 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Partner Design Enables Robust Ad-hoc Teamwork
Aug 08, 2025We introduce Unsupervised Partner Design (UPD) - a population-free, multi-agent reinforcement learning framework for robust ad-hoc teamwork that adaptively generates training partners without requiring pretrained partners or manual parameter tuning. UPD constructs diverse partners by stochastically mixing an ego agent's policy with biased random behaviours and scores them using a variance-based learnability metric that prioritises partners near the ego agent's current learning frontier. We show that UPD can be integrated with unsupervised environment design, resulting in the first method enabling fully unsupervised curricula over both level and partner distributions in a cooperative setting. Through extensive evaluations on Overcooked-AI and the Overcooked Generalisation Challenge, we demonstrate that this dynamic partner curriculum is highly effective: UPD consistently outperforms both population-based and population-free baselines as well as ablations. In a user study, we further show that UPD achieves higher returns than all baselines and was perceived as significantly more adaptive, more human-like, a better collaborator, and less frustrating.
The Overcooked Generalisation Challenge
Jun 25, 2024We introduce the Overcooked Generalisation Challenge (OGC) - the first benchmark to study agents' zero-shot cooperation abilities when faced with novel partners and levels in the Overcooked-AI environment. This perspective starkly contrasts a large body of previous work that has trained and evaluated cooperating agents only on the same level, failing to capture generalisation abilities required for real-world human-AI cooperation. Our challenge interfaces with state-of-the-art dual curriculum design (DCD) methods to generate auto-curricula for training general agents in Overcooked. It is the first cooperative multi-agent environment specially designed for DCD methods and, consequently, the first benchmarked with state-of-the-art methods. It is fully GPU-accelerated, built on the DCD benchmark suite minimax, and freely available under an open-source license: https://git.hcics.simtech.uni-stuttgart.de/public-projects/OGC. We show that current DCD algorithms struggle to produce useful policies in this novel challenge, even if combined with recent network architectures that were designed for scalability and generalisability. The OGC pushes the boundaries of real-world human-AI cooperation by enabling the research community to study the impact of generalisation on cooperating agents.
VSA4VQA: Scaling a Vector Symbolic Architecture to Visual Question Answering on Natural Images
May 06, 2024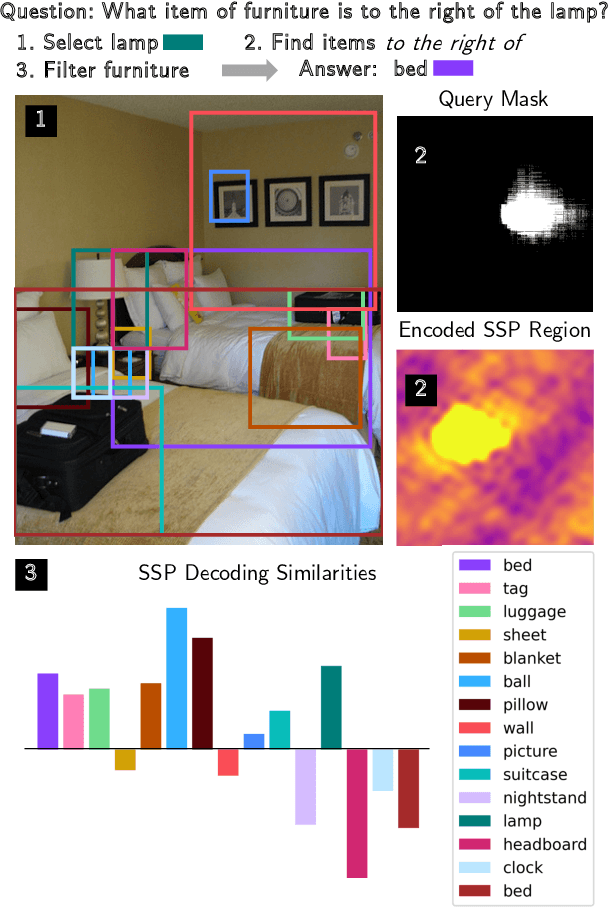



While Vector Symbolic Architectures (VSAs) are promising for modelling spatial cognition, their application is currently limited to artificially generated images and simple spatial queries. We propose VSA4VQA - a novel 4D implementation of VSAs that implements a mental representation of natural images for the challenging task of Visual Question Answering (VQA). VSA4VQA is the first model to scale a VSA to complex spatial queries. Our method is based on the Semantic Pointer Architecture (SPA) to encode objects in a hyperdimensional vector space. To encode natural images, we extend the SPA to include dimensions for object's width and height in addition to their spatial location. To perform spatial queries we further introduce learned spatial query masks and integrate a pre-trained vision-language model for answering attribute-related questions. We evaluate our method on the GQA benchmark dataset and show that it can effectively encode natural images, achieving competitive performance to state-of-the-art deep learning methods for zero-shot VQA.
Int-HRL: Towards Intention-based Hierarchical Reinforcement Learning
Jun 20, 2023While deep reinforcement learning (RL) agents outperform humans on an increasing number of tasks, training them requires data equivalent to decades of human gameplay. Recent hierarchical RL methods have increased sample efficiency by incorporating information inherent to the structure of the decision problem but at the cost of having to discover or use human-annotated sub-goals that guide the learning process. We show that intentions of human players, i.e. the precursor of goal-oriented decisions, can be robustly predicted from eye gaze even for the long-horizon sparse rewards task of Montezuma's Revenge - one of the most challenging RL tasks in the Atari2600 game suite. We propose Int-HRL: Hierarchical RL with intention-based sub-goals that are inferred from human eye gaze. Our novel sub-goal extraction pipeline is fully automatic and replaces the need for manual sub-goal annotation by human experts. Our evaluations show that replacing hand-crafted sub-goals with automatically extracted intentions leads to a HRL agent that is significantly more sample efficient than previous methods.