 m/s - while not encountering a single collision or system failure. To the best of our knowledge this is the first system which achieves this level of performance in such unstructured environment using low-cost passive visual sensors and fully on-board computation including VI-SLAM.
GloPro: Globally-Consistent Uncertainty-Aware 3D Human Pose Estimation & Tracking in the Wild
Sep 20, 2023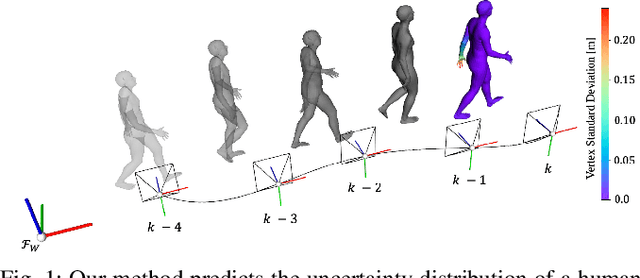
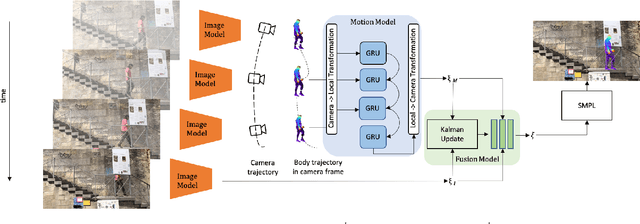
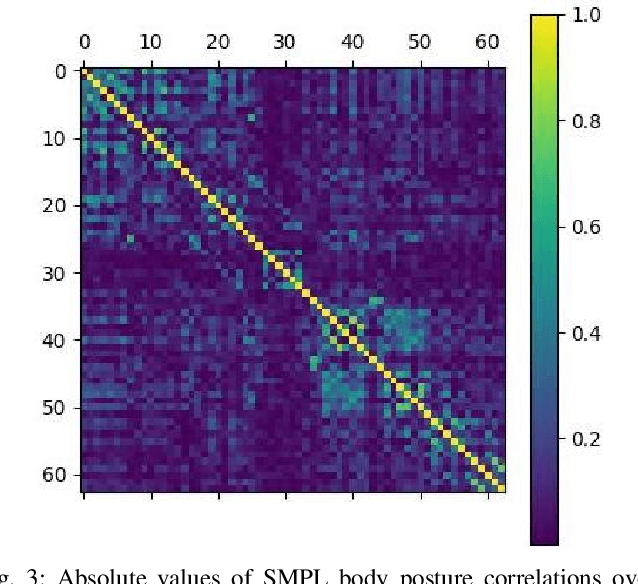
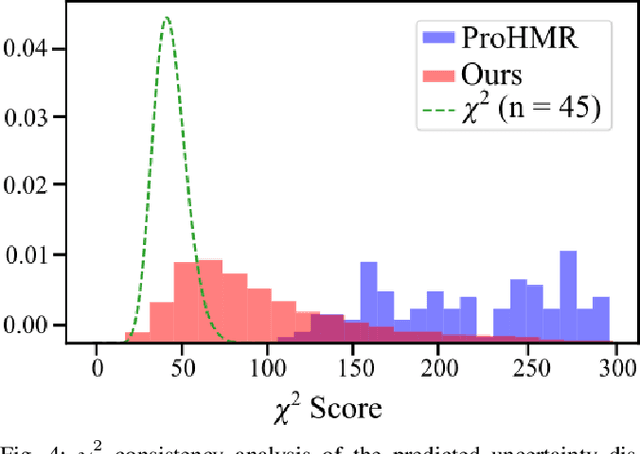
An accurate and uncertainty-aware 3D human body pose estimation is key to enabling truly safe but efficient human-robot interactions. Current uncertainty-aware methods in 3D human pose estimation are limited to predicting the uncertainty of the body posture, while effectively neglecting the body shape and root pose. In this work, we present GloPro, which to the best of our knowledge the first framework to predict an uncertainty distribution of a 3D body mesh including its shape, pose, and root pose, by efficiently fusing visual clues with a learned motion model. We demonstrate that it vastly outperforms state-of-the-art methods in terms of human trajectory accuracy in a world coordinate system (even in the presence of severe occlusions), yields consistent uncertainty distributions, and can run in real-time.
BodySLAM++: Fast and Tightly-Coupled Visual-Inertial Camera and Human Motion Tracking
Sep 03, 2023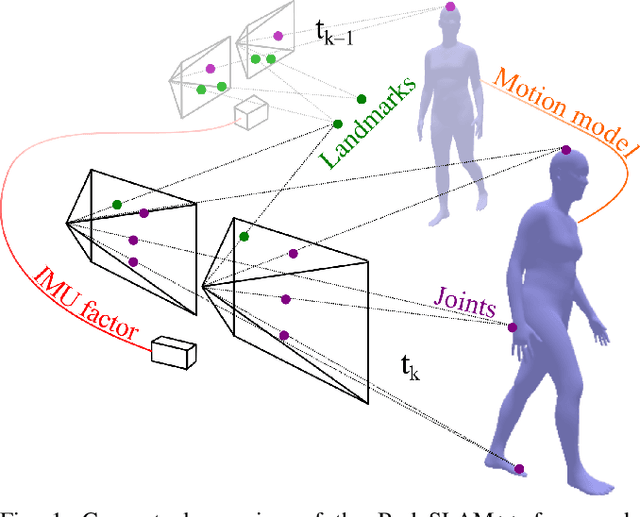
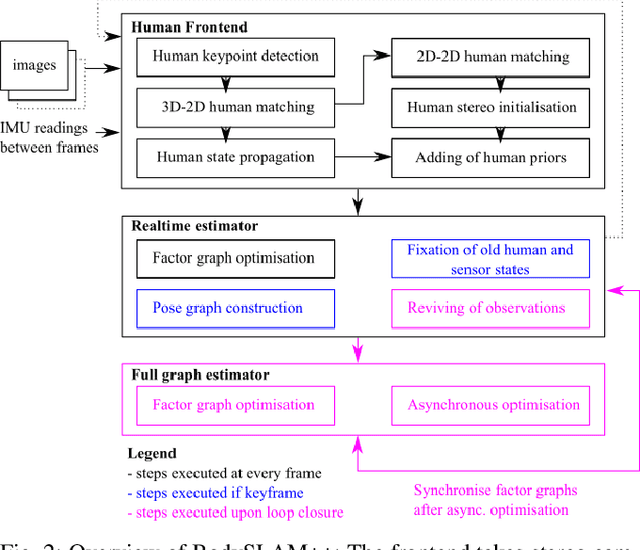
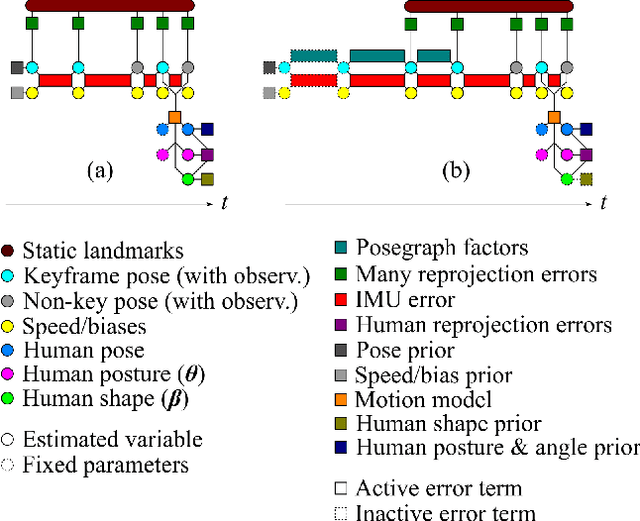

Robust, fast, and accurate human state - 6D pose and posture - estimation remains a challenging problem. For real-world applications, the ability to estimate the human state in real-time is highly desirable. In this paper, we present BodySLAM++, a fast, efficient, and accurate human and camera state estimation framework relying on visual-inertial data. BodySLAM++ extends an existing visual-inertial state estimation framework, OKVIS2, to solve the dual task of estimating camera and human states simultaneously. Our system improves the accuracy of both human and camera state estimation with respect to baseline methods by 26% and 12%, respectively, and achieves real-time performance at 15+ frames per second on an Intel i7-model CPU. Experiments were conducted on a custom dataset containing both ground truth human and camera poses collected with an indoor motion tracking system.
Int-HRL: Towards Intention-based Hierarchical Reinforcement Learning
Jun 20, 2023While deep reinforcement learning (RL) agents outperform humans on an increasing number of tasks, training them requires data equivalent to decades of human gameplay. Recent hierarchical RL methods have increased sample efficiency by incorporating information inherent to the structure of the decision problem but at the cost of having to discover or use human-annotated sub-goals that guide the learning process. We show that intentions of human players, i.e. the precursor of goal-oriented decisions, can be robustly predicted from eye gaze even for the long-horizon sparse rewards task of Montezuma's Revenge - one of the most challenging RL tasks in the Atari2600 game suite. We propose Int-HRL: Hierarchical RL with intention-based sub-goals that are inferred from human eye gaze. Our novel sub-goal extraction pipeline is fully automatic and replaces the need for manual sub-goal annotation by human experts. Our evaluations show that replacing hand-crafted sub-goals with automatically extracted intentions leads to a HRL agent that is significantly more sample efficient than previous methods.