 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Group Utility in Itinerary Planning: A Strategic and Crowd-Aware Approach
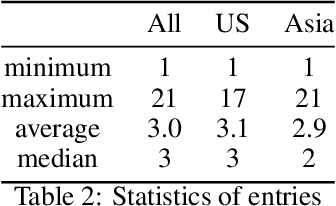
Apr 20, 2023Itinerary recommendation is a complex sequence prediction problem with numerous real-world applications. This task becomes even more challenging when considering the optimization of multiple user queuing times and crowd levels, as well as numerous involved parameters, such as attraction popularity, queuing time, walking time, and operating hours. Existing solutions typically focus on single-person perspectives and fail to address real-world issues resulting from natural crowd behavior, like the Selfish Routing problem. In this paper, we introduce the Strategic and Crowd-Aware Itinerary Recommendation (SCAIR) algorithm, which optimizes group utility in real-world settings. We model the route recommendation strategy as a Markov Decision Process and propose a State Encoding mechanism that enables real-time planning and allocation in linear time. We evaluate our algorithm against various competitive and realistic baselines using a theme park dataset, demonstrating that SCAIR outperforms these baselines in addressing the Selfish Routing problem across four theme parks.
Engineering Knowledge Graph from Patent Database
Jun 12, 2021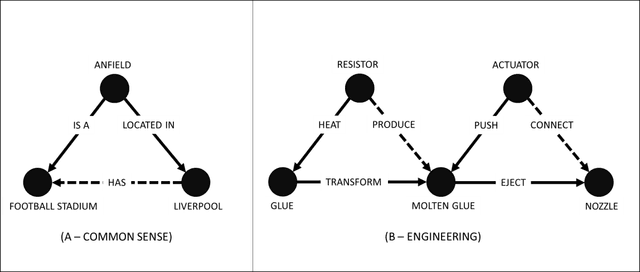

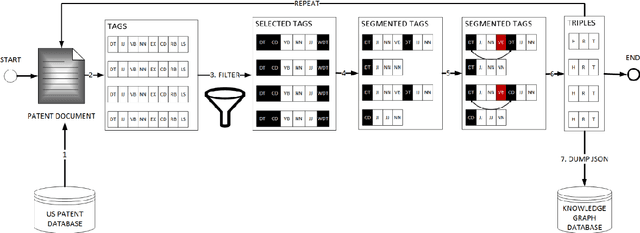
We propose a large, scalable engineering knowledge graph, comprising sets of (entity, relationship, entity) triples that are real-world engineering facts found in the patent database. We apply a set of rules based on the syntactic and lexical properties of claims in a patent document to extract facts. We aggregate these facts within each patent document and integrate the aggregated sets of facts across the patent database to obtain the engineering knowledge graph. Such a knowledge graph is expected to support inference, reasoning, and recalling in various engineering tasks. The knowledge graph has a greater size and coverage in comparison with the previously used knowledge graphs and semantic networks in the engineering literature.
Data-Driven Design-by-Analogy: State of the Art and Future Directions
Jun 03, 2021
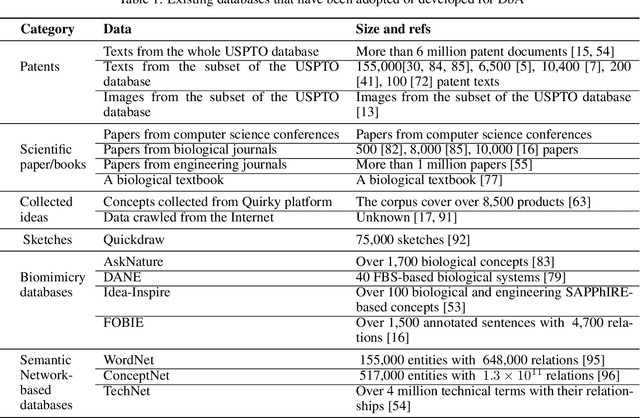
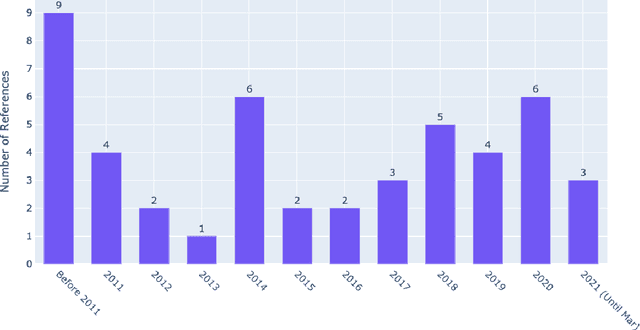
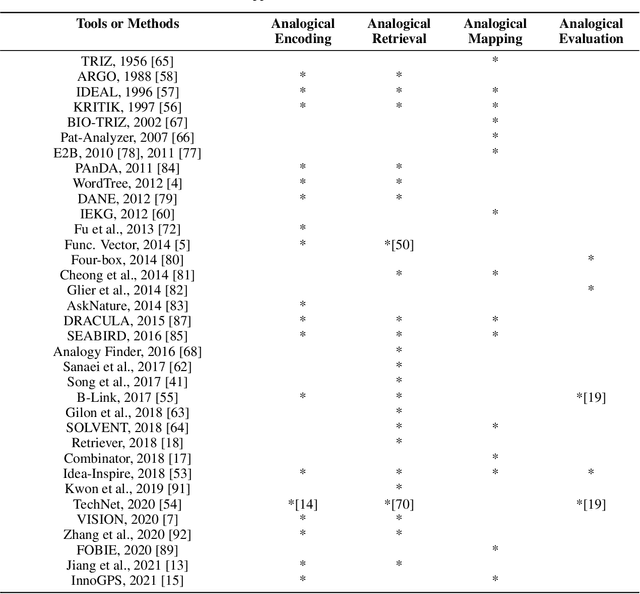
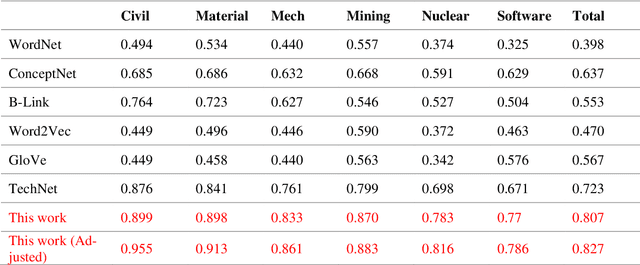
Design-by-Analogy (DbA) is a design methodology wherein new solutions, opportunities or designs are generated in a target domain based on inspiration drawn from a source domain; it can benefit designers in mitigating design fixation and improving design ideation outcomes. Recently, the increasingly available design databases and rapidly advancing data science and artificial intelligence technologies have presented new opportunities for developing data-driven methods and tools for DbA support. In this study, we survey existing data-driven DbA studies and categorize individual studies according to the data, methods, and applications in four categories, namely, analogy encoding, retrieval, mapping, and evaluation. Based on both nuanced organic review and structured analysis, this paper elucidates the state of the art of data-driven DbA research to date and benchmarks it with the frontier of data science and AI research to identify promising research opportunities and directions for the field. Finally, we propose a future conceptual data-driven DbA system that integrates all propositions.
EPIC30M: An Epidemics Corpus Of Over 30 Million Relevant Tweets
Jun 22, 2020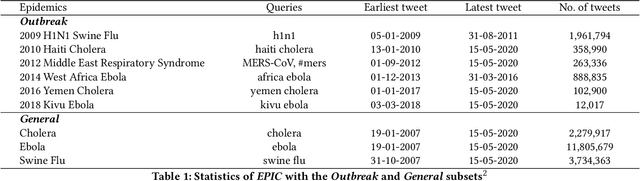

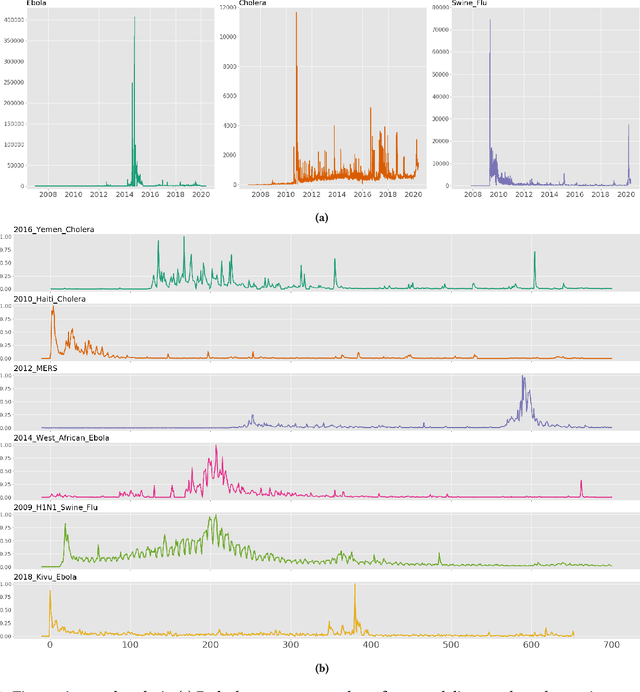
Since the start of COVID-19, several relevant corpora from various sources are presented in the literature that contain millions of data points. While these corpora are valuable in supporting many analyses on this specific pandemic, researchers require additional benchmark corpora that contain other epidemics to facilitate cross-epidemic pattern recognition and trend analysis tasks. During our other efforts on COVID-19 related work, we discover very little disease related corpora in the literature that are sizable and rich enough to support such cross-epidemic analysis tasks. In this paper, we present EPIC30M, a large-scale epidemic corpus that contains 30 millions micro-blog posts, i.e., tweets crawled from Twitter, from year 2006 to 2020. EPIC30M contains a subset of 26.2 millions tweets related to three general diseases, namely Ebola, Cholera and Swine Flu, and another subset of 4.7 millions tweets of six global epidemic outbreaks, including 2009 H1N1 Swine Flu, 2010 Haiti Cholera, 2012 Middle-East Respiratory Syndrome (MERS), 2013 West African Ebola, 2016 Yemen Cholera and 2018 Kivu Ebola. Furthermore, we explore and discuss the properties of the corpus with statistics of key terms and hashtags and trends analysis for each subset. Finally, we demonstrate the value and impact that EPIC30M could create through a discussion of multiple use cases of cross-epidemic research topics that attract growing interest in recent years. These use cases span multiple research areas, such as epidemiological modeling, pattern recognition, natural language understanding and economical modeling.
CrisisBERT: a Robust Transformer for Crisis Classification and Contextual Crisis Embedding
May 18, 2020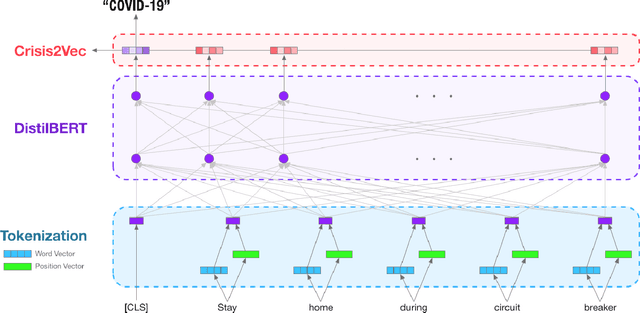

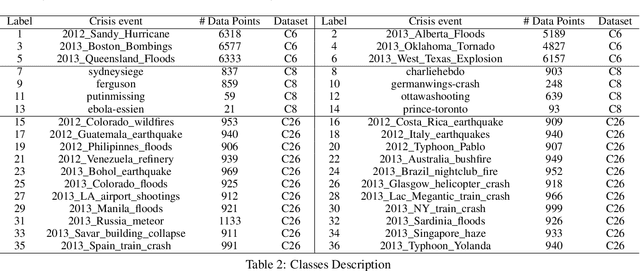
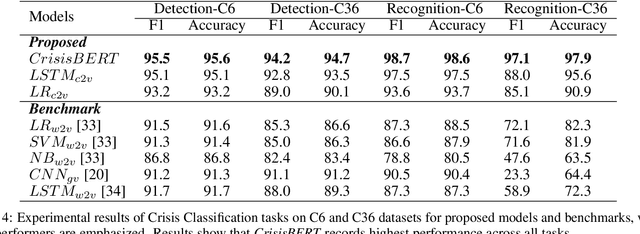
Classification of crisis events, such as natural disasters, terrorist attacks and pandemics, is a crucial task to create early signals and inform relevant parties for spontaneous actions to reduce overall damage. Despite crisis such as natural disasters can be predicted by professional institutions, certain events are first signaled by civilians, such as the recent COVID-19 pandemics. Social media platforms such as Twitter often exposes firsthand signals on such crises through high volume information exchange over half a billion tweets posted daily. Prior works proposed various crisis embeddings and classification using conventional Machine Learning and Neural Network models. However, none of the works perform crisis embedding and classification using state of the art attention-based deep neural networks models, such as Transformers and document-level contextual embeddings. This work proposes CrisisBERT, an end-to-end transformer-based model for two crisis classification tasks, namely crisis detection and crisis recognition, which shows promising results across accuracy and f1 scores. The proposed model also demonstrates superior robustness over benchmark, as it shows marginal performance compromise while extending from 6 to 36 events with only 51.4% additional data points. We also proposed Crisis2Vec, an attention-based, document-level contextual embedding architecture for crisis embedding, which achieve better performance than conventional crisis embedding methods such as Word2Vec and GloVe. To the best of our knowledge, our works are first to propose using transformer-based crisis classification and document-level contextual crisis embedding in the literature.
Path tracking control of self-reconfigurable robot hTetro with four differential drive units
Nov 20, 2019
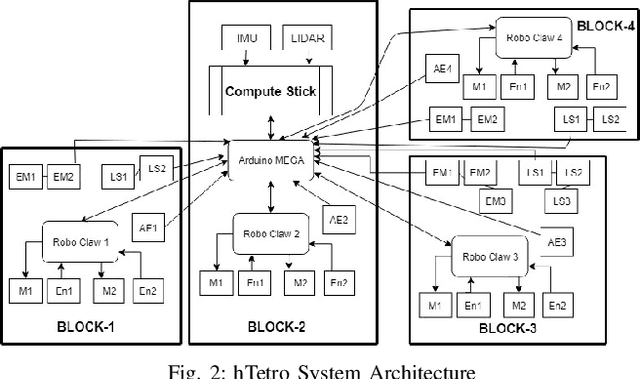
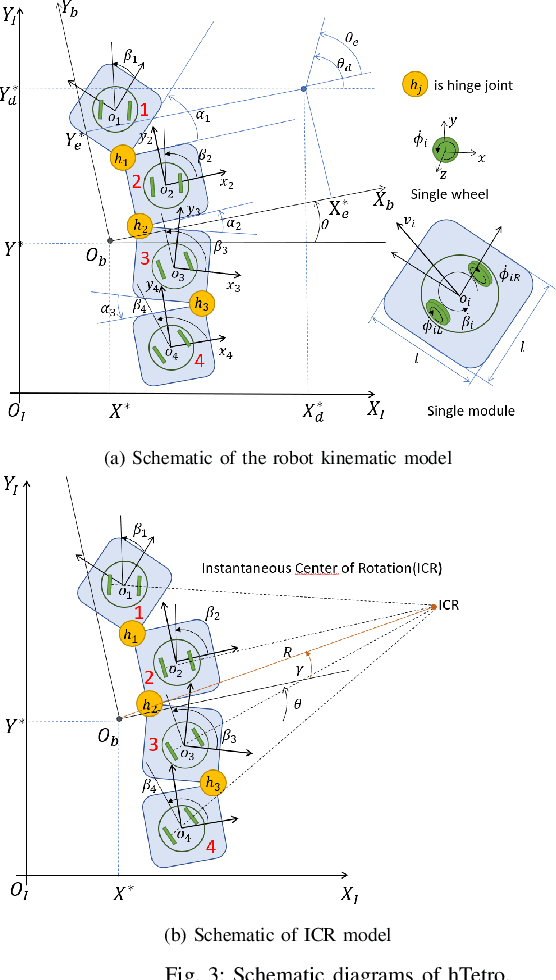
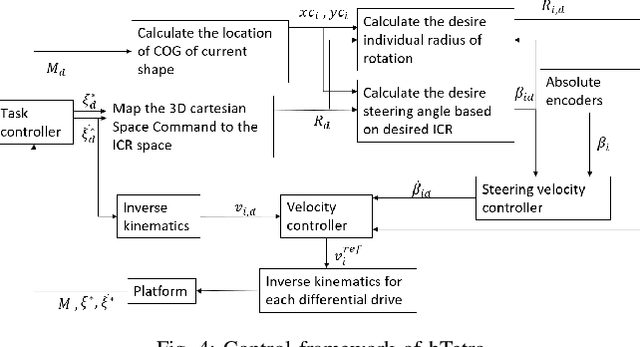
The research interest in robots with more than one steerable wheel has been increasing over recent years due to their high mobility while having a better payload capacity than systems using omnidirectional wheels. However, with more controllable degrees of freedom, almost all of the platforms include redundancy which leads to a modeling method based on the instantaneous center of rotation. The self-reconfigurable the robotic platform, hTetro, is designed for floor cleaning tasks. It also has four differential-drive units which can steer individually. Differing from most other steerable wheeled mobile robots, the wheel arrangement of this robot changes because of its reconfigurability. In this paper, we proposed a robust path tracking controller that can handle discontinuous trajectories and sudden orientation changes. Singularity problems are resolved on both the mechanical aspect and control aspect. The controller is tested experimentally with the self-reconfigurable robotic platform hTetro, and results are discussed.
IPOD: Corpus of 190,000 Industrial Occupations
Oct 22, 2019
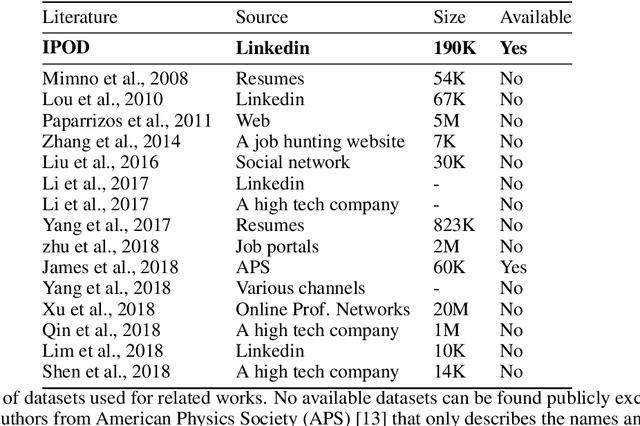
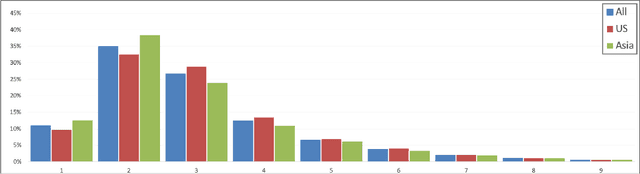
Job titles are the most fundamental building blocks for occupational data mining tasks, such as Career Modelling and Job Recommendation. However, there are no publicly available dataset to support such efforts. In this work, we present the Industrial and Professional Occupations Dataset (IPOD), which is a comprehensive corpus that consists of over 190,000 job titles crawled from over 56,000 profiles from Linkedin. To the best of our knowledge, IPOD is the first dataset released for industrial occupations mining. We use a knowledge-based approach for sequence tagging, creating a gazzetteer with domain-specific named entities tagged by 3 experts. All title NE tags are populated by the gazetteer using BIOES scheme. Finally, We develop 4 baseline models for the dataset on NER task with several models, including Linear Regression, CRF, LSTM and the state-of-the-art bi-directional LSTM-CRF. Both CRF and LSTM-CRF outperform human in both exact-match accuracy and f1 scores.
Crowd-aware itinerary recommendation: a game-theoretic approach to optimize social welfare
Oct 06, 2019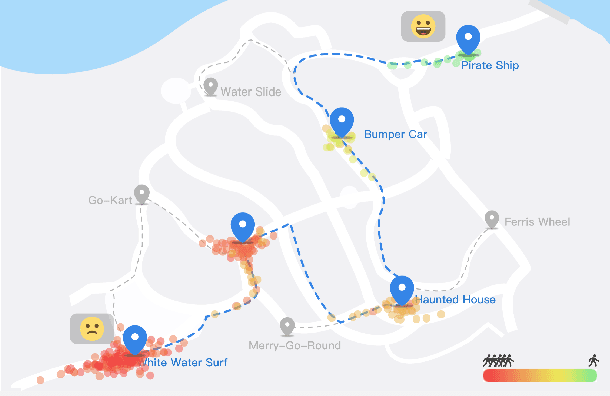
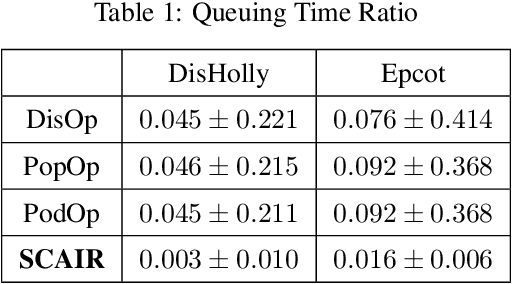
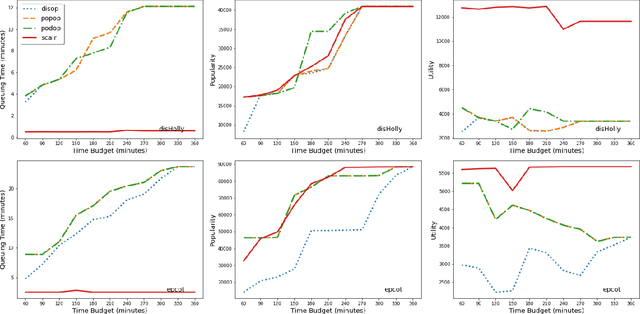
The demand for Itinerary Planning grows rapidly in recent years as the economy and standard of living are improving globally. Nonetheless, itinerary recommendation remains a complex and difficult task, especially for one that is queuing time- and crowd-aware. This difficulty is due to the large amount of parameters involved, i.e., attraction popularity, queuing time, walking time, operating hours, etc. Many recent or existing works adopt a data-driven approach and propose solutions with single-person perspectives, but do not address real-world problems as a result of natural crowd behavior, such as the Selfish Routing problem, which describes the consequence of ineffective network and sub-optimal social outcome by leaving agents to decide freely. In this work, we propose the Strategic and Crowd-Aware Itinerary Recommendation (SCAIR) algorithm which takes a game-theoretic approach to address the Selfish Routing problem and optimize social welfare in real-world situations. To address the NP-hardness of the social welfare optimization problem, we further propose a Markov Decision Process (MDP) approach which enables our simulations to be carried out in poly-time. We then use real-world data to evaluate the proposed algorithm, with benchmarks of two intuitive strategies commonly adopted in real life, and a recent algorithm published in the literature. Our simulation results highlight the existence of the Selfish Routing problem and show that SCAIR outperforms the benchmarks in handling this issue with real-world data.
Decentralized Multi-Floor Exploration by a Swarm of Miniature Robots Teaming with Wall-Climbing Units
Aug 16, 2019

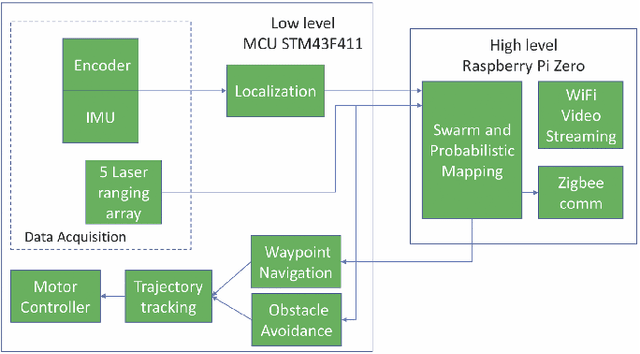
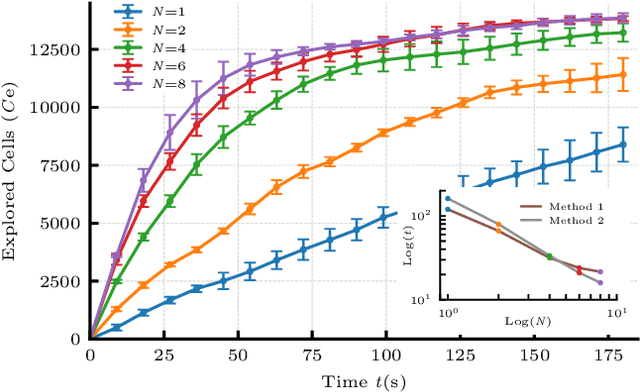
In this paper, we consider the problem of collectively exploring unknown and dynamic environments with a decentralized heterogeneous multi-robot system consisting of multiple units of two variants of a miniature robot. The first variant-a wheeled ground unit-is at the core of a swarm of floor-mapping robots exhibiting scalability, robustness and flexibility. These properties are systematically tested and quantitatively evaluated in unstructured and dynamic environments, in the absence of any supporting infrastructure. The results of repeated sets of experiments show a consistent performance for all three features, as well as the possibility to inject units into the system while it is operating. Several units of the second variant-a wheg-based wall-climbing unit-are used to support the swarm of mapping robots when simultaneously exploring multiple floors by expanding the distributed communication channel necessary for the coordinated behavior among platforms. Although the occupancy-grid maps obtained can be large, they are fully distributed. Not a single robotic unit possesses the overall map, which is not required by our cooperative path-planning strategy.
Technology Knowledge Graph Based on Patent Data
Jun 04, 2019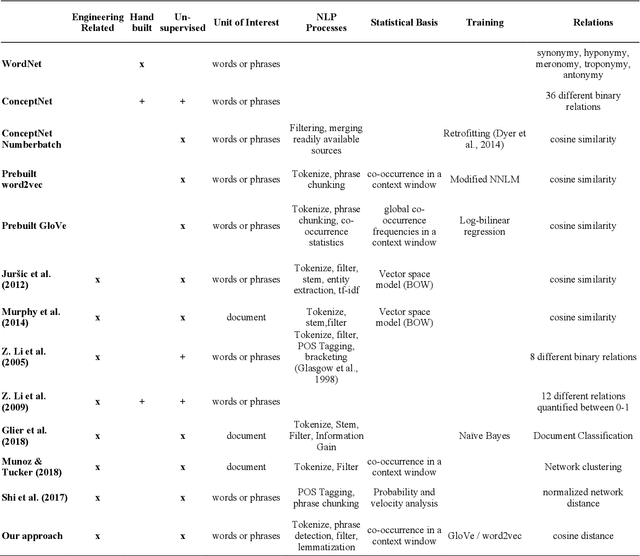
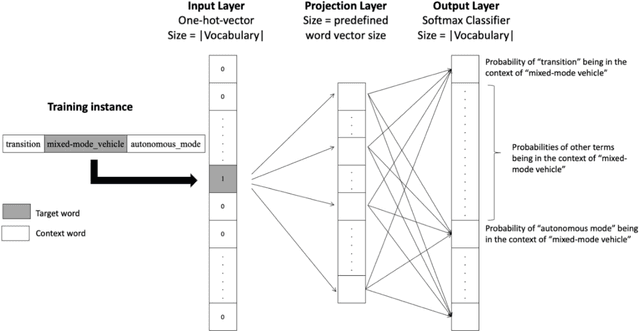
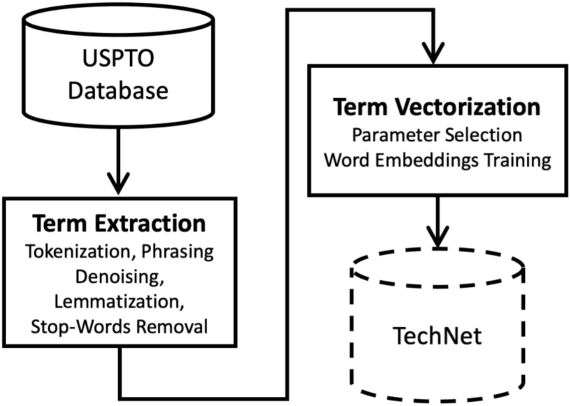

The growing developments in general semantic networks (or knowledge graphs) have motivated us to build a large-scale comprehensive knowledge graph of engineering data for engineering knowledge discovery, technology search and retrieval, and artificial intelligence for engineering design and innovation. Specially, we constructed a technology knowledge graph (TKG) that covers the elemental concepts in all domains of technology and their semantic associations by mining the complete U.S. patent database from 1976. This paper presents natural language processing techniques to extract terms from massive patent texts and word embedding models to vectorize such terms and establish their semantic relationships. We report and evaluate the TKG technology knowledge graph for retrieving terms, semantic similarity and analogy. The TKG may serve as an infrastructure to support a wide range of applications, e.g., technical text summaries, search query predictions, relational knowledge discovery, and design ideation support, in the context of engineering and technology. To support such applications, we made the TKG public via an online interface for public users to retrieve technology-related terms and their relevancies.