 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Patent Retrieval using Text and Knowledge Graph Embeddings: A Technical Note
Nov 03, 2022Patent retrieval influences several applications within engineering design research, education, and practice as well as applications that concern innovation, intellectual property, and knowledge management etc. In this article, we propose a method to retrieve patents relevant to an initial set of patents, by synthesizing state-of-the-art techniques among natural language processing and knowledge graph embedding. Our method involves a patent embedding that captures text, citation, and inventor information, which individually represent different facets of knowledge communicated through a patent document. We obtain text embeddings using Sentence-BERT applied to titles and abstracts. We obtain citation and inventor embeddings through TransE that is trained using the corresponding knowledge graphs. We identify using a classification task that the concatenation of text, citation, and inventor embeddings offers a plausible representation of a patent. While the proposed patent embedding could be used to associate a pair of patents, we observe using a recall task that multiple initial patents could be associated with a target patent using mean cosine similarity, which could then be utilized to rank all target patents and retrieve the most relevant ones. We apply the proposed patent retrieval method to a set of patents corresponding to a product family and an inventor's portfolio.
Embedding Knowledge Graph of Patent Metadata to Measure Knowledge Proximity
Nov 03, 2022Knowledge proximity refers to the strength of association between any two entities in a structural form that embodies certain aspects of a knowledge base. In this work, we operationalize knowledge proximity within the context of the US Patent Database (knowledge base) using a knowledge graph (structural form) named PatNet built using patent metadata, including citations, inventors, assignees, and domain classifications. Using several graph embedding models (e.g., TransE, RESCAL), we obtain the embeddings of entities and relations that constitute PatNet. The cosine similarity between the corresponding (or transformed) embeddings entities denotes the knowledge proximity between these. We evaluate the plausibility of these embeddings across different models in predicting target entities. We also evaluate the meaningfulness of knowledge proximity to explain the domain expansion profiles of inventors and assignees. We then apply the embeddings of the best-preferred model to associate homogeneous (e.g., patent-patent) and heterogeneous (e.g., inventor-assignee) pairs of entities.
A Survey : Neural Networks for AMR-to-Text
Jun 15, 2022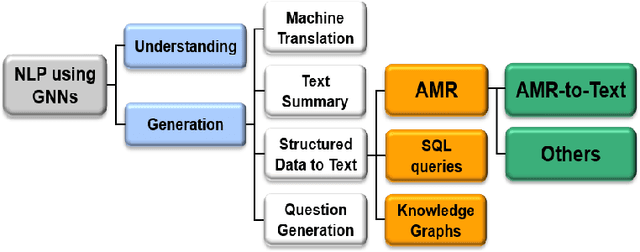
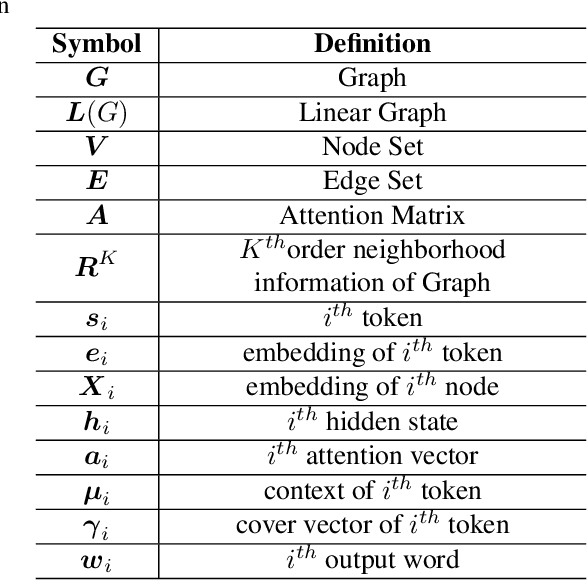
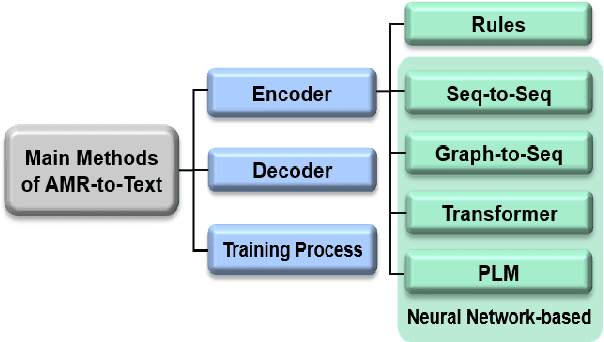
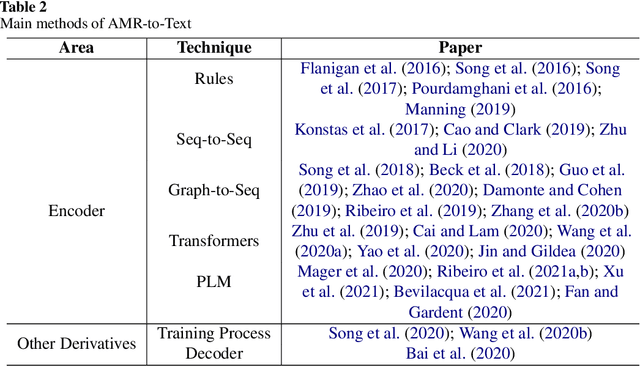
AMR-to-text is one of the key techniques in the NLP community that aims at generating sentences from the Abstract Meaning Representation (AMR) graphs. Since AMR was proposed in 2013, the study on AMR-to-Text has become increasingly prevalent as an essential branch of structured data to text because of the unique advantages of AMR as a high-level semantic description of natural language. In this paper, we provide a brief survey of AMR-to-Text. Firstly, we introduce the current scenario of this technique and point out its difficulties. Secondly, based on the methods used in previous studies, we roughly divided them into five categories according to their respective mechanisms, i.e., Rules-based, Seq-to-Seq-based, Graph-to-Seq-based, Transformer-based, and Pre-trained Language Model (PLM)-based. In particular, we detail the neural network-based method and present the latest progress of AMR-to-Text, which refers to AMR reconstruction, Decoder optimization, etc. Furthermore, we present the benchmarks and evaluation methods of AMR-to-Text. Eventually, we provide a summary of current techniques and the outlook for future research.