 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning the Unseen in Attributed Graphs: Interplay between Graph Geometry and Node Attributes Manifold
Jan 30, 2026The standard approach to representation learning on attributed graphs -- i.e., simultaneously reconstructing node attributes and graph structure -- is geometrically flawed, as it merges two potentially incompatible metric spaces. This forces a destructive alignment that erodes information about the graph's underlying generative process. To recover this lost signal, we introduce a custom variational autoencoder that separates manifold learning from structural alignment. By quantifying the metric distortion needed to map the attribute manifold onto the graph's Heat Kernel, we transform geometric conflict into an interpretable structural descriptor. Experiments show our method uncovers connectivity patterns and anomalies undetectable by conventional approaches, proving both their theoretical inadequacy and practical limitations.
Multi-Target Pursuit by a Decentralized Heterogeneous UAV Swarm using Deep Multi-Agent Reinforcement Learning
Mar 03, 2023Multi-agent pursuit-evasion tasks involving intelligent targets are notoriously challenging coordination problems. In this paper, we investigate new ways to learn such coordinated behaviors of unmanned aerial vehicles (UAVs) aimed at keeping track of multiple evasive targets. Within a Multi-Agent Reinforcement Learning (MARL) framework, we specifically propose a variant of the Multi-Agent Deep Deterministic Policy Gradient (MADDPG) method. Our approach addresses multi-target pursuit-evasion scenarios within non-stationary and unknown environments with random obstacles. In addition, given the critical role played by collective exploration in terms of detecting possible targets, we implement heterogeneous roles for the pursuers for enhanced exploratory actions balanced by exploitation (i.e. tracking) of previously identified targets. Our proposed role-based MADDPG algorithm is not only able to track multiple targets, but also is able to explore for possible targets by means of the proposed Voronoi-based rewarding policy. We implemented, tested and validated our approach in a simulation environment prior to deploying a real-world multi-robot system comprising of Crazyflie drones. Our results demonstrate that a multi-agent pursuit team has the ability to learn highly efficient coordinated control policies in terms of target tracking and exploration even when confronted with multiple fast evasive targets in complex environments.
A Sequential Deep Learning Algorithm for Sampled Mixed-integer Optimisation Problems
Jan 25, 2023



Mixed-integer optimisation problems can be computationally challenging. Here, we introduce and analyse two efficient algorithms with a specific sequential design that are aimed at dealing with sampled problems within this class. At each iteration step of both algorithms, we first test the feasibility of a given test solution for each and every constraint associated with the sampled optimisation at hand, while also identifying those constraints that are violated. Subsequently, an optimisation problem is constructed with a constraint set consisting of the current basis -- namely the smallest set of constraints that fully specifies the current test solution -- as well as constraints related to a limited number of the identified violating samples. We show that both algorithms exhibit finite-time convergence towards the optimal solution. Algorithm 2 features a neural network classifier that notably improves the computational performance compared to Algorithm 1. We establish quantitatively the efficacy of these algorithms by means of three numerical tests: robust optimal power flow, robust unit commitment, and robust random mixed-integer linear program.
Adapting the Exploration-Exploitation Balance in Heterogeneous Swarms: Tracking Evasive Targets
Jul 27, 2022



There has been growing interest in the use of multi-robot systems in various tasks and scenarios. The main attractiveness of such systems is their flexibility, robustness, and scalability. An often overlooked yet promising feature is system modularity, which offers the possibility to harness agent specialization, while also enabling system-level upgrades. However, altering the agents' capacities can change the exploration-exploitation balance required to maximize the system's performance. Here, we study the effect of a swarm's heterogeneity on its exploration-exploitation balance while tracking multiple fast-moving evasive targets under the Cooperative Multi-Robot Observation of Multiple Moving Targets framework. To this end, we use a decentralized search and tracking strategy with adjustable levels of exploration and exploitation. By indirectly tuning the balance, we first confirm the presence of an optimal balance between these two key competing actions. Next, by substituting slower moving agents with faster ones, we show that the system exhibits a performance improvement without any modifications to the original strategy. In addition, owing to the additional amount of exploitation carried out by the faster agents, we demonstrate that a heterogeneous system's performance can be further improved by reducing an agent's level of connectivity, to favor the conduct of exploratory actions. Furthermore, in studying the influence of the density of swarming agents, we show that the addition of faster agents can counterbalance a reduction in the overall number of agents while maintaining the level of tracking performance. Finally, we explore the challenges of using differentiated strategies to take advantage of the heterogeneous nature of the swarm.
Tracking Multiple Fast Targets With Swarms: Interplay Between Social Interaction and Agent Memory
Aug 16, 2021



The task of searching for and tracking of multiple targets is a challenging one. However, most works in this area do not consider evasive targets that move faster than the agents comprising the multi-robot system. This is due to the assumption that the movement patterns of such targets, combined with their excessive speed, would make the task nearly impossible to accomplish. In this work, we show that this is not the case and we propose a decentralized search and tracking strategy in which the level of exploration and exploitation carried out by the swarm is adjustable. By tuning a swarm's exploration and exploitation dynamics, we demonstrate that there exists an optimal balance between the level of exploration and exploitation performed. This optimum maximizes its tracking performance and changes depending on the number of targets and the targets' movement profiles. We also show that the use of agent-based memory is critical in enabling the tracking of an evasive target. The obtained simulation results are validated through experimental tests with a decentralized swarm of six robots tracking a virtual fast-moving target.
Multi-Agent Reinforcement Learning for Dynamic Ocean Monitoring by a Swarm of Buoys
Dec 21, 2020
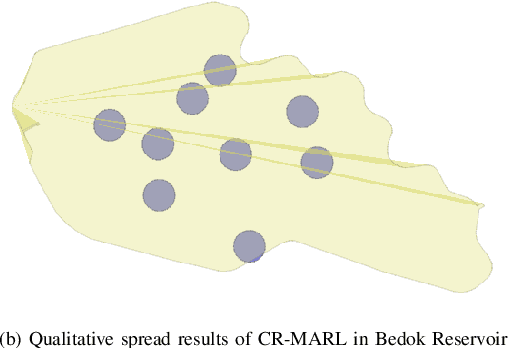
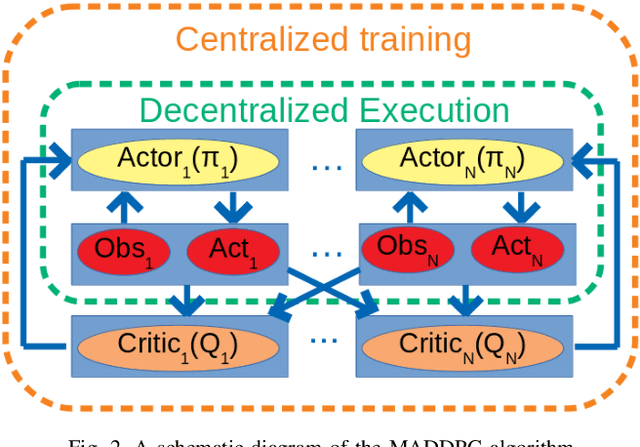

Autonomous marine environmental monitoring problem traditionally encompasses an area coverage problem which can only be effectively carried out by a multi-robot system. In this paper, we focus on robotic swarms that are typically operated and controlled by means of simple swarming behaviors obtained from a subtle, yet ad hoc combination of bio-inspired strategies. We propose a novel and structured approach for area coverage using multi-agent reinforcement learning (MARL) which effectively deals with the non-stationarity of environmental features. Specifically, we propose two dynamic area coverage approaches: (1) swarm-based MARL, and (2) coverage-range-based MARL. The former is trained using the multi-agent deep deterministic policy gradient (MADDPG) approach whereas, a modified version of MADDPG is introduced for the latter with a reward function that intrinsically leads to a collective behavior. Both methods are tested and validated with different geometric shaped regions with equal surface area (square vs. rectangle) yielding acceptable area coverage, and benefiting from the structured learning in non-stationary environments. Both approaches are advantageous compared to a na\"{i}ve swarming method. However, coverage-range-based MARL outperforms the swarm-based MARL with stronger convergence features in learning criteria and higher spreading of agents for area coverage.
Heterogeneous Swarms for Maritime Dynamic Target Search and Tracking
Aug 03, 2020



Current strategies employed for maritime target search and tracking are primarily based on the use of agents following a predetermined path to perform a systematic sweep of a search area. Recently, dynamic Particle Swarm Optimization (PSO) algorithms have been used together with swarming multi-robot systems (MRS), giving search and tracking solutions the added properties of robustness, scalability, and flexibility. Swarming MRS also give the end-user the opportunity to incrementally upgrade the robotic system, inevitably leading to the use of heterogeneous swarming MRS. However, such systems have not been well studied and incorporating upgraded agents into a swarm may result in degraded mission performances. In this paper, we propose a PSO-based strategy using a topological k-nearest neighbor graph with tunable exploration and exploitation dynamics with an adaptive repulsion parameter. This strategy is implemented within a simulated swarm of 50 agents with varying proportions of fast agents tracking a target represented by a fictitious binary function. Through these simulations, we are able to demonstrate an increase in the swarm's collective response level and target tracking performance by substituting in a proportion of fast buoys.
Decentralized Multi-Floor Exploration by a Swarm of Miniature Robots Teaming with Wall-Climbing Units
Aug 16, 2019

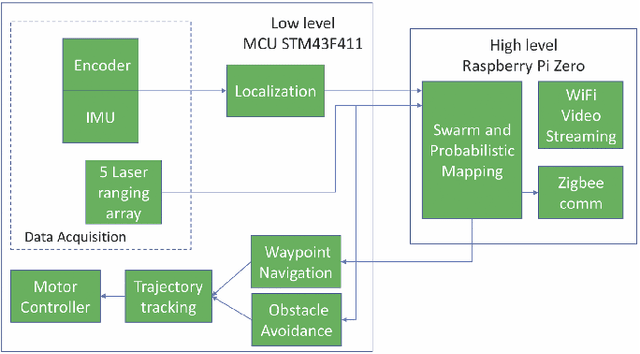
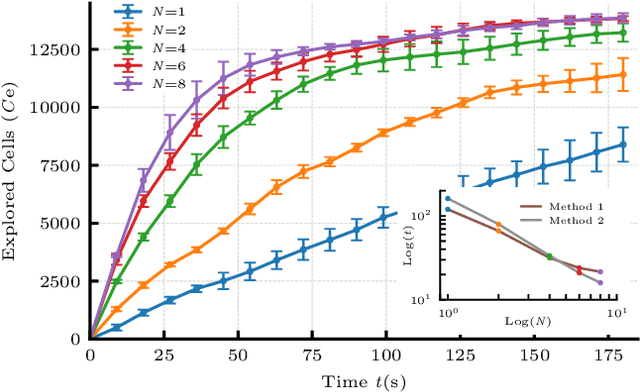
In this paper, we consider the problem of collectively exploring unknown and dynamic environments with a decentralized heterogeneous multi-robot system consisting of multiple units of two variants of a miniature robot. The first variant-a wheeled ground unit-is at the core of a swarm of floor-mapping robots exhibiting scalability, robustness and flexibility. These properties are systematically tested and quantitatively evaluated in unstructured and dynamic environments, in the absence of any supporting infrastructure. The results of repeated sets of experiments show a consistent performance for all three features, as well as the possibility to inject units into the system while it is operating. Several units of the second variant-a wheg-based wall-climbing unit-are used to support the swarm of mapping robots when simultaneously exploring multiple floors by expanding the distributed communication channel necessary for the coordinated behavior among platforms. Although the occupancy-grid maps obtained can be large, they are fully distributed. Not a single robotic unit possesses the overall map, which is not required by our cooperative path-planning strategy.
Self-Organizing Maps for Storage and Transfer of Knowledge in Reinforcement Learning
Nov 18, 2018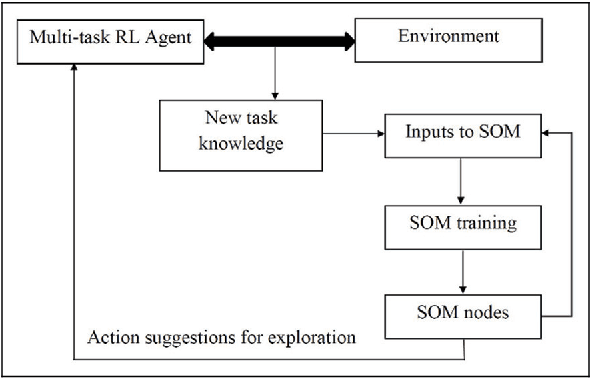
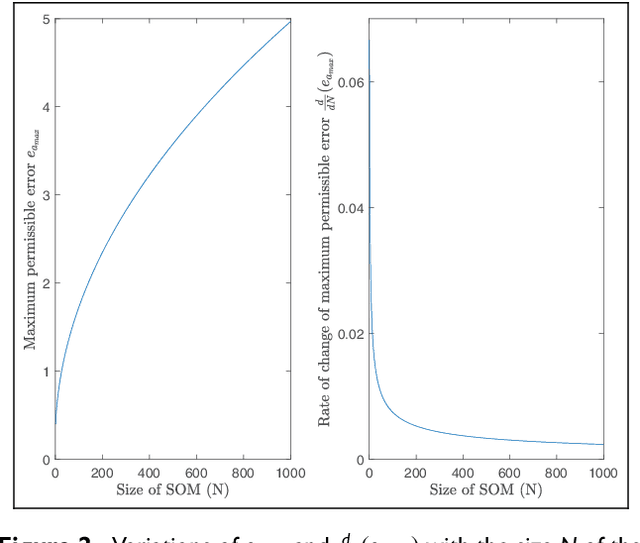

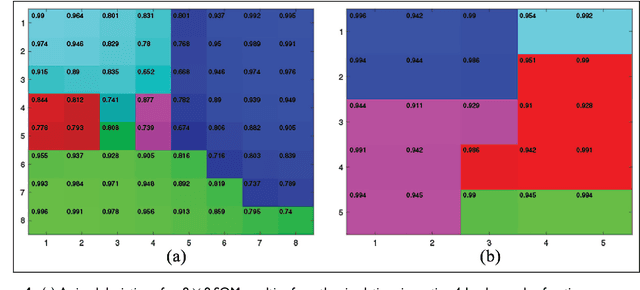
The idea of reusing or transferring information from previously learned tasks (source tasks) for the learning of new tasks (target tasks) has the potential to significantly improve the sample efficiency of a reinforcement learning agent. In this work, we describe a novel approach for reusing previously acquired knowledge by using it to guide the exploration of an agent while it learns new tasks. In order to do so, we employ a variant of the growing self-organizing map algorithm, which is trained using a measure of similarity that is defined directly in the space of the vectorized representations of the value functions. In addition to enabling transfer across tasks, the resulting map is simultaneously used to enable the efficient storage of previously acquired task knowledge in an adaptive and scalable manner. We empirically validate our approach in a simulated navigation environment, and also demonstrate its utility through simple experiments using a mobile micro-robotics platform. In addition, we demonstrate the scalability of this approach, and analytically examine its relation to the proposed network growth mechanism. Further, we briefly discuss some of the possible improvements and extensions to this approach, as well as its relevance to real world scenarios in the context of continual learning.
A Decentralized Mobile Computing Network for Multi-Robot Systems Operations
Oct 13, 2018



Collective animal behaviors are paradigmatic examples of fully decentralized operations involving complex collective computations such as collective turns in flocks of birds or collective harvesting by ants. These systems offer a unique source of inspiration for the development of fault-tolerant and self-healing multi-robot systems capable of operating in dynamic environments. Specifically, swarm robotics emerged and is significantly growing on these premises. However, to date, most swarm robotics systems reported in the literature involve basic computational tasks---averages and other algebraic operations. In this paper, we introduce a novel Collective computing framework based on the swarming paradigm, which exhibits the key innate features of swarms: robustness, scalability and flexibility. Unlike Edge computing, the proposed Collective computing framework is truly decentralized and does not require user intervention or additional servers to sustain its operations. This Collective computing framework is applied to the complex task of collective mapping, in which multiple robots aim at cooperatively map a large area. Our results confirm the effectiveness of the cooperative strategy, its robustness to the loss of multiple units, as well as its scalability. Furthermore, the topology of the interconnecting network is found to greatly influence the performance of the collective action.