 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVSA4VQA: Scaling a Vector Symbolic Architecture to Visual Question Answering on Natural Images
Paper and Code
May 06, 2024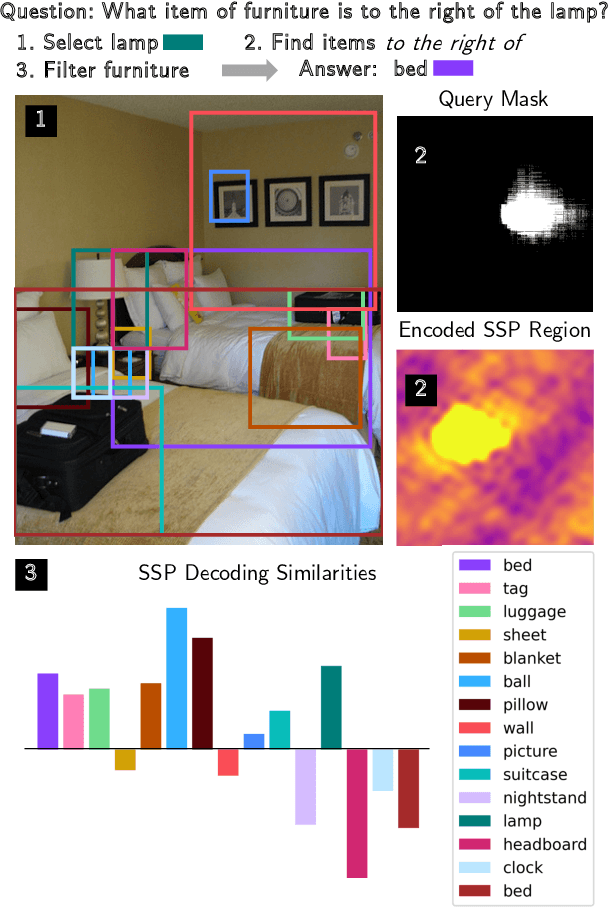



While Vector Symbolic Architectures (VSAs) are promising for modelling spatial cognition, their application is currently limited to artificially generated images and simple spatial queries. We propose VSA4VQA - a novel 4D implementation of VSAs that implements a mental representation of natural images for the challenging task of Visual Question Answering (VQA). VSA4VQA is the first model to scale a VSA to complex spatial queries. Our method is based on the Semantic Pointer Architecture (SPA) to encode objects in a hyperdimensional vector space. To encode natural images, we extend the SPA to include dimensions for object's width and height in addition to their spatial location. To perform spatial queries we further introduce learned spatial query masks and integrate a pre-trained vision-language model for answering attribute-related questions. We evaluate our method on the GQA benchmark dataset and show that it can effectively encode natural images, achieving competitive performance to state-of-the-art deep learning methods for zero-shot VQA.