 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Populating Generalizable Engineering Design Knowledge
Jul 13, 2023Aiming to populate generalizable engineering design knowledge, we propose a method to extract facts of the form head entity :: relationship :: tail entity from sentences found in patent documents. These facts could be combined within and across patent documents to form knowledge graphs that serve as schemes for representing as well as storing design knowledge. Existing methods in engineering design literature often utilise a set of predefined relationships to populate triples that are statistical approximations rather than facts. In our method, we train a tagger to identify both entities and relationships from a sentence. Given a pair of entities thus identified, we train another tagger to identify the relationship tokens that specifically denote the relationship between the pair. For training these taggers, we manually construct a dataset of 44,227 sentences and corresponding facts. We also compare the performance of the method against typically recommended approaches, wherein, we predict the edges among tokens by pairing the tokens independently and as part of a graph. We apply our method to sentences found in patents related to fan systems and build a domain knowledge base. Upon providing an overview of the knowledge base, we search for solutions relevant to some key issues prevailing in fan systems. We organize the responses into knowledge graphs and hold a comparative discussion against the opinions from ChatGPT.
Enhancing Patent Retrieval using Text and Knowledge Graph Embeddings: A Technical Note
Nov 03, 2022Patent retrieval influences several applications within engineering design research, education, and practice as well as applications that concern innovation, intellectual property, and knowledge management etc. In this article, we propose a method to retrieve patents relevant to an initial set of patents, by synthesizing state-of-the-art techniques among natural language processing and knowledge graph embedding. Our method involves a patent embedding that captures text, citation, and inventor information, which individually represent different facets of knowledge communicated through a patent document. We obtain text embeddings using Sentence-BERT applied to titles and abstracts. We obtain citation and inventor embeddings through TransE that is trained using the corresponding knowledge graphs. We identify using a classification task that the concatenation of text, citation, and inventor embeddings offers a plausible representation of a patent. While the proposed patent embedding could be used to associate a pair of patents, we observe using a recall task that multiple initial patents could be associated with a target patent using mean cosine similarity, which could then be utilized to rank all target patents and retrieve the most relevant ones. We apply the proposed patent retrieval method to a set of patents corresponding to a product family and an inventor's portfolio.
Embedding Knowledge Graph of Patent Metadata to Measure Knowledge Proximity
Nov 03, 2022Knowledge proximity refers to the strength of association between any two entities in a structural form that embodies certain aspects of a knowledge base. In this work, we operationalize knowledge proximity within the context of the US Patent Database (knowledge base) using a knowledge graph (structural form) named PatNet built using patent metadata, including citations, inventors, assignees, and domain classifications. Using several graph embedding models (e.g., TransE, RESCAL), we obtain the embeddings of entities and relations that constitute PatNet. The cosine similarity between the corresponding (or transformed) embeddings entities denotes the knowledge proximity between these. We evaluate the plausibility of these embeddings across different models in predicting target entities. We also evaluate the meaningfulness of knowledge proximity to explain the domain expansion profiles of inventors and assignees. We then apply the embeddings of the best-preferred model to associate homogeneous (e.g., patent-patent) and heterogeneous (e.g., inventor-assignee) pairs of entities.
Natural Language Processing in-and-for Design Research
Nov 27, 2021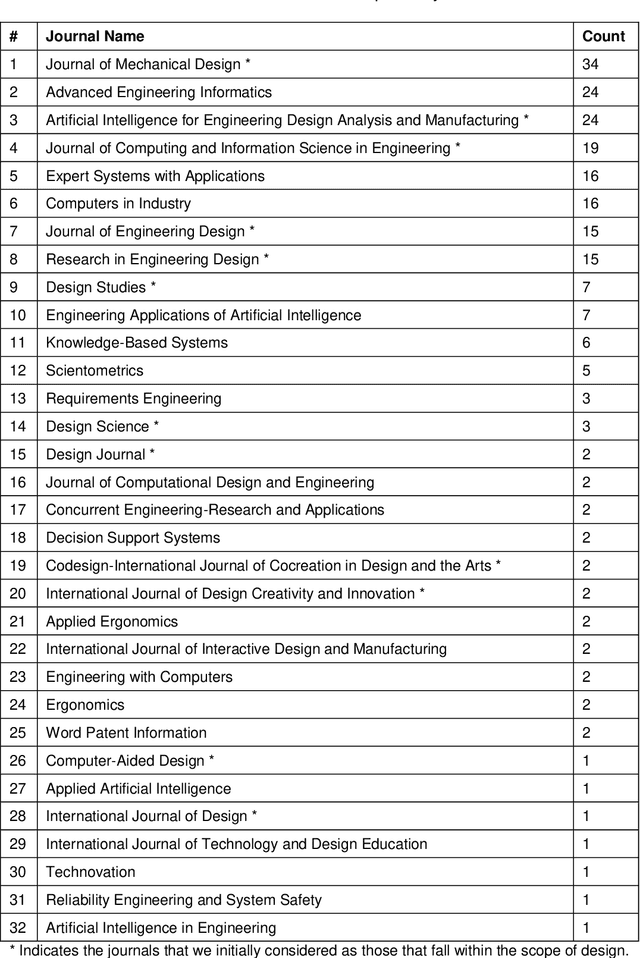
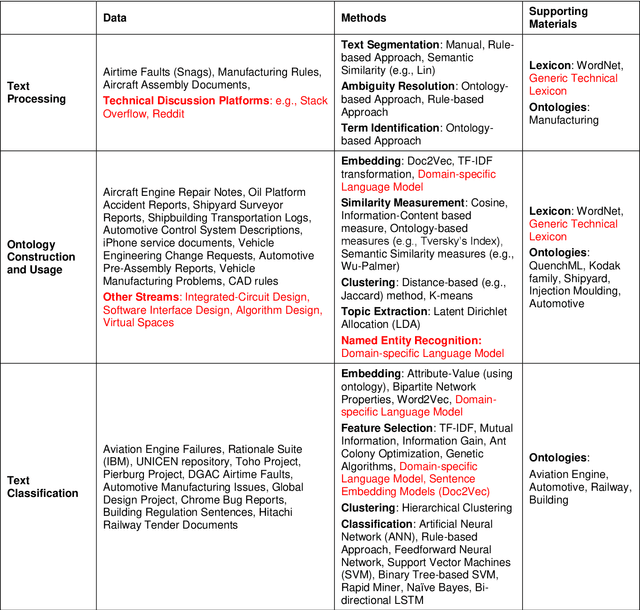
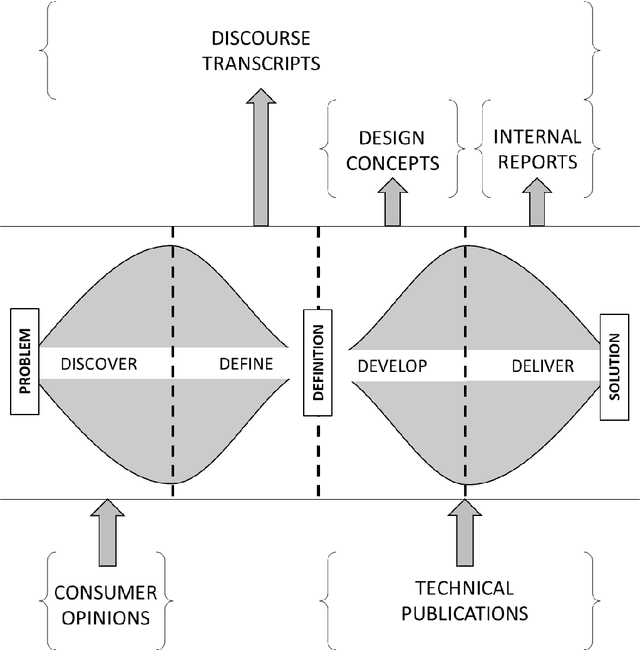
We review the scholarly contributions that utilise Natural Language Processing (NLP) methods to support the design process. Using a heuristic approach, we collected 223 articles published in 32 journals and within the period 1991-present. We present state-of-the-art NLP in-and-for design research by reviewing these articles according to the type of natural language text sources: internal reports, design concepts, discourse transcripts, technical publications, consumer opinions, and others. Upon summarizing and identifying the gaps in these contributions, we utilise an existing design innovation framework to identify the applications that are currently being supported by NLP. We then propose a few methodological and theoretical directions for future NLP in-and-for design research.
Engineering Knowledge Graph from Patent Database
Jun 12, 2021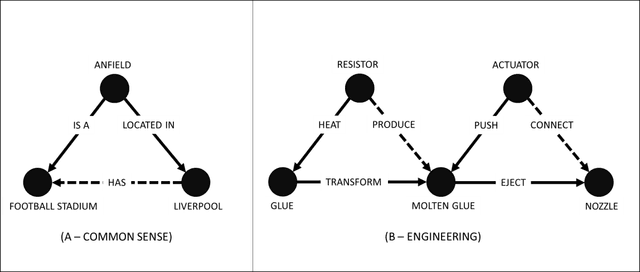

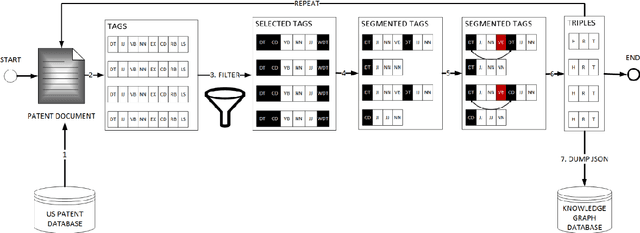
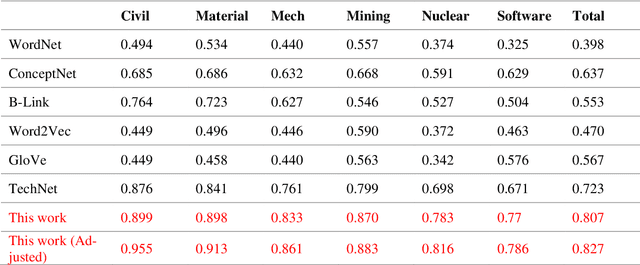
We propose a large, scalable engineering knowledge graph, comprising sets of (entity, relationship, entity) triples that are real-world engineering facts found in the patent database. We apply a set of rules based on the syntactic and lexical properties of claims in a patent document to extract facts. We aggregate these facts within each patent document and integrate the aggregated sets of facts across the patent database to obtain the engineering knowledge graph. Such a knowledge graph is expected to support inference, reasoning, and recalling in various engineering tasks. The knowledge graph has a greater size and coverage in comparison with the previously used knowledge graphs and semantic networks in the engineering literature.