 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models for Design Structure Matrix Optimization
Jun 11, 2025In complex engineering systems, the interdependencies among components or development activities are often modeled and analyzed using Design Structure Matrix (DSM). Reorganizing elements within a DSM to minimize feedback loops and enhance modularity or process efficiency constitutes a challenging combinatorial optimization (CO) problem in engineering design and operations. As problem sizes increase and dependency networks become more intricate, traditional optimization methods that solely use mathematical heuristics often fail to capture the contextual nuances and struggle to deliver effective solutions. In this study, we explore the potential of Large Language Models (LLMs) for helping solve such CO problems by leveraging their capabilities for advanced reasoning and contextual understanding. We propose a novel LLM-based framework that integrates network topology with contextual domain knowledge for iterative optimization of DSM element sequencing - a common CO problem. Experiments on various DSM cases show that our method consistently achieves faster convergence and superior solution quality compared to both stochastic and deterministic baselines. Notably, we find that incorporating contextual domain knowledge significantly enhances optimization performance regardless of the chosen LLM backbone. These findings highlight the potential of LLMs to solve complex engineering CO problems by combining semantic and mathematical reasoning. This approach paves the way towards a new paradigm in LLM-based engineering design optimization.
Intelligent Design 4.0: Paradigm Evolution Toward the Agentic AI Era
Jun 11, 2025Research and practice in Intelligent Design (ID) have significantly enhanced engineering innovation, efficiency, quality, and productivity over recent decades, fundamentally reshaping how engineering designers think, behave, and interact with design processes. The recent emergence of Foundation Models (FMs), particularly Large Language Models (LLMs), has demonstrated general knowledge-based reasoning capabilities, and open new paths and avenues for further transformation in engineering design. In this context, this paper introduces Intelligent Design 4.0 (ID 4.0) as an emerging paradigm empowered by agentic AI systems. We review the historical evolution of ID across four distinct stages: rule-based expert systems, task-specific machine learning models, large-scale foundation AI models, and the recent emerging paradigm of multi-agent collaboration. We propose a conceptual framework for ID 4.0 and discuss its potential to support end-to-end automation of engineering design processes through coordinated, autonomous multi-agent-based systems. Furthermore, we discuss future perspectives to enhance and fully realize ID 4.0's potential, including more complex design scenarios, more practical design implementations, novel agent coordination mechanisms, and autonomous design goal-setting with better human value alignment. In sum, these insights lay a foundation for advancing Intelligent Design toward greater adaptivity, autonomy, and effectiveness in addressing increasingly complex design challenges.
Large Language Models for Combinatorial Optimization of Design Structure Matrix
Nov 19, 2024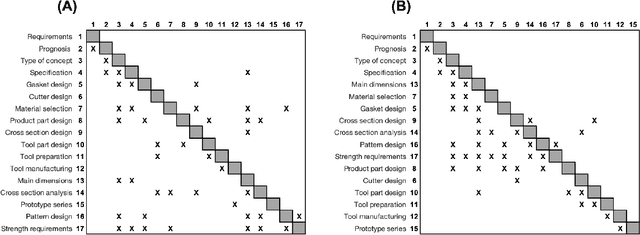
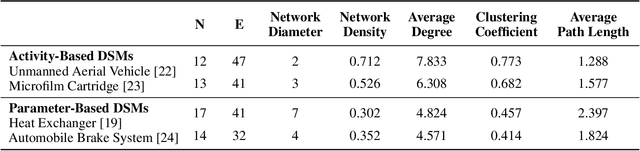
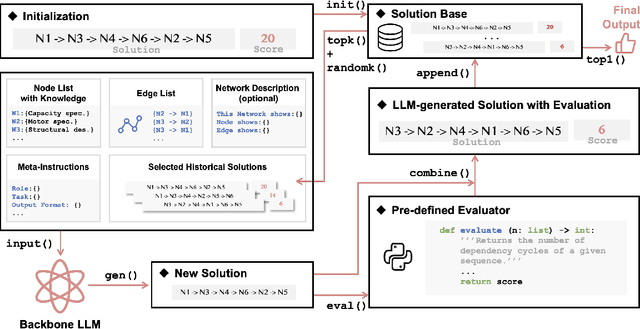
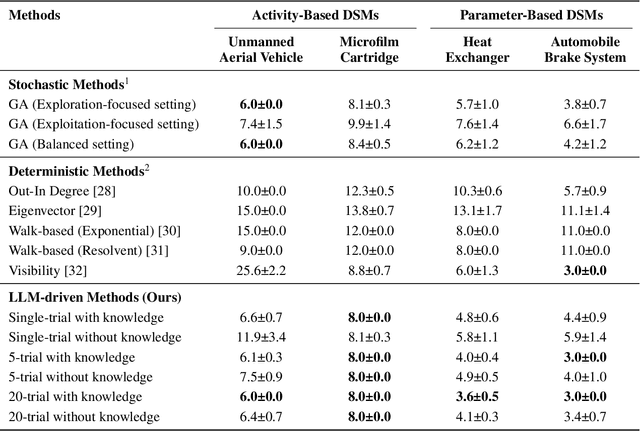
Combinatorial optimization (CO) is essential for improving efficiency and performance in engineering applications. As complexity increases with larger problem sizes and more intricate dependencies, identifying the optimal solution become challenging. When it comes to real-world engineering problems, algorithms based on pure mathematical reasoning are limited and incapable to capture the contextual nuances necessary for optimization. This study explores the potential of Large Language Models (LLMs) in solving engineering CO problems by leveraging their reasoning power and contextual knowledge. We propose a novel LLM-based framework that integrates network topology and domain knowledge to optimize the sequencing of Design Structure Matrix (DSM)-a common CO problem. Our experiments on various DSM cases demonstrate that the proposed method achieves faster convergence and higher solution quality than benchmark methods. Moreover, results show that incorporating contextual domain knowledge significantly improves performance despite the choice of LLMs. These findings highlight the potential of LLMs in tackling complex real-world CO problems by combining semantic and mathematical reasoning. This approach paves the way for a new paradigm in in real-world combinatorial optimization.
Reading Users' Minds from What They Say: An Investigation into LLM-based Empathic Mental Inference
Mar 20, 2024
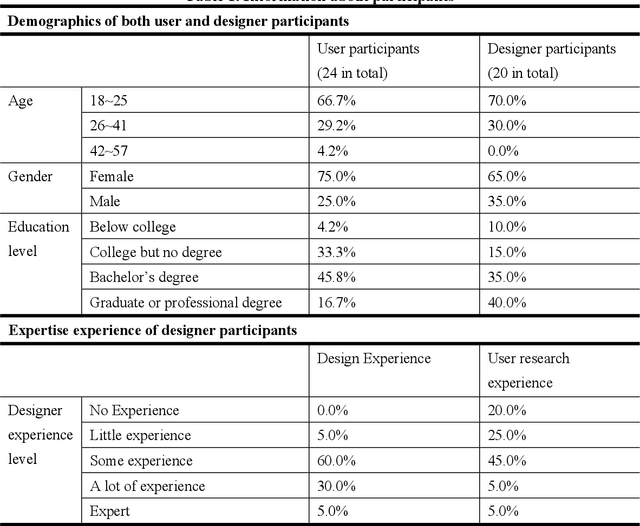

In human-centered design, developing a comprehensive and in-depth understanding of user experiences, i.e., empathic understanding, is paramount for designing products that truly meet human needs. Nevertheless, accurately comprehending the real underlying mental states of a large human population remains a significant challenge today. This difficulty mainly arises from the trade-off between depth and scale of user experience research: gaining in-depth insights from a small group of users does not easily scale to a larger population, and vice versa. This paper investigates the use of Large Language Models (LLMs) for performing mental inference tasks, specifically inferring users' underlying goals and fundamental psychological needs (FPNs). Baseline and benchmark datasets were collected from human users and designers to develop an empathic accuracy metric for measuring the mental inference performance of LLMs. The empathic accuracy of inferring goals and FPNs of different LLMs with varied zero-shot prompt engineering techniques are experimented against that of human designers. Experimental results suggest that LLMs can infer and understand the underlying goals and FPNs of users with performance comparable to that of human designers, suggesting a promising avenue for enhancing the scalability of empathic design approaches through the integration of advanced artificial intelligence technologies. This work has the potential to significantly augment the toolkit available to designers during human-centered design, enabling the development of both large-scale and in-depth understanding of users' experiences.
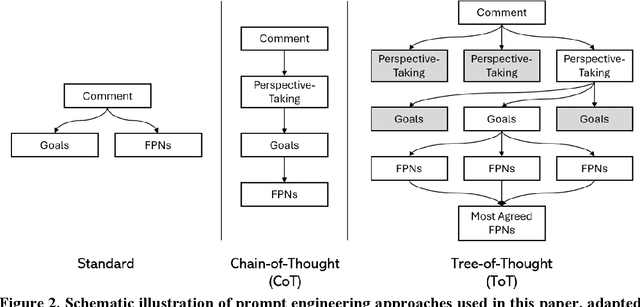
AutoTRIZ: Artificial Ideation with TRIZ and Large Language Models
Mar 13, 2024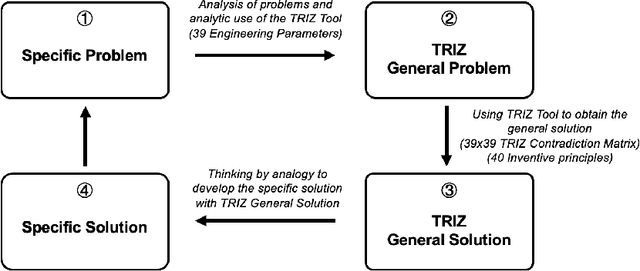
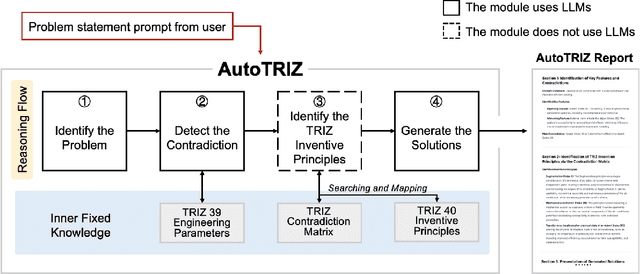
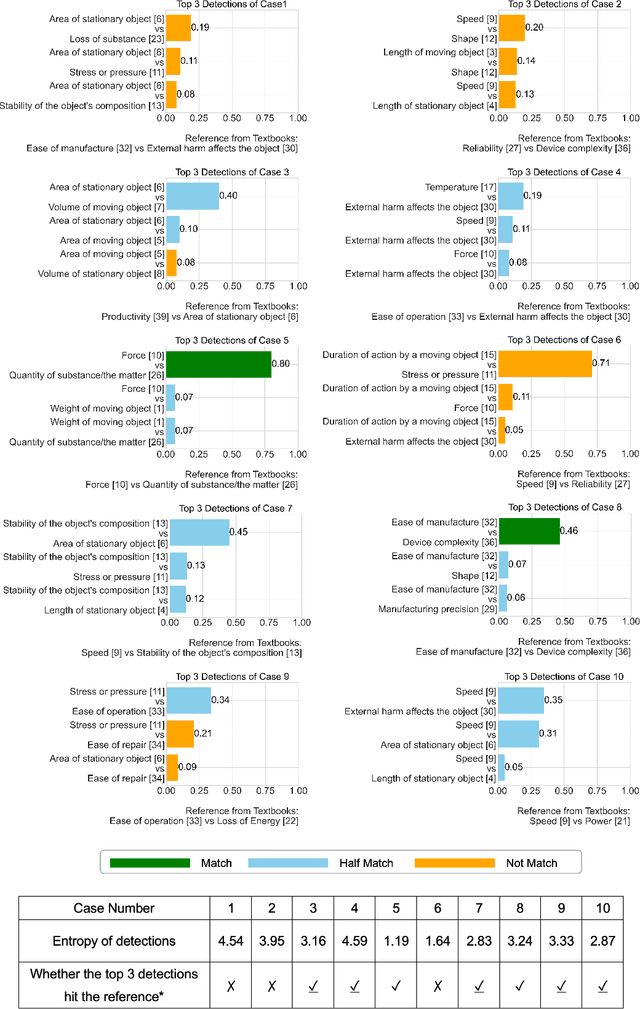
Researchers and innovators have made enormous efforts in developing ideation methods, such as morphological analysis and design-by-analogy, to aid engineering design ideation for problem solving and innovation. Among these, TRIZ stands out as the most well-known approach, widely applied for systematic innovation. However, the complexity of TRIZ resources and concepts, coupled with its reliance on users' knowledge, experience, and reasoning capabilities, limits its practicability. This paper proposes AutoTRIZ, an artificial ideation tool that leverages large language models (LLMs) to automate and enhance the TRIZ methodology. By leveraging the broad knowledge and advanced reasoning capabilities of LLMs, AutoTRIZ offers a novel approach to design automation and interpretable ideation with artificial intelligence. We demonstrate and evaluate the effectiveness of AutoTRIZ through consistency experiments in contradiction detection and comparative studies with cases collected from TRIZ textbooks. Moreover, the proposed LLM-based framework holds the potential for extension to automate other knowledge-based ideation methods, including SCAMPER, Design Heuristics, and Design-by-Analogy, paving the way for a new era of artificial ideation for design and innovation.
Empirical Basis of Engineering Design Knowledge
Dec 11, 2023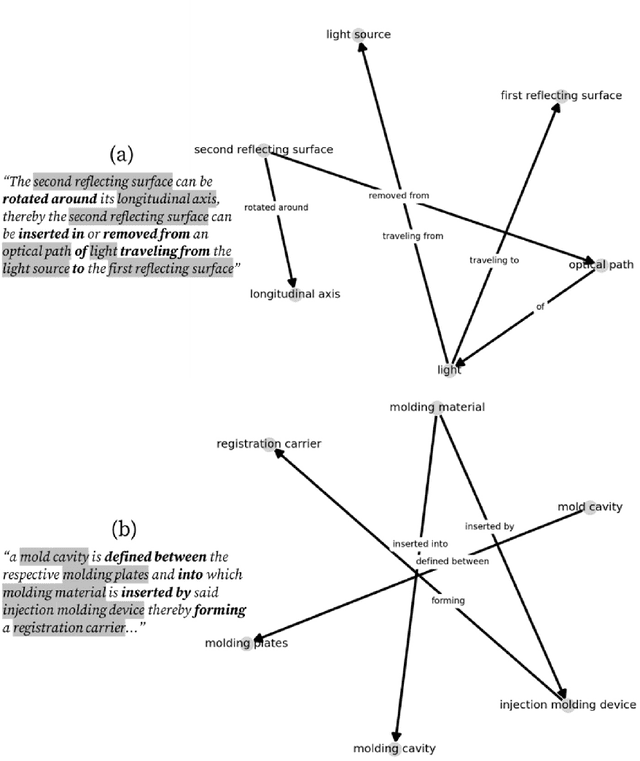

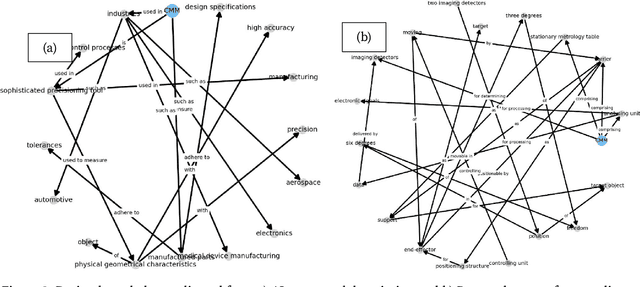

Engineering design knowledge is embodied in natural language text through intricate placement of entities and relationships. Ontological constructs of design knowledge often limit the performances of NLP techniques to extract design knowledge. Also, large-language models could be less useful for generating and explicating design knowledge, as these are trained predominantly on common-sense text. In this article, we present the constituents of design knowledge based on empirical observations from patent documents. We obtain a sample of 33,881 patents and populate over 24 million facts from the sentences in these. We conduct Zipf distribution analyses using the frequencies of unique entities and relationships that are present in the facts thus populated. While the literal entities cannot be generalised from the sample of patents, the relationships largely capture attributes ('of'), structure ('in', 'with'), purpose ('to', 'for'), hierarchy ('include'), exemplification ('such as'), and behaviour ('to', 'from'). The analyses reveal that over half of entities and relationships could be generalised to 64 and 24 linguistic syntaxes respectively, while hierarchical relationships include 75 syntaxes. These syntaxes represent the linguistic basis of engineering design knowledge. We combine facts within each patent into a knowledge graph, from which we discover motifs that are statistically over-represented subgraph patterns. Across all patents in the sample, we identify eight patterns that could be simplified into sequence [->...->], aggregation [->...<-], and hierarchy [<-...->] that form the structural basis of engineering design knowledge. We propose regulatory precepts for concretising abstract entities and relationships within subgraphs, while also explicating hierarchical structures. These precepts could be useful for better construction and management of knowledge in a design environment.
Towards Populating Generalizable Engineering Design Knowledge
Jul 13, 2023Aiming to populate generalizable engineering design knowledge, we propose a method to extract facts of the form head entity :: relationship :: tail entity from sentences found in patent documents. These facts could be combined within and across patent documents to form knowledge graphs that serve as schemes for representing as well as storing design knowledge. Existing methods in engineering design literature often utilise a set of predefined relationships to populate triples that are statistical approximations rather than facts. In our method, we train a tagger to identify both entities and relationships from a sentence. Given a pair of entities thus identified, we train another tagger to identify the relationship tokens that specifically denote the relationship between the pair. For training these taggers, we manually construct a dataset of 44,227 sentences and corresponding facts. We also compare the performance of the method against typically recommended approaches, wherein, we predict the edges among tokens by pairing the tokens independently and as part of a graph. We apply our method to sentences found in patents related to fan systems and build a domain knowledge base. Upon providing an overview of the knowledge base, we search for solutions relevant to some key issues prevailing in fan systems. We organize the responses into knowledge graphs and hold a comparative discussion against the opinions from ChatGPT.
Innovation Slowdown: Decelerating Concept Creation and Declining Originality in New Technological Concepts
Mar 23, 2023The creation of new technological concepts through design reuses, recombination, and synthesis of prior concepts to create new ones may lead to exponential growth of the concept space over time. However, our statistical analysis of a large-scale technology semantic network consisting of over four million concepts from patent texts found evidence of a persistent deceleration in the pace of concept creation and a decline in the originality of newly created concepts. These trends may be attributed to the limitations of human intelligence in innovating beyond an expanding space of prior art. To sustain innovation, we recommend the development and implementation of creative artificial intelligence that can augment various aspects of the innovation process, including learning, creation, and evaluation.
Toward Artificial Empathy for Human-Centered Design: A Framework
Mar 19, 2023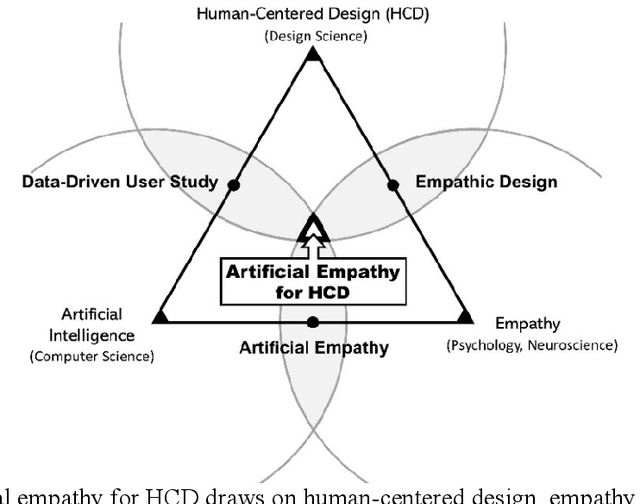
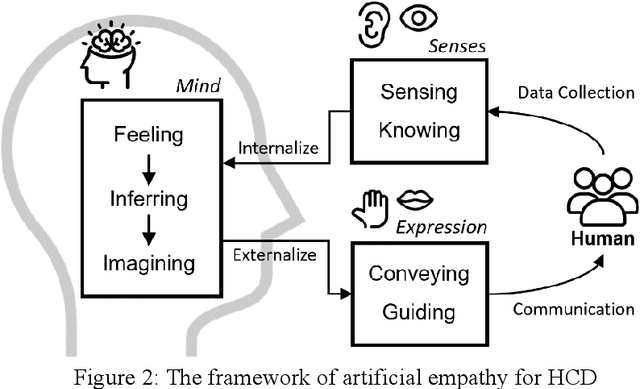
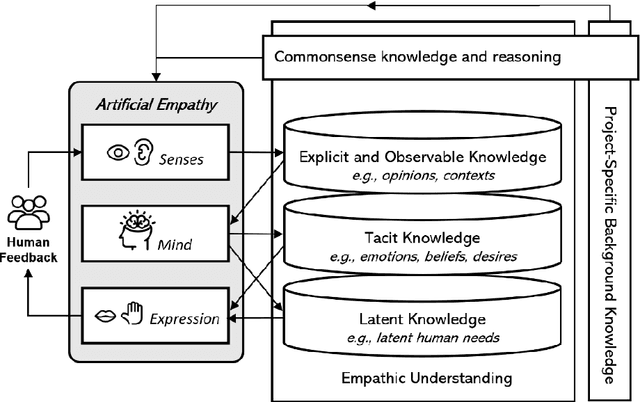
In the early stages of the design process, designers explore opportunities by discovering unmet needs and developing innovative concepts as potential solutions. From a human-centered design perspective, designers must develop empathy with people to truly understand their needs. However, developing empathy is a complex and subjective process that relies heavily on the designer's empathetic capability. Therefore, the development of empathetic understanding is intuitive, and the discovery of underlying needs is often serendipitous. This paper aims to provide insights from artificial intelligence research to indicate the future direction of AI-driven human-centered design, taking into account the essential role of empathy. Specifically, we conduct an interdisciplinary investigation of research areas such as data-driven user studies, empathetic understanding development, and artificial empathy. Based on this foundation, we discuss the role that artificial empathy can play in human-centered design and propose an artificial empathy framework for human-centered design. Building on the mechanisms behind empathy and insights from empathetic design research, the framework aims to break down the rather complex and subjective concept of empathy into components and modules that can potentially be modeled computationally. Furthermore, we discuss the expected benefits of developing such systems and identify current research gaps to encourage future research efforts.
Biologically Inspired Design Concept Generation Using Generative Pre-Trained Transformers
Dec 26, 2022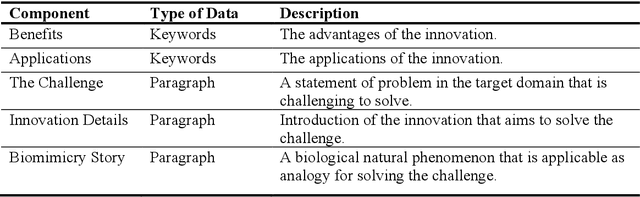
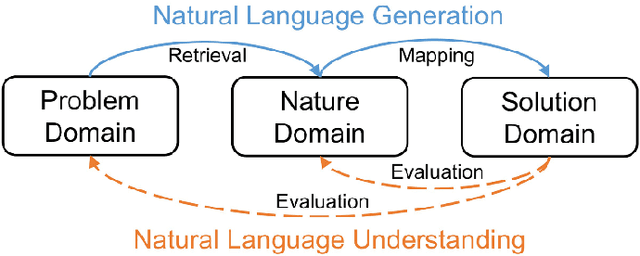
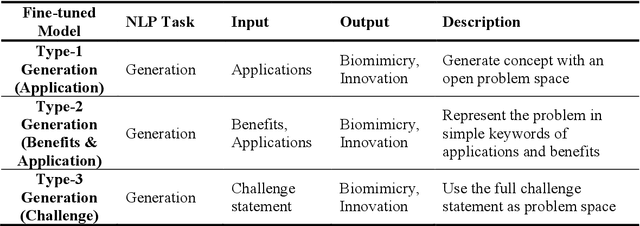
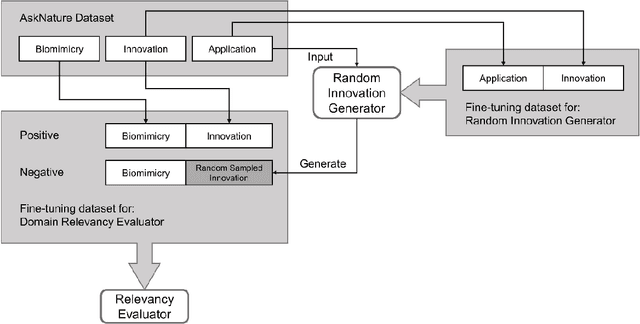
Biological systems in nature have evolved for millions of years to adapt and survive the environment. Many features they developed can be inspirational and beneficial for solving technical problems in modern industries. This leads to a specific form of design-by-analogy called bio-inspired design (BID). Although BID as a design method has been proven beneficial, the gap between biology and engineering continuously hinders designers from effectively applying the method. Therefore, we explore the recent advance of artificial intelligence (AI) for a data-driven approach to bridge the gap. This paper proposes a generative design approach based on the generative pre-trained language model (PLM) to automatically retrieve and map biological analogy and generate BID in the form of natural language. The latest generative pre-trained transformer, namely GPT-3, is used as the base PLM. Three types of design concept generators are identified and fine-tuned from the PLM according to the looseness of the problem space representation. Machine evaluators are also fine-tuned to assess the mapping relevancy between the domains within the generated BID concepts. The approach is evaluated and then employed in a real-world project of designing light-weighted flying cars during its conceptual design phase The results show our approach can generate BID concepts with good performance.