 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperEvent: Cross-Modal Learning of Event-based Keypoint Detection
Mar 31, 2025
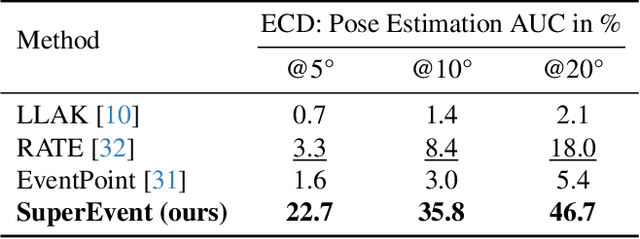
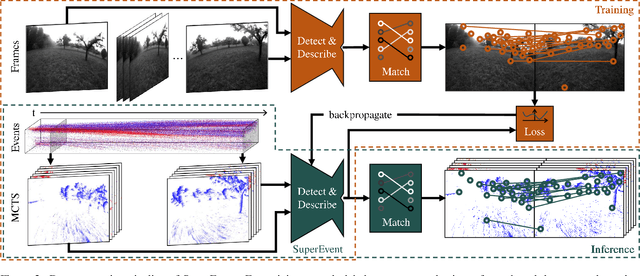
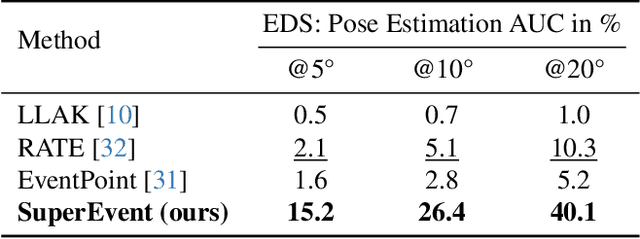
Event-based keypoint detection and matching holds significant potential, enabling the integration of event sensors into highly optimized Visual SLAM systems developed for frame cameras over decades of research. Unfortunately, existing approaches struggle with the motion-dependent appearance of keypoints and the complex noise prevalent in event streams, resulting in severely limited feature matching capabilities and poor performance on downstream tasks. To mitigate this problem, we propose SuperEvent, a data-driven approach to predict stable keypoints with expressive descriptors. Due to the absence of event datasets with ground truth keypoint labels, we leverage existing frame-based keypoint detectors on readily available event-aligned and synchronized gray-scale frames for self-supervision: we generate temporally sparse keypoint pseudo-labels considering that events are a product of both scene appearance and camera motion. Combined with our novel, information-rich event representation, we enable SuperEvent to effectively learn robust keypoint detection and description in event streams. Finally, we demonstrate the usefulness of SuperEvent by its integration into a modern sparse keypoint and descriptor-based SLAM framework originally developed for traditional cameras, surpassing the state-of-the-art in event-based SLAM by a wide margin. Source code and multimedia material are available at smartroboticslab.github.io/SuperEvent.
Dynamic Grasping of Unknown Objects with a Multi-Fingered Hand
Oct 27, 2023An important prerequisite for autonomous robots is their ability to reliably grasp a wide variety of objects. Most state-of-the-art systems employ specialized or simple end-effectors, such as two-jaw grippers, which severely limit the range of objects to manipulate. Additionally, they conventionally require a structured and fully predictable environment while the vast majority of our world is complex, unstructured, and dynamic. This paper presents an implementation to overcome both issues. Firstly, the integration of a five-finger hand enhances the variety of possible grasps and manipulable objects. This kinematically complex end-effector is controlled by a deep learning based generative grasping network. The required virtual model of the unknown target object is iteratively completed by processing visual sensor data. Secondly, this visual feedback is employed to realize closed-loop servo control which compensates for external disturbances. Our experiments on real hardware confirm the system's capability to reliably grasp unknown dynamic target objects without a priori knowledge of their trajectories. To the best of our knowledge, this is the first method to achieve dynamic multi-fingered grasping for unknown objects. A video of the experiments is available at https://youtu.be/Ut28yM1gnvI.