 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding a Needle in the Adversarial Haystack: A Targeted Paraphrasing Approach For Uncovering Edge Cases with Minimal Distribution Distortion
Paper and Code
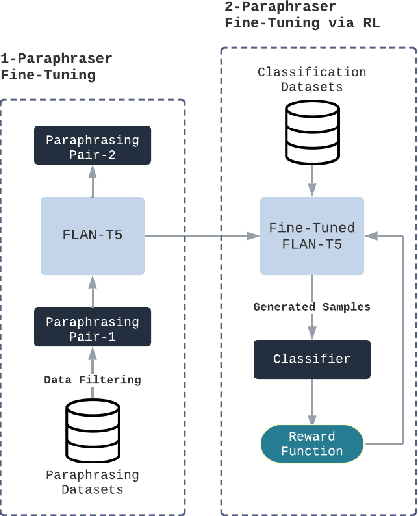
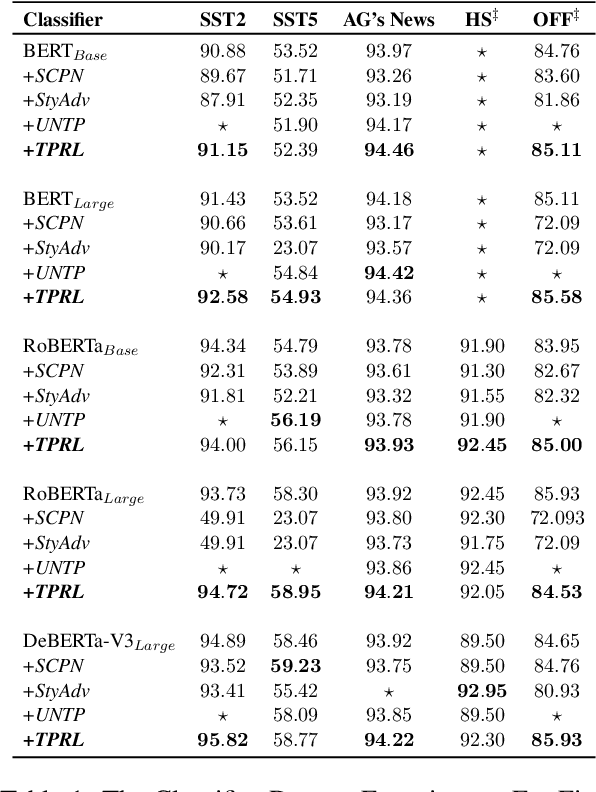
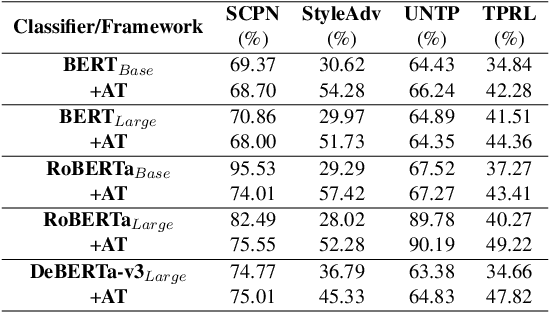
Adversarial attacks against language models(LMs) are a significant concern. In particular, adversarial samples exploit the model's sensitivity to small input changes. While these changes appear insignificant on the semantics of the input sample, they result in significant decay in model performance. In this paper, we propose Targeted Paraphrasing via RL (TPRL), an approach to automatically learn a policy to generate challenging samples that most likely improve the model's performance. TPRL leverages FLAN T5, a language model, as a generator and employs a self learned policy using a proximal policy gradient to generate the adversarial examples automatically. TPRL's reward is based on the confusion induced in the classifier, preserving the original text meaning through a Mutual Implication score. We demonstrate and evaluate TPRL's effectiveness in discovering natural adversarial attacks and improving model performance through extensive experiments on four diverse NLP classification tasks via Automatic and Human evaluation. TPRL outperforms strong baselines, exhibits generalizability across classifiers and datasets, and combines the strengths of language modeling and reinforcement learning to generate diverse and influential adversarial examples.