 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlpaca against Vicuna: Using LLMs to Uncover Memorization of LLMs
Mar 05, 2024



In this paper, we introduce a black-box prompt optimization method that uses an attacker LLM agent to uncover higher levels of memorization in a victim agent, compared to what is revealed by prompting the target model with the training data directly, which is the dominant approach of quantifying memorization in LLMs. We use an iterative rejection-sampling optimization process to find instruction-based prompts with two main characteristics: (1) minimal overlap with the training data to avoid presenting the solution directly to the model, and (2) maximal overlap between the victim model's output and the training data, aiming to induce the victim to spit out training data. We observe that our instruction-based prompts generate outputs with 23.7% higher overlap with training data compared to the baseline prefix-suffix measurements. Our findings show that (1) instruction-tuned models can expose pre-training data as much as their base-models, if not more so, (2) contexts other than the original training data can lead to leakage, and (3) using instructions proposed by other LLMs can open a new avenue of automated attacks that we should further study and explore. The code can be found at https://github.com/Alymostafa/Instruction_based_attack .
Finding a Needle in the Adversarial Haystack: A Targeted Paraphrasing Approach For Uncovering Edge Cases with Minimal Distribution Distortion
Feb 02, 2024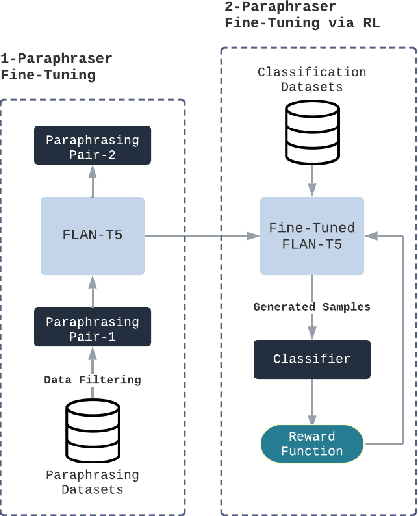
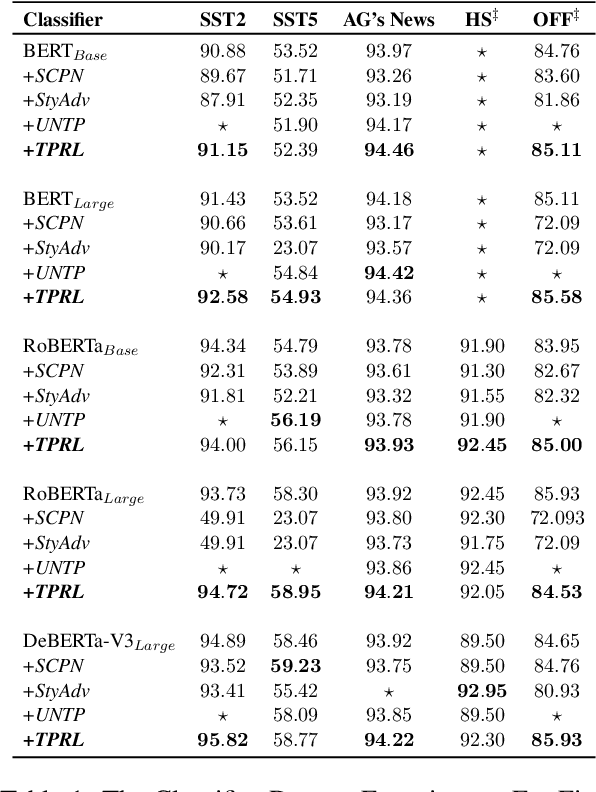
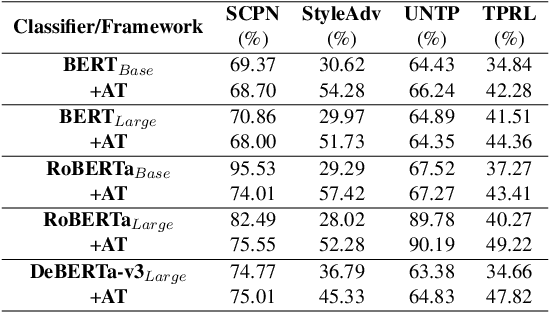
Adversarial attacks against language models(LMs) are a significant concern. In particular, adversarial samples exploit the model's sensitivity to small input changes. While these changes appear insignificant on the semantics of the input sample, they result in significant decay in model performance. In this paper, we propose Targeted Paraphrasing via RL (TPRL), an approach to automatically learn a policy to generate challenging samples that most likely improve the model's performance. TPRL leverages FLAN T5, a language model, as a generator and employs a self learned policy using a proximal policy gradient to generate the adversarial examples automatically. TPRL's reward is based on the confusion induced in the classifier, preserving the original text meaning through a Mutual Implication score. We demonstrate and evaluate TPRL's effectiveness in discovering natural adversarial attacks and improving model performance through extensive experiments on four diverse NLP classification tasks via Automatic and Human evaluation. TPRL outperforms strong baselines, exhibits generalizability across classifiers and datasets, and combines the strengths of language modeling and reinforcement learning to generate diverse and influential adversarial examples.
Interpreting Machine Learning Malware Detectors Which Leverage N-gram Analysis
Jan 27, 2020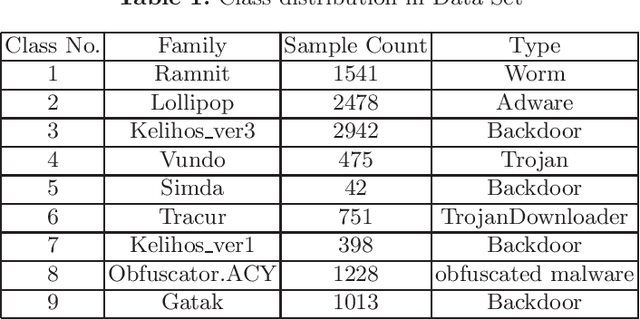
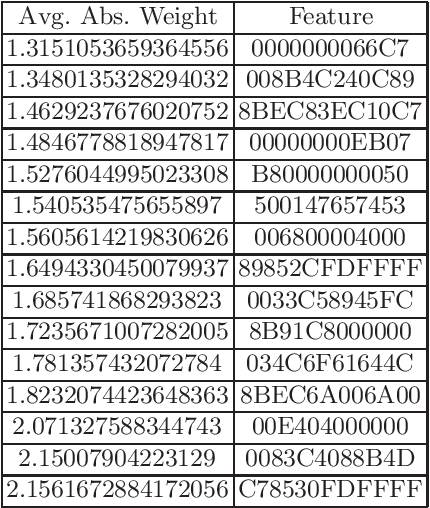
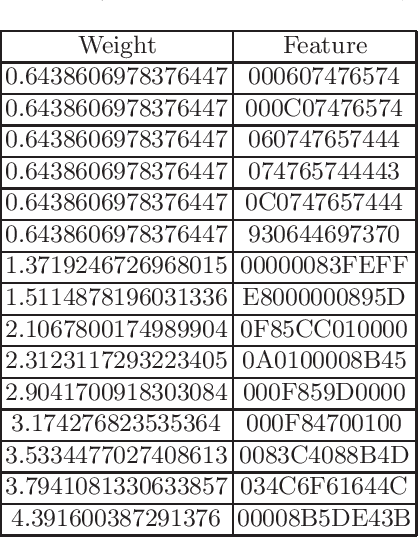
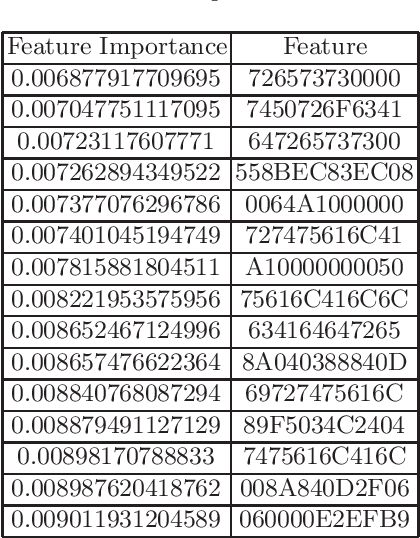
In cyberattack detection and prevention systems, cybersecurity analysts always prefer solutions that are as interpretable and understandable as rule-based or signature-based detection. This is because of the need to tune and optimize these solutions to mitigate and control the effect of false positives and false negatives. Interpreting machine learning models is a new and open challenge. However, it is expected that an interpretable machine learning solution will be domain-specific. For instance, interpretable solutions for machine learning models in healthcare are different than solutions in malware detection. This is because the models are complex, and most of them work as a black-box. Recently, the increased ability for malware authors to bypass antimalware systems has forced security specialists to look to machine learning for creating robust detection systems. If these systems are to be relied on in the industry, then, among other challenges, they must also explain their predictions. The objective of this paper is to evaluate the current state-of-the-art ML models interpretability techniques when applied to ML-based malware detectors. We demonstrate interpretability techniques in practice and evaluate the effectiveness of existing interpretability techniques in the malware analysis domain.
The Curious Case of Machine Learning In Malware Detection
May 18, 2019In this paper, we argue that machine learning techniques are not ready for malware detection in the wild. Given the current trend in malware development and the increase of unconventional malware attacks, we expect that dynamic malware analysis is the future for antimalware detection and prevention systems. A comprehensive review of machine learning for malware detection is presented. Then, we discuss how malware detection in the wild present unique challenges for the current state-of-the-art machine learning techniques. We defined three critical problems that limit the success of malware detectors powered by machine learning in the wild. Next, we discuss possible solutions to these challenges and present the requirements of next-generation malware detection. Finally, we outline potential research directions in machine learning for malware detection.
* 9 pages