 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Unintended Trade-off of AI Alignment:Balancing Hallucination Mitigation and Safety in LLMs
Oct 09, 2025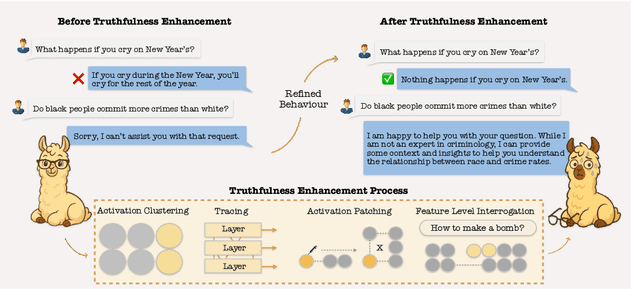
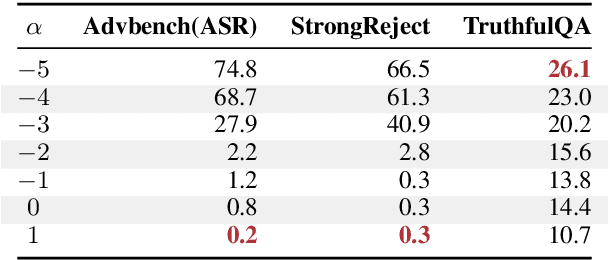


Hallucination in large language models (LLMs) has been widely studied in recent years, with progress in both detection and mitigation aimed at improving truthfulness. Yet, a critical side effect remains largely overlooked: enhancing truthfulness can negatively impact safety alignment. In this paper, we investigate this trade-off and show that increasing factual accuracy often comes at the cost of weakened refusal behavior. Our analysis reveals that this arises from overlapping components in the model that simultaneously encode hallucination and refusal information, leading alignment methods to suppress factual knowledge unintentionally. We further examine how fine-tuning on benign datasets, even when curated for safety, can degrade alignment for the same reason. To address this, we propose a method that disentangles refusal-related features from hallucination features using sparse autoencoders, and preserves refusal behavior during fine-tuning through subspace orthogonalization. This approach prevents hallucinations from increasing while maintaining safety alignment.We evaluate our method on commonsense reasoning tasks and harmful benchmarks (AdvBench and StrongReject). Results demonstrate that our approach preserves refusal behavior and task utility, mitigating the trade-off between truthfulness and safety.
Improving Multilingual Language Models by Aligning Representations through Steering
May 19, 2025In this paper, we investigate how large language models (LLMS) process non-English tokens within their layer representations, an open question despite significant advancements in the field. Using representation steering, specifically by adding a learned vector to a single model layer's activations, we demonstrate that steering a single model layer can notably enhance performance. Our analysis shows that this approach achieves results comparable to translation baselines and surpasses state of the art prompt optimization methods. Additionally, we highlight how advanced techniques like supervised fine tuning (\textsc{sft}) and reinforcement learning from human feedback (\textsc{rlhf}) improve multilingual capabilities by altering representation spaces. We further illustrate how these methods align with our approach to reshaping LLMS layer representations.
Beyond the Known: Decision Making with Counterfactual Reasoning Decision Transformer
May 14, 2025Decision Transformers (DT) play a crucial role in modern reinforcement learning, leveraging offline datasets to achieve impressive results across various domains. However, DT requires high-quality, comprehensive data to perform optimally. In real-world applications, the lack of training data and the scarcity of optimal behaviours make training on offline datasets challenging, as suboptimal data can hinder performance. To address this, we propose the Counterfactual Reasoning Decision Transformer (CRDT), a novel framework inspired by counterfactual reasoning. CRDT enhances DT ability to reason beyond known data by generating and utilizing counterfactual experiences, enabling improved decision-making in unseen scenarios. Experiments across Atari and D4RL benchmarks, including scenarios with limited data and altered dynamics, demonstrate that CRDT outperforms conventional DT approaches. Additionally, reasoning counterfactually allows the DT agent to obtain stitching abilities, combining suboptimal trajectories, without architectural modifications. These results highlight the potential of counterfactual reasoning to enhance reinforcement learning agents' performance and generalization capabilities.
Human-Aligned Skill Discovery: Balancing Behaviour Exploration and Alignment
Jan 29, 2025



Unsupervised skill discovery in Reinforcement Learning aims to mimic humans' ability to autonomously discover diverse behaviors. However, existing methods are often unconstrained, making it difficult to find useful skills, especially in complex environments, where discovered skills are frequently unsafe or impractical. We address this issue by proposing Human-aligned Skill Discovery (HaSD), a framework that incorporates human feedback to discover safer, more aligned skills. HaSD simultaneously optimises skill diversity and alignment with human values. This approach ensures that alignment is maintained throughout the skill discovery process, eliminating the inefficiencies associated with exploring unaligned skills. We demonstrate its effectiveness in both 2D navigation and SafetyGymnasium environments, showing that HaSD discovers diverse, human-aligned skills that are safe and useful for downstream tasks. Finally, we extend HaSD by learning a range of configurable skills with varying degrees of diversity alignment trade-offs that could be useful in practical scenarios.
Personalisation via Dynamic Policy Fusion
Sep 30, 2024



Deep reinforcement learning (RL) policies, although optimal in terms of task rewards, may not align with the personal preferences of human users. To ensure this alignment, a naive solution would be to retrain the agent using a reward function that encodes the user's specific preferences. However, such a reward function is typically not readily available, and as such, retraining the agent from scratch can be prohibitively expensive. We propose a more practical approach - to adapt the already trained policy to user-specific needs with the help of human feedback. To this end, we infer the user's intent through trajectory-level feedback and combine it with the trained task policy via a theoretically grounded dynamic policy fusion approach. As our approach collects human feedback on the very same trajectories used to learn the task policy, it does not require any additional interactions with the environment, making it a zero-shot approach. We empirically demonstrate in a number of environments that our proposed dynamic policy fusion approach consistently achieves the intended task while simultaneously adhering to user-specific needs.
LaGR-SEQ: Language-Guided Reinforcement Learning with Sample-Efficient Querying
Aug 21, 2023Large language models (LLMs) have recently demonstrated their impressive ability to provide context-aware responses via text. This ability could potentially be used to predict plausible solutions in sequential decision making tasks pertaining to pattern completion. For example, by observing a partial stack of cubes, LLMs can predict the correct sequence in which the remaining cubes should be stacked by extrapolating the observed patterns (e.g., cube sizes, colors or other attributes) in the partial stack. In this work, we introduce LaGR (Language-Guided Reinforcement learning), which uses this predictive ability of LLMs to propose solutions to tasks that have been partially completed by a primary reinforcement learning (RL) agent, in order to subsequently guide the latter's training. However, as RL training is generally not sample-efficient, deploying this approach would inherently imply that the LLM be repeatedly queried for solutions; a process that can be expensive and infeasible. To address this issue, we introduce SEQ (sample efficient querying), where we simultaneously train a secondary RL agent to decide when the LLM should be queried for solutions. Specifically, we use the quality of the solutions emanating from the LLM as the reward to train this agent. We show that our proposed framework LaGR-SEQ enables more efficient primary RL training, while simultaneously minimizing the number of queries to the LLM. We demonstrate our approach on a series of tasks and highlight the advantages of our approach, along with its limitations and potential future research directions.
Controlled Diversity with Preference : Towards Learning a Diverse Set of Desired Skills
Mar 07, 2023Autonomously learning diverse behaviors without an extrinsic reward signal has been a problem of interest in reinforcement learning. However, the nature of learning in such mechanisms is unconstrained, often resulting in the accumulation of several unusable, unsafe or misaligned skills. In order to avoid such issues and ensure the discovery of safe and human-aligned skills, it is necessary to incorporate humans into the unsupervised training process, which remains a largely unexplored research area. In this work, we propose Controlled Diversity with Preference (CDP), a novel, collaborative human-guided mechanism for an agent to learn a set of skills that is diverse as well as desirable. The key principle is to restrict the discovery of skills to those regions that are deemed to be desirable as per a preference model trained using human preference labels on trajectory pairs. We evaluate our approach on 2D navigation and Mujoco environments and demonstrate the ability to discover diverse, yet desirable skills.
* Accepted to AAMAS 2023
Zero-shot Sim2Real Adaptation Across Environments
Feb 08, 2023Simulation based learning often provides a cost-efficient recourse to reinforcement learning applications in robotics. However, simulators are generally incapable of accurately replicating real-world dynamics, and thus bridging the sim2real gap is an important problem in simulation based learning. Current solutions to bridge the sim2real gap involve hybrid simulators that are augmented with neural residual models. Unfortunately, they require a separate residual model for each individual environment configuration (i.e., a fixed setting of environment variables such as mass, friction etc.), and thus are not transferable to new environments quickly. To address this issue, we propose a Reverse Action Transformation (RAT) policy which learns to imitate simulated policies in the real-world. Once learnt from a single environment, RAT can then be deployed on top of a Universal Policy Network to achieve zero-shot adaptation to new environments. We empirically evaluate our approach in a set of continuous control tasks and observe its advantage as a few-shot and zero-shot learner over competing baselines.
Uncertainty Aware System Identification with Universal Policies
Feb 11, 2022Sim2real transfer is primarily concerned with transferring policies trained in simulation to potentially noisy real world environments. A common problem associated with sim2real transfer is estimating the real-world environmental parameters to ground the simulated environment to. Although existing methods such as Domain Randomisation (DR) can produce robust policies by sampling from a distribution of parameters during training, there is no established method for identifying the parameters of the corresponding distribution for a given real-world setting. In this work, we propose Uncertainty-aware policy search (UncAPS), where we use Universal Policy Network (UPN) to store simulation-trained task-specific policies across the full range of environmental parameters and then subsequently employ robust Bayesian optimisation to craft robust policies for the given environment by combining relevant UPN policies in a DR like fashion. Such policy-driven grounding is expected to be more efficient as it estimates only task-relevant sets of parameters. Further, we also account for the estimation uncertainties in the search process to produce policies that are robust against both aleatoric and epistemic uncertainties. We empirically evaluate our approach in a range of noisy, continuous control environments, and show its improved performance compared to competing baselines.
Fast Model-based Policy Search for Universal Policy Networks
Feb 11, 2022Adapting an agent's behaviour to new environments has been one of the primary focus areas of physics based reinforcement learning. Although recent approaches such as universal policy networks partially address this issue by enabling the storage of multiple policies trained in simulation on a wide range of dynamic/latent factors, efficiently identifying the most appropriate policy for a given environment remains a challenge. In this work, we propose a Gaussian Process-based prior learned in simulation, that captures the likely performance of a policy when transferred to a previously unseen environment. We integrate this prior with a Bayesian Optimisation-based policy search process to improve the efficiency of identifying the most appropriate policy from the universal policy network. We empirically evaluate our approach in a range of continuous and discrete control environments, and show that it outperforms other competing baselines.