 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBurstGP: Enhancing Raw Burst Image Super Resolution with Generative Priors
Apr 26, 2026Burst image super resolution (BISR) aims to construct a single high-resolution (HR) image by aggregating information from multiple low-resolution (LR) frames, relying on temporal redundancy and spatial coherence across the burst. While conventional methods achieve impressive results, they often struggle with complex textures and oversmoothing. Diffusion models, particularly those pretrained on high-quality data, have shown remarkable capability in generating realistic details for image and video super-resolution. However, their potential remains largely under-explored in BISR, where existing approaches typically rely on task-specific diffusion models trained from scratch and operate on single-frame reconstructions. In this work, we propose BurstGP, a novel diffusion-based solution for BISR, which leverages generative priors of recent foundation models to overcome these issues. In particular, we build a multiframe-aware diffusion model on top of a conventional BISR approach, which boosts image quality with minimal loss to fidelity. Further, we introduce (i) a novel degradation-aware conditioning mechanism, which controls synthesis of fine details based on the estimated degradation in the input, and (ii) a robust sRGB-to-lRGB inverter, enabling us to utilize generative multiframe (video) sRGB priors, while operating with raw input and lRGB output images. Empirically, we demonstrate that BurstGP outperforms the existing state of the art, both quantitatively (especially with respect to perceptual metrics, including MUSIQ and LPIPS) and qualitatively. In particular, our proposed method excels at recovering richer textures and finer structural details, highlighting the potential of video priors for BISR over traditional methods.
HOIGaze: Gaze Estimation During Hand-Object Interactions in Extended Reality Exploiting Eye-Hand-Head Coordination
Apr 28, 2025We present HOIGaze - a novel learning-based approach for gaze estimation during hand-object interactions (HOI) in extended reality (XR). HOIGaze addresses the challenging HOI setting by building on one key insight: The eye, hand, and head movements are closely coordinated during HOIs and this coordination can be exploited to identify samples that are most useful for gaze estimator training - as such, effectively denoising the training data. This denoising approach is in stark contrast to previous gaze estimation methods that treated all training samples as equal. Specifically, we propose: 1) a novel hierarchical framework that first recognises the hand currently visually attended to and then estimates gaze direction based on the attended hand; 2) a new gaze estimator that uses cross-modal Transformers to fuse head and hand-object features extracted using a convolutional neural network and a spatio-temporal graph convolutional network; and 3) a novel eye-head coordination loss that upgrades training samples belonging to the coordinated eye-head movements. We evaluate HOIGaze on the HOT3D and Aria digital twin (ADT) datasets and show that it significantly outperforms state-of-the-art methods, achieving an average improvement of 15.6% on HOT3D and 6.0% on ADT in mean angular error. To demonstrate the potential of our method, we further report significant performance improvements for the sample downstream task of eye-based activity recognition on ADT. Taken together, our results underline the significant information content available in eye-hand-head coordination and, as such, open up an exciting new direction for learning-based gaze estimation.
HaHeAE: Learning Generalisable Joint Representations of Human Hand and Head Movements in Extended Reality
Oct 21, 2024



Human hand and head movements are the most pervasive input modalities in extended reality (XR) and are significant for a wide range of applications. However, prior works on hand and head modelling in XR only explored a single modality or focused on specific applications. We present HaHeAE - a novel self-supervised method for learning generalisable joint representations of hand and head movements in XR. At the core of our method is an autoencoder (AE) that uses a graph convolutional network-based semantic encoder and a diffusion-based stochastic encoder to learn the joint semantic and stochastic representations of hand-head movements. It also features a diffusion-based decoder to reconstruct the original signals. Through extensive evaluations on three public XR datasets, we show that our method 1) significantly outperforms commonly used self-supervised methods by up to 74.0% in terms of reconstruction quality and is generalisable across users, activities, and XR environments, 2) enables new applications, including interpretable hand-head cluster identification and variable hand-head movement generation, and 3) can serve as an effective feature extractor for downstream tasks. Together, these results demonstrate the effectiveness of our method and underline the potential of self-supervised methods for jointly modelling hand-head behaviours in extended reality.
HOIMotion: Forecasting Human Motion During Human-Object Interactions Using Egocentric 3D Object Bounding Boxes
Jul 02, 2024



We present HOIMotion - a novel approach for human motion forecasting during human-object interactions that integrates information about past body poses and egocentric 3D object bounding boxes. Human motion forecasting is important in many augmented reality applications but most existing methods have only used past body poses to predict future motion. HOIMotion first uses an encoder-residual graph convolutional network (GCN) and multi-layer perceptrons to extract features from body poses and egocentric 3D object bounding boxes, respectively. Our method then fuses pose and object features into a novel pose-object graph and uses a residual-decoder GCN to forecast future body motion. We extensively evaluate our method on the Aria digital twin (ADT) and MoGaze datasets and show that HOIMotion consistently outperforms state-of-the-art methods by a large margin of up to 8.7% on ADT and 7.2% on MoGaze in terms of mean per joint position error. Complementing these evaluations, we report a human study (N=20) that shows that the improvements achieved by our method result in forecasted poses being perceived as both more precise and more realistic than those of existing methods. Taken together, these results reveal the significant information content available in egocentric 3D object bounding boxes for human motion forecasting and the effectiveness of our method in exploiting this information.
DiffGaze: A Diffusion Model for Continuous Gaze Sequence Generation on 360° Images
Mar 26, 2024
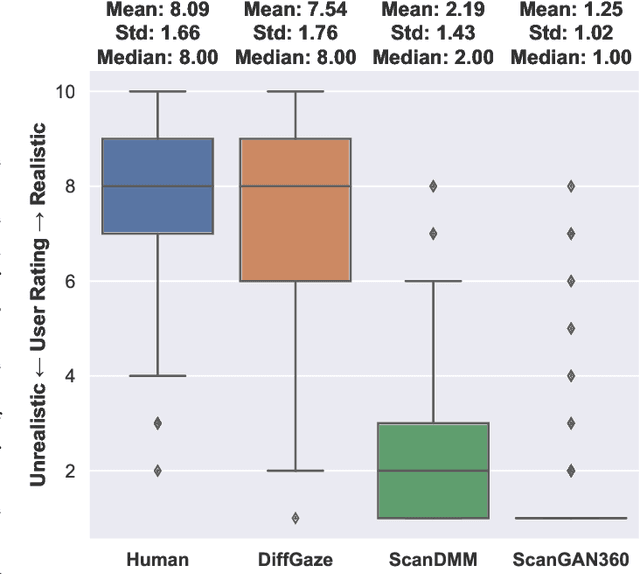


We present DiffGaze, a novel method for generating realistic and diverse continuous human gaze sequences on 360{\deg} images based on a conditional score-based denoising diffusion model. Generating human gaze on 360{\deg} images is important for various human-computer interaction and computer graphics applications, e.g. for creating large-scale eye tracking datasets or for realistic animation of virtual humans. However, existing methods are limited to predicting discrete fixation sequences or aggregated saliency maps, thereby neglecting crucial parts of natural gaze behaviour. Our method uses features extracted from 360{\deg} images as condition and uses two transformers to model the temporal and spatial dependencies of continuous human gaze. We evaluate DiffGaze on two 360{\deg} image benchmarks for gaze sequence generation as well as scanpath prediction and saliency prediction. Our evaluations show that DiffGaze outperforms state-of-the-art methods on all tasks on both benchmarks. We also report a 21-participant user study showing that our method generates gaze sequences that are indistinguishable from real human sequences.
GazeMotion: Gaze-guided Human Motion Forecasting
Mar 14, 2024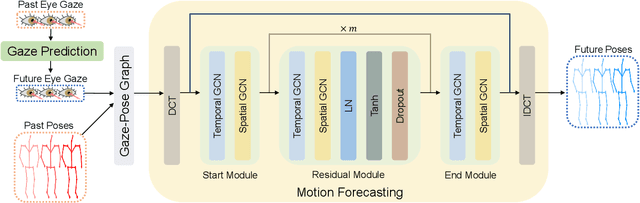
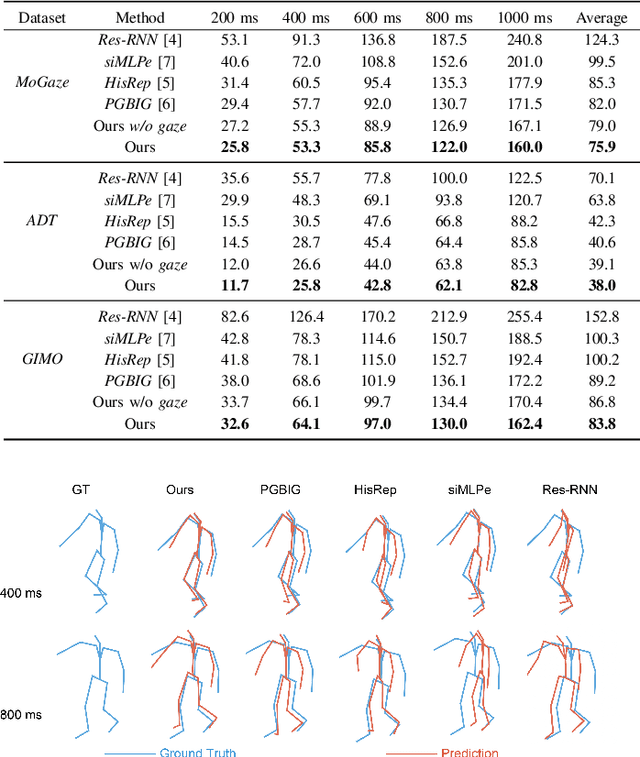
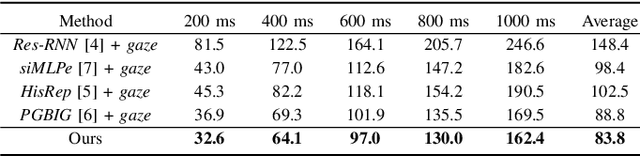
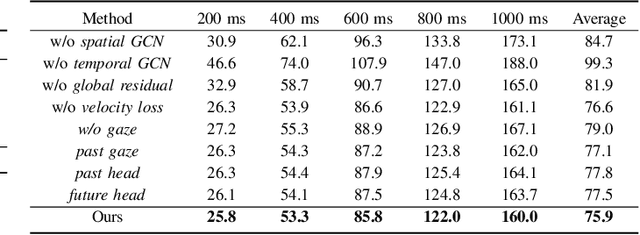
We present GazeMotion, a novel method for human motion forecasting that combines information on past human poses with human eye gaze. Inspired by evidence from behavioural sciences showing that human eye and body movements are closely coordinated, GazeMotion first predicts future eye gaze from past gaze, then fuses predicted future gaze and past poses into a gaze-pose graph, and finally uses a residual graph convolutional network to forecast body motion. We extensively evaluate our method on the MoGaze, ADT, and GIMO benchmark datasets and show that it outperforms state-of-the-art methods by up to 7.4% improvement in mean per joint position error. Using head direction as a proxy to gaze, our method still achieves an average improvement of 5.5%. We finally report an online user study showing that our method also outperforms prior methods in terms of perceived realism. These results show the significant information content available in eye gaze for human motion forecasting as well as the effectiveness of our method in exploiting this information.
PrivatEyes: Appearance-based Gaze Estimation Using Federated Secure Multi-Party Computation
Feb 29, 2024



Latest gaze estimation methods require large-scale training data but their collection and exchange pose significant privacy risks. We propose PrivatEyes - the first privacy-enhancing training approach for appearance-based gaze estimation based on federated learning (FL) and secure multi-party computation (MPC). PrivatEyes enables training gaze estimators on multiple local datasets across different users and server-based secure aggregation of the individual estimators' updates. PrivatEyes guarantees that individual gaze data remains private even if a majority of the aggregating servers is malicious. We also introduce a new data leakage attack DualView that shows that PrivatEyes limits the leakage of private training data more effectively than previous approaches. Evaluations on the MPIIGaze, MPIIFaceGaze, GazeCapture, and NVGaze datasets further show that the improved privacy does not lead to a lower gaze estimation accuracy or substantially higher computational costs - both of which are on par with its non-secure counterparts.
Pose2Gaze: Generating Realistic Human Gaze Behaviour from Full-body Poses using an Eye-body Coordination Model
Dec 19, 2023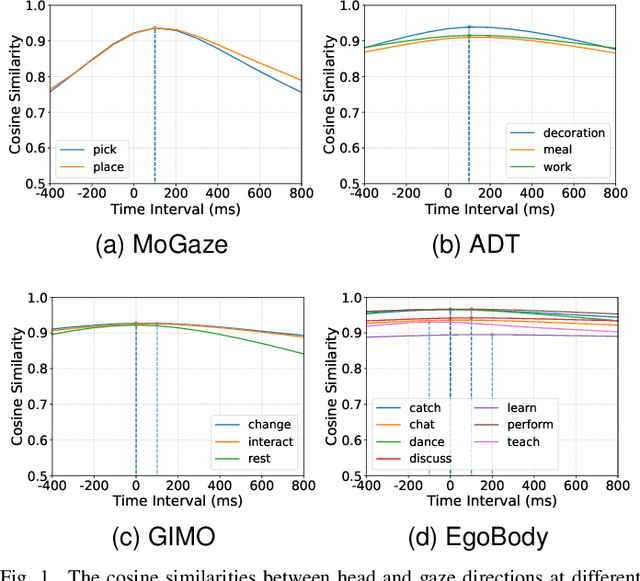
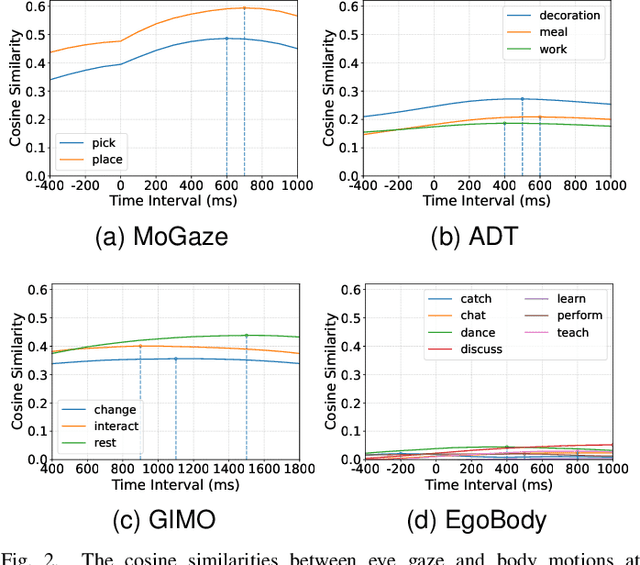
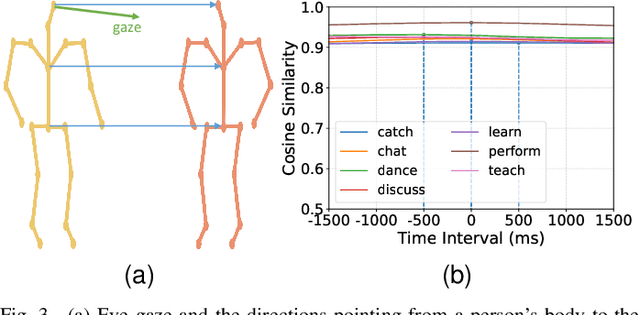
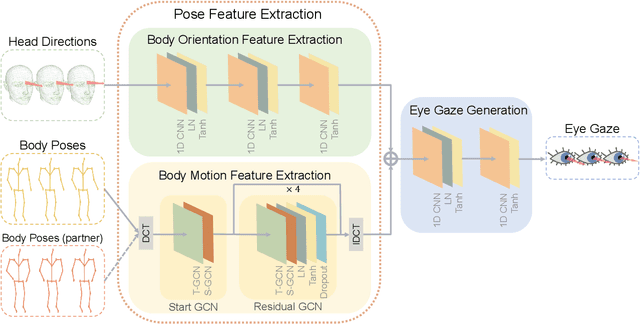
While generating realistic body movements, e.g., for avatars in virtual reality, is widely studied in computer vision and graphics, the generation of eye movements that exhibit realistic coordination with the body remains under-explored. We first report a comprehensive analysis of the coordination of human eye and full-body movements during everyday activities based on data from the MoGaze and GIMO datasets. We show that eye gaze has strong correlations with head directions and also full-body motions and there exists a noticeable time delay between body and eye movements. Inspired by the analyses, we then present Pose2Gaze -- a novel eye-body coordination model that first uses a convolutional neural network and a spatio-temporal graph convolutional neural network to extract features from head directions and full-body poses respectively and then applies a convolutional neural network to generate realistic eye movements. We compare our method with state-of-the-art methods that predict eye gaze only from head movements for three different generation tasks and demonstrate that Pose2Gaze significantly outperforms these baselines on both datasets with an average improvement of 26.4% and 21.6% in mean angular error, respectively. Our findings underline the significant potential of cross-modal human gaze behaviour analysis and modelling.
GazeMoDiff: Gaze-guided Diffusion Model for Stochastic Human Motion Prediction
Dec 19, 2023



Human motion prediction is important for virtual reality (VR) applications, e.g., for realistic avatar animation. Existing methods have synthesised body motion only from observed past motion, despite the fact that human gaze is known to correlate strongly with body movements and is readily available in recent VR headsets. We present GazeMoDiff -- a novel gaze-guided denoising diffusion model to generate stochastic human motions. Our method first uses a graph attention network to learn the spatio-temporal correlations between eye gaze and human movements and to fuse them into cross-modal gaze-motion features. These cross-modal features are injected into a noise prediction network via a cross-attention mechanism and progressively denoised to generate realistic human full-body motions. Experimental results on the MoGaze and GIMO datasets demonstrate that our method outperforms the state-of-the-art methods by a large margin in terms of average displacement error (15.03% on MoGaze and 9.20% on GIMO). We further conducted an online user study to compare our method with state-of-the-art methods and the responses from 23 participants validate that the motions generated by our method are more realistic than those from other methods. Taken together, our work makes a first important step towards gaze-guided stochastic human motion prediction and guides future work on this important topic in VR research.
A Survey : Neural Networks for AMR-to-Text
Jun 15, 2022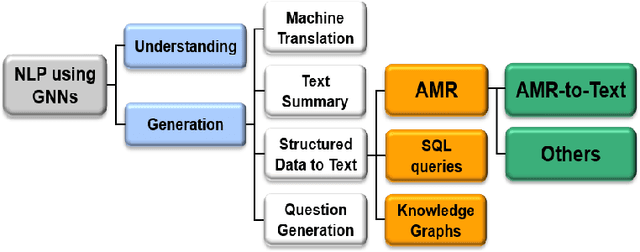
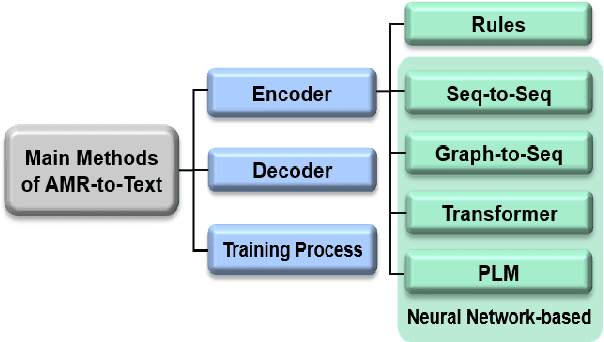
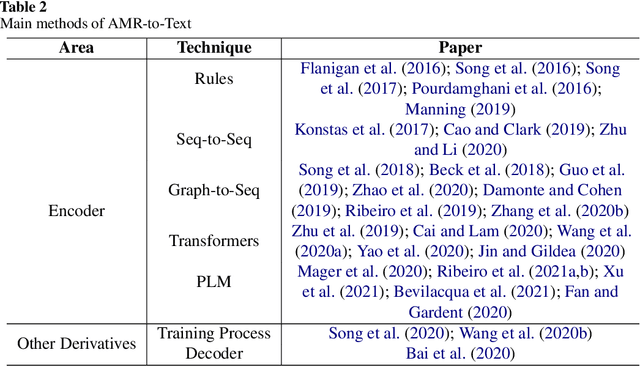
AMR-to-text is one of the key techniques in the NLP community that aims at generating sentences from the Abstract Meaning Representation (AMR) graphs. Since AMR was proposed in 2013, the study on AMR-to-Text has become increasingly prevalent as an essential branch of structured data to text because of the unique advantages of AMR as a high-level semantic description of natural language. In this paper, we provide a brief survey of AMR-to-Text. Firstly, we introduce the current scenario of this technique and point out its difficulties. Secondly, based on the methods used in previous studies, we roughly divided them into five categories according to their respective mechanisms, i.e., Rules-based, Seq-to-Seq-based, Graph-to-Seq-based, Transformer-based, and Pre-trained Language Model (PLM)-based. In particular, we detail the neural network-based method and present the latest progress of AMR-to-Text, which refers to AMR reconstruction, Decoder optimization, etc. Furthermore, we present the benchmarks and evaluation methods of AMR-to-Text. Eventually, we provide a summary of current techniques and the outlook for future research.