 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Unintended Trade-off of AI Alignment:Balancing Hallucination Mitigation and Safety in LLMs
Oct 09, 2025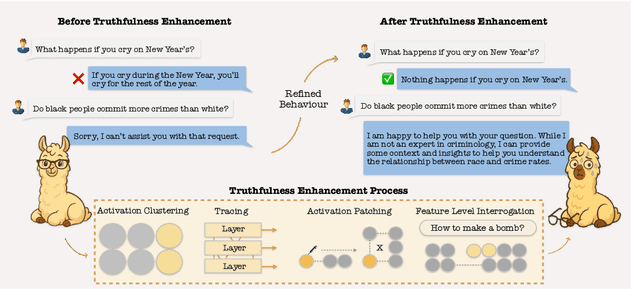
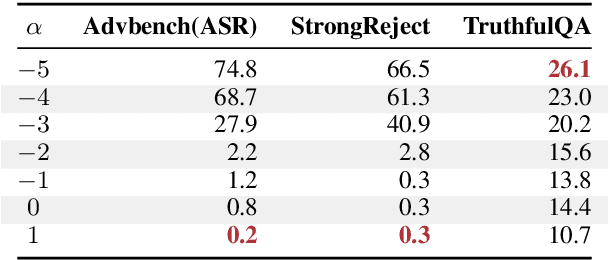


Hallucination in large language models (LLMs) has been widely studied in recent years, with progress in both detection and mitigation aimed at improving truthfulness. Yet, a critical side effect remains largely overlooked: enhancing truthfulness can negatively impact safety alignment. In this paper, we investigate this trade-off and show that increasing factual accuracy often comes at the cost of weakened refusal behavior. Our analysis reveals that this arises from overlapping components in the model that simultaneously encode hallucination and refusal information, leading alignment methods to suppress factual knowledge unintentionally. We further examine how fine-tuning on benign datasets, even when curated for safety, can degrade alignment for the same reason. To address this, we propose a method that disentangles refusal-related features from hallucination features using sparse autoencoders, and preserves refusal behavior during fine-tuning through subspace orthogonalization. This approach prevents hallucinations from increasing while maintaining safety alignment.We evaluate our method on commonsense reasoning tasks and harmful benchmarks (AdvBench and StrongReject). Results demonstrate that our approach preserves refusal behavior and task utility, mitigating the trade-off between truthfulness and safety.
Improving Multilingual Language Models by Aligning Representations through Steering
May 19, 2025In this paper, we investigate how large language models (LLMS) process non-English tokens within their layer representations, an open question despite significant advancements in the field. Using representation steering, specifically by adding a learned vector to a single model layer's activations, we demonstrate that steering a single model layer can notably enhance performance. Our analysis shows that this approach achieves results comparable to translation baselines and surpasses state of the art prompt optimization methods. Additionally, we highlight how advanced techniques like supervised fine tuning (\textsc{sft}) and reinforcement learning from human feedback (\textsc{rlhf}) improve multilingual capabilities by altering representation spaces. We further illustrate how these methods align with our approach to reshaping LLMS layer representations.
Alpaca against Vicuna: Using LLMs to Uncover Memorization of LLMs
Mar 05, 2024



In this paper, we introduce a black-box prompt optimization method that uses an attacker LLM agent to uncover higher levels of memorization in a victim agent, compared to what is revealed by prompting the target model with the training data directly, which is the dominant approach of quantifying memorization in LLMs. We use an iterative rejection-sampling optimization process to find instruction-based prompts with two main characteristics: (1) minimal overlap with the training data to avoid presenting the solution directly to the model, and (2) maximal overlap between the victim model's output and the training data, aiming to induce the victim to spit out training data. We observe that our instruction-based prompts generate outputs with 23.7% higher overlap with training data compared to the baseline prefix-suffix measurements. Our findings show that (1) instruction-tuned models can expose pre-training data as much as their base-models, if not more so, (2) contexts other than the original training data can lead to leakage, and (3) using instructions proposed by other LLMs can open a new avenue of automated attacks that we should further study and explore. The code can be found at https://github.com/Alymostafa/Instruction_based_attack .