 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeaderboard Incentives: Model Rankings under Strategic Post-Training
Mar 09, 2026Influential benchmarks incentivize competing model developers to strategically allocate post-training resources toward improvements on the leaderboard, a phenomenon dubbed benchmaxxing or training on the test task. In this work, we initiate a principled study of the incentive structure that benchmarks induce. We model benchmarking as a Stackelberg game between a benchmark designer who chooses an evaluation protocol and multiple model developers who compete simultaneously in a subgame given by the designer's choice. Each competitor has a model of unknown latent quality and can inflate its observed score by allocating resources to benchmark-specific improvements. First, we prove that current benchmarks induce games for which no Nash equilibrium between model developers exists. This result suggests one explanation for why current practice leads to misaligned incentives, prompting model developers to strategize in opaque ways. However, we prove that under mild conditions, a recently proposed evaluation protocol, called tune-before-test, induces a benchmark with a unique Nash equilibrium that ranks models by latent quality. This positive result demonstrates that benchmarks need not set bad incentives, even if current evaluations do.
World In Your Hands: A Large-Scale and Open-source Ecosystem for Learning Human-centric Manipulation in the Wild
Dec 30, 2025Large-scale pre-training is fundamental for generalization in language and vision models, but data for dexterous hand manipulation remains limited in scale and diversity, hindering policy generalization. Limited scenario diversity, misaligned modalities, and insufficient benchmarking constrain current human manipulation datasets. To address these gaps, we introduce World In Your Hands (WiYH), a large-scale open-source ecosystem for human-centric manipulation learning. WiYH includes (1) the Oracle Suite, a wearable data collection kit with an auto-labeling pipeline for accurate motion capture; (2) the WiYH Dataset, featuring over 1,000 hours of multi-modal manipulation data across hundreds of skills in diverse real-world scenarios; and (3) extensive annotations and benchmarks supporting tasks from perception to action. Furthermore, experiments based on the WiYH ecosystem show that integrating WiYH's human-centric data significantly enhances the generalization and robustness of dexterous hand policies in tabletop manipulation tasks. We believe that World In Your Hands will bring new insights into human-centric data collection and policy learning to the community.
How Benchmark Prediction from Fewer Data Misses the Mark
Jun 09, 2025



Large language model (LLM) evaluation is increasingly costly, prompting interest in methods that speed up evaluation by shrinking benchmark datasets. Benchmark prediction (also called efficient LLM evaluation) aims to select a small subset of evaluation points and predict overall benchmark performance from that subset. In this paper, we systematically assess the strengths and limitations of 11 benchmark prediction methods across 19 diverse benchmarks. First, we identify a highly competitive baseline: Take a random sample and fit a regression model on the sample to predict missing entries. Outperforming most existing methods, this baseline challenges the assumption that careful subset selection is necessary for benchmark prediction. Second, we discover that all existing methods crucially depend on model similarity. They work best when interpolating scores among similar models. The effectiveness of benchmark prediction sharply declines when new models have higher accuracy than previously seen models. In this setting of extrapolation, none of the previous methods consistently beat a simple average over random samples. To improve over the sample average, we introduce a new method inspired by augmented inverse propensity weighting. This method consistently outperforms the random sample average even for extrapolation. However, its performance still relies on model similarity and the gains are modest in general. This shows that benchmark prediction fails just when it is most needed: at the evaluation frontier, where the goal is to evaluate new models of unknown capabilities.
HaHeAE: Learning Generalisable Joint Representations of Human Hand and Head Movements in Extended Reality
Oct 21, 2024



Human hand and head movements are the most pervasive input modalities in extended reality (XR) and are significant for a wide range of applications. However, prior works on hand and head modelling in XR only explored a single modality or focused on specific applications. We present HaHeAE - a novel self-supervised method for learning generalisable joint representations of hand and head movements in XR. At the core of our method is an autoencoder (AE) that uses a graph convolutional network-based semantic encoder and a diffusion-based stochastic encoder to learn the joint semantic and stochastic representations of hand-head movements. It also features a diffusion-based decoder to reconstruct the original signals. Through extensive evaluations on three public XR datasets, we show that our method 1) significantly outperforms commonly used self-supervised methods by up to 74.0% in terms of reconstruction quality and is generalisable across users, activities, and XR environments, 2) enables new applications, including interpretable hand-head cluster identification and variable hand-head movement generation, and 3) can serve as an effective feature extractor for downstream tasks. Together, these results demonstrate the effectiveness of our method and underline the potential of self-supervised methods for jointly modelling hand-head behaviours in extended reality.
Inherent Trade-Offs between Diversity and Stability in Multi-Task Benchmarks
May 06, 2024
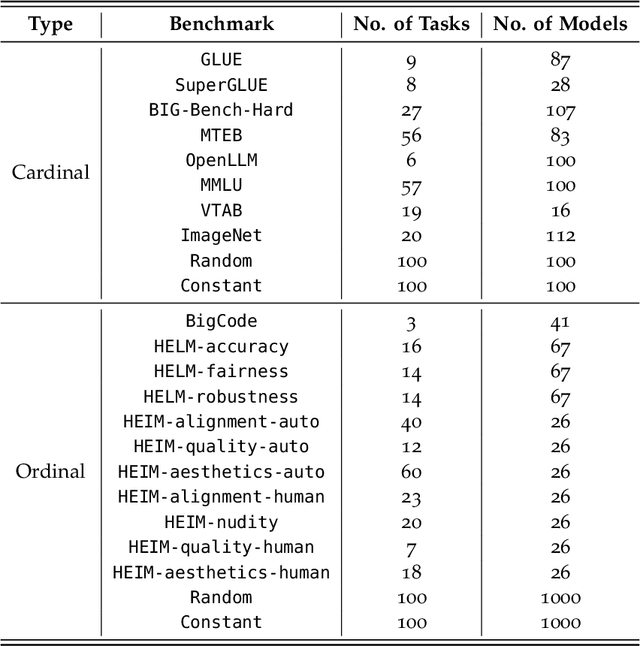
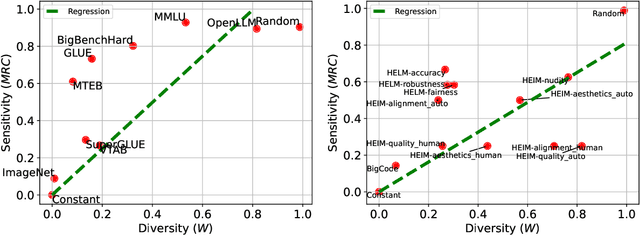
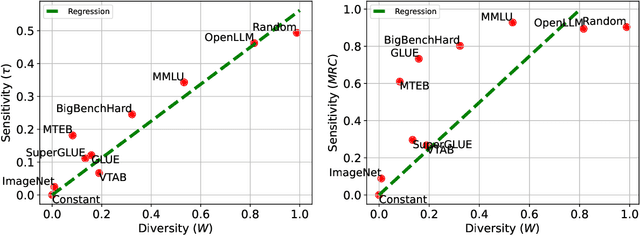
We examine multi-task benchmarks in machine learning through the lens of social choice theory. We draw an analogy between benchmarks and electoral systems, where models are candidates and tasks are voters. This suggests a distinction between cardinal and ordinal benchmark systems. The former aggregate numerical scores into one model ranking; the latter aggregate rankings for each task. We apply Arrow's impossibility theorem to ordinal benchmarks to highlight the inherent limitations of ordinal systems, particularly their sensitivity to the inclusion of irrelevant models. Inspired by Arrow's theorem, we empirically demonstrate a strong trade-off between diversity and sensitivity to irrelevant changes in existing multi-task benchmarks. Our result is based on new quantitative measures of diversity and sensitivity that we introduce. Sensitivity quantifies the impact that irrelevant changes to tasks have on a benchmark. Diversity captures the degree of disagreement in model rankings across tasks. We develop efficient approximation algorithms for both measures, as exact computation is computationally challenging. Through extensive experiments on seven cardinal benchmarks and eleven ordinal benchmarks, we demonstrate a clear trade-off between diversity and stability: The more diverse a multi-task benchmark, the more sensitive to trivial changes it is. Additionally, we show that the aggregated rankings of existing benchmarks are highly unstable under irrelevant changes. The codes and data are available at https://socialfoundations.github.io/benchbench/.
Advancing the Robustness of Large Language Models through Self-Denoised Smoothing
Apr 18, 2024



Although large language models (LLMs) have achieved significant success, their vulnerability to adversarial perturbations, including recent jailbreak attacks, has raised considerable concerns. However, the increasing size of these models and their limited access make improving their robustness a challenging task. Among various defense strategies, randomized smoothing has shown great potential for LLMs, as it does not require full access to the model's parameters or fine-tuning via adversarial training. However, randomized smoothing involves adding noise to the input before model prediction, and the final model's robustness largely depends on the model's performance on these noise corrupted data. Its effectiveness is often limited by the model's sub-optimal performance on noisy data. To address this issue, we propose to leverage the multitasking nature of LLMs to first denoise the noisy inputs and then to make predictions based on these denoised versions. We call this procedure self-denoised smoothing. Unlike previous denoised smoothing techniques in computer vision, which require training a separate model to enhance the robustness of LLMs, our method offers significantly better efficiency and flexibility. Our experimental results indicate that our method surpasses existing methods in both empirical and certified robustness in defending against adversarial attacks for both downstream tasks and human alignments (i.e., jailbreak attacks). Our code is publicly available at https://github.com/UCSB-NLP-Chang/SelfDenoise
DiffGaze: A Diffusion Model for Continuous Gaze Sequence Generation on 360° Images
Mar 26, 2024
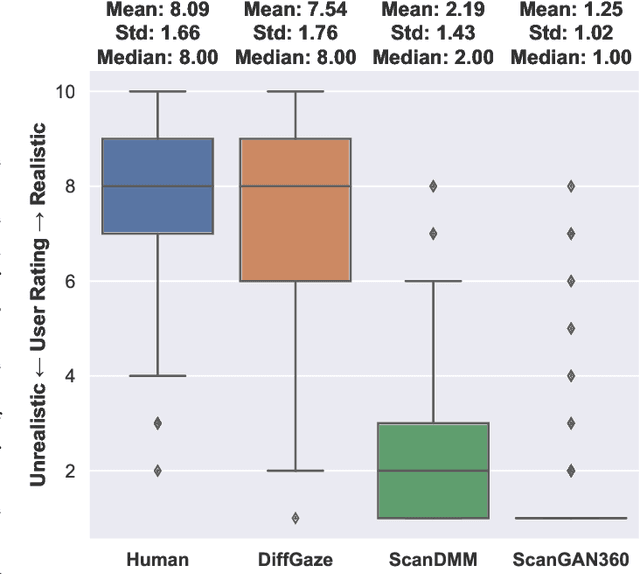


We present DiffGaze, a novel method for generating realistic and diverse continuous human gaze sequences on 360{\deg} images based on a conditional score-based denoising diffusion model. Generating human gaze on 360{\deg} images is important for various human-computer interaction and computer graphics applications, e.g. for creating large-scale eye tracking datasets or for realistic animation of virtual humans. However, existing methods are limited to predicting discrete fixation sequences or aggregated saliency maps, thereby neglecting crucial parts of natural gaze behaviour. Our method uses features extracted from 360{\deg} images as condition and uses two transformers to model the temporal and spatial dependencies of continuous human gaze. We evaluate DiffGaze on two 360{\deg} image benchmarks for gaze sequence generation as well as scanpath prediction and saliency prediction. Our evaluations show that DiffGaze outperforms state-of-the-art methods on all tasks on both benchmarks. We also report a 21-participant user study showing that our method generates gaze sequences that are indistinguishable from real human sequences.
Robust Mixture-of-Expert Training for Convolutional Neural Networks
Aug 19, 2023Sparsely-gated Mixture of Expert (MoE), an emerging deep model architecture, has demonstrated a great promise to enable high-accuracy and ultra-efficient model inference. Despite the growing popularity of MoE, little work investigated its potential to advance convolutional neural networks (CNNs), especially in the plane of adversarial robustness. Since the lack of robustness has become one of the main hurdles for CNNs, in this paper we ask: How to adversarially robustify a CNN-based MoE model? Can we robustly train it like an ordinary CNN model? Our pilot study shows that the conventional adversarial training (AT) mechanism (developed for vanilla CNNs) no longer remains effective to robustify an MoE-CNN. To better understand this phenomenon, we dissect the robustness of an MoE-CNN into two dimensions: Robustness of routers (i.e., gating functions to select data-specific experts) and robustness of experts (i.e., the router-guided pathways defined by the subnetworks of the backbone CNN). Our analyses show that routers and experts are hard to adapt to each other in the vanilla AT. Thus, we propose a new router-expert alternating Adversarial training framework for MoE, termed AdvMoE. The effectiveness of our proposal is justified across 4 commonly-used CNN model architectures over 4 benchmark datasets. We find that AdvMoE achieves 1% ~ 4% adversarial robustness improvement over the original dense CNN, and enjoys the efficiency merit of sparsity-gated MoE, leading to more than 50% inference cost reduction. Codes are available at https://github.com/OPTML-Group/Robust-MoE-CNN.
Certified Robustness for Large Language Models with Self-Denoising
Jul 14, 2023Although large language models (LLMs) have achieved great success in vast real-world applications, their vulnerabilities towards noisy inputs have significantly limited their uses, especially in high-stake environments. In these contexts, it is crucial to ensure that every prediction made by large language models is stable, i.e., LLM predictions should be consistent given minor differences in the input. This largely falls into the study of certified robust LLMs, i.e., all predictions of LLM are certified to be correct in a local region around the input. Randomized smoothing has demonstrated great potential in certifying the robustness and prediction stability of LLMs. However, randomized smoothing requires adding noise to the input before model prediction, and its certification performance depends largely on the model's performance on corrupted data. As a result, its direct application to LLMs remains challenging and often results in a small certification radius. To address this issue, we take advantage of the multitasking nature of LLMs and propose to denoise the corrupted inputs with LLMs in a self-denoising manner. Different from previous works like denoised smoothing, which requires training a separate model to robustify LLM, our method enjoys far better efficiency and flexibility. Our experiment results show that our method outperforms the existing certification methods under both certified robustness and empirical robustness. The codes are available at https://github.com/UCSB-NLP-Chang/SelfDenoise.
Improving Diffusion Models for Scene Text Editing with Dual Encoders
Apr 12, 2023
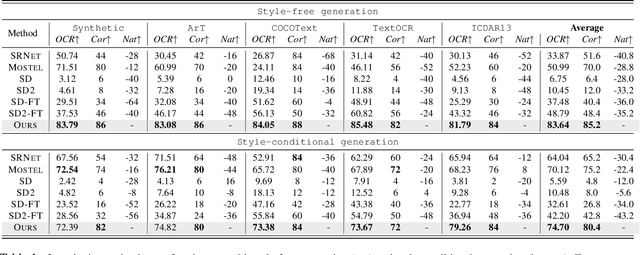


Scene text editing is a challenging task that involves modifying or inserting specified texts in an image while maintaining its natural and realistic appearance. Most previous approaches to this task rely on style-transfer models that crop out text regions and feed them into image transfer models, such as GANs. However, these methods are limited in their ability to change text style and are unable to insert texts into images. Recent advances in diffusion models have shown promise in overcoming these limitations with text-conditional image editing. However, our empirical analysis reveals that state-of-the-art diffusion models struggle with rendering correct text and controlling text style. To address these problems, we propose DIFFSTE to improve pre-trained diffusion models with a dual encoder design, which includes a character encoder for better text legibility and an instruction encoder for better style control. An instruction tuning framework is introduced to train our model to learn the mapping from the text instruction to the corresponding image with either the specified style or the style of the surrounding texts in the background. Such a training method further brings our method the zero-shot generalization ability to the following three scenarios: generating text with unseen font variation, e.g., italic and bold, mixing different fonts to construct a new font, and using more relaxed forms of natural language as the instructions to guide the generation task. We evaluate our approach on five datasets and demonstrate its superior performance in terms of text correctness, image naturalness, and style controllability. Our code is publicly available. https://github.com/UCSB-NLP-Chang/DiffSTE