 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShared Latent Structures Enable Unified Backdoor Detection and Mitigation in LLMs
Jun 06, 2026Backdoor attacks in large language models (LLMs) are often treated as isolated trigger-response failures, motivating defenses tailored to specific triggers or behaviors. We show this view is incomplete. Across diverse backdoor behaviors, we identify a shared latent mechanism that can be detected, causally controlled, and suppressed. Using sparse autoencoders (SAEs) on residual-stream activations, we find a small set of latent features consistently activated across jailbreaking, refusal manipulation, password-locking, bias induction, sentiment misclassification, and country-conditioned harmful advice. These features generalize across Qwen3, Gemma~3, and Llama~3.1 models from 4B to 32B parameters, and across both fine-tuning and weight-editing attacks. Through bidirectional activation steering, we show these features are causal: suppressing them reduces attack success, while amplifying them induces target behaviors on clean prompts. We further train lightweight SAE-feature classifiers that generalize zero-shot to unseen backdoors and outperform residual-stream and weight-diffing baselines. Finally, we introduce Concept Ablation Fine-Tuning (CAFT), which suppresses backdoor formation by ablating the shared latent subspace during training. Together, our results suggest that many backdoors rely on a transferable latent mechanism, enabling unified detection and mitigation.
Alpaca against Vicuna: Using LLMs to Uncover Memorization of LLMs
Mar 05, 2024



In this paper, we introduce a black-box prompt optimization method that uses an attacker LLM agent to uncover higher levels of memorization in a victim agent, compared to what is revealed by prompting the target model with the training data directly, which is the dominant approach of quantifying memorization in LLMs. We use an iterative rejection-sampling optimization process to find instruction-based prompts with two main characteristics: (1) minimal overlap with the training data to avoid presenting the solution directly to the model, and (2) maximal overlap between the victim model's output and the training data, aiming to induce the victim to spit out training data. We observe that our instruction-based prompts generate outputs with 23.7% higher overlap with training data compared to the baseline prefix-suffix measurements. Our findings show that (1) instruction-tuned models can expose pre-training data as much as their base-models, if not more so, (2) contexts other than the original training data can lead to leakage, and (3) using instructions proposed by other LLMs can open a new avenue of automated attacks that we should further study and explore. The code can be found at https://github.com/Alymostafa/Instruction_based_attack .
Finding a Needle in the Adversarial Haystack: A Targeted Paraphrasing Approach For Uncovering Edge Cases with Minimal Distribution Distortion
Feb 02, 2024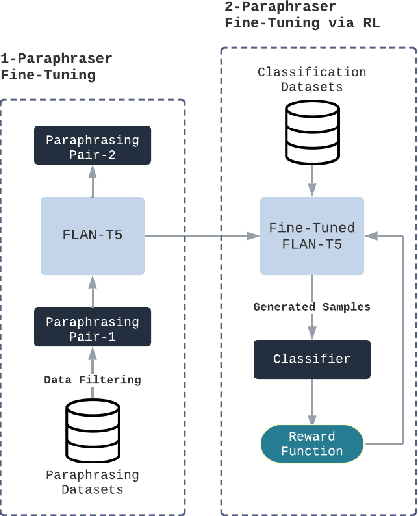
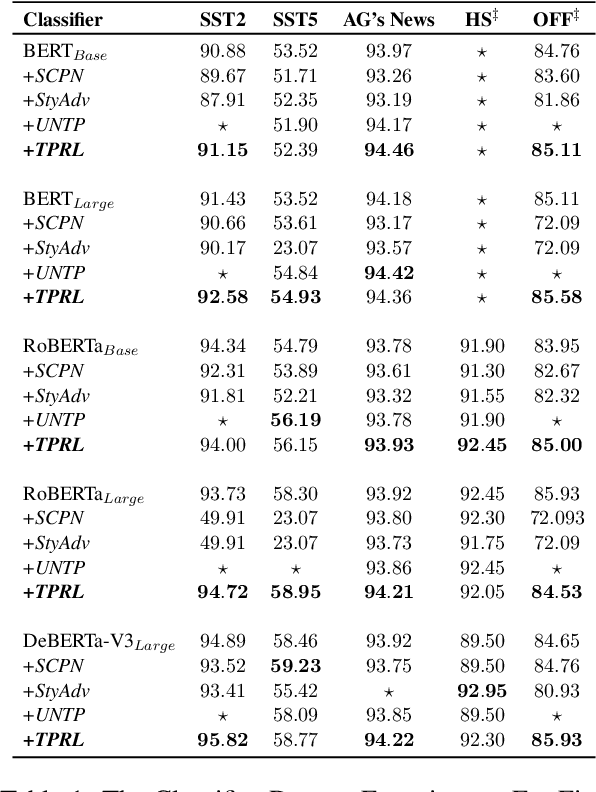
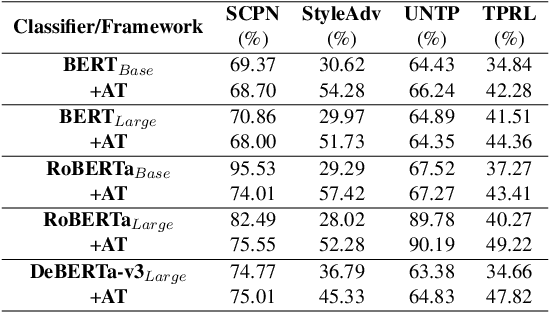
Adversarial attacks against language models(LMs) are a significant concern. In particular, adversarial samples exploit the model's sensitivity to small input changes. While these changes appear insignificant on the semantics of the input sample, they result in significant decay in model performance. In this paper, we propose Targeted Paraphrasing via RL (TPRL), an approach to automatically learn a policy to generate challenging samples that most likely improve the model's performance. TPRL leverages FLAN T5, a language model, as a generator and employs a self learned policy using a proximal policy gradient to generate the adversarial examples automatically. TPRL's reward is based on the confusion induced in the classifier, preserving the original text meaning through a Mutual Implication score. We demonstrate and evaluate TPRL's effectiveness in discovering natural adversarial attacks and improving model performance through extensive experiments on four diverse NLP classification tasks via Automatic and Human evaluation. TPRL outperforms strong baselines, exhibits generalizability across classifiers and datasets, and combines the strengths of language modeling and reinforcement learning to generate diverse and influential adversarial examples.
Mitigating Approximate Memorization in Language Models via Dissimilarity Learned Policy
May 02, 2023Large Language models (LLMs) are trained on large amounts of data, which can include sensitive information that may compromise personal privacy. LLMs showed to memorize parts of the training data and emit those data verbatim when an adversary prompts appropriately. Previous research has primarily focused on data preprocessing and differential privacy techniques to address memorization or prevent verbatim memorization exclusively, which can give a false sense of privacy. However, these methods rely on explicit and implicit assumptions about the structure of the data to be protected, which often results in an incomplete solution to the problem. To address this, we propose a novel framework that utilizes a reinforcement learning approach (PPO) to fine-tune LLMs to mitigate approximate memorization. Our approach utilizes a negative similarity score, such as BERTScore or SacreBLEU, as a reward signal to learn a dissimilarity policy. Our results demonstrate that this framework effectively mitigates approximate memorization while maintaining high levels of coherence and fluency in the generated samples. Furthermore, our framework is robust in mitigating approximate memorization across various circumstances, including longer context, which is known to increase memorization in LLMs.