 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting Machine Learning Malware Detectors Which Leverage N-gram Analysis
Paper and Code
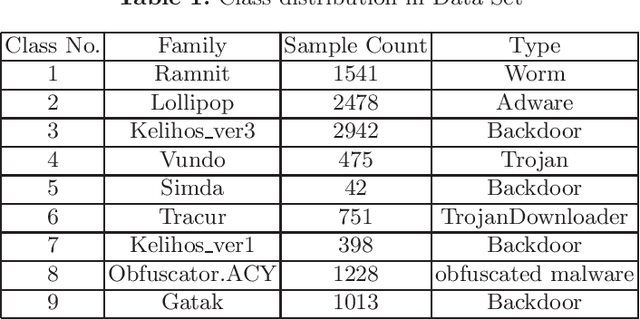
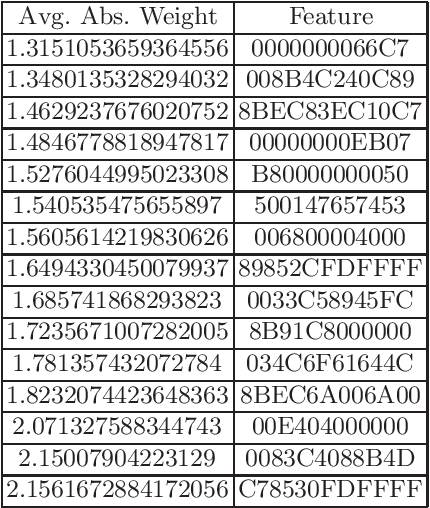
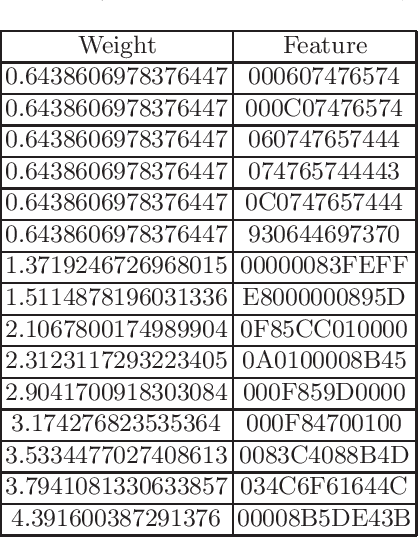
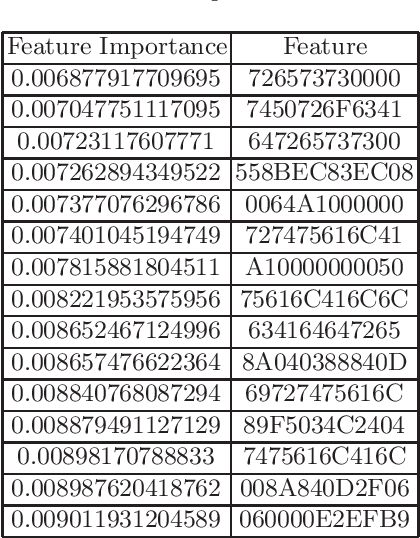
In cyberattack detection and prevention systems, cybersecurity analysts always prefer solutions that are as interpretable and understandable as rule-based or signature-based detection. This is because of the need to tune and optimize these solutions to mitigate and control the effect of false positives and false negatives. Interpreting machine learning models is a new and open challenge. However, it is expected that an interpretable machine learning solution will be domain-specific. For instance, interpretable solutions for machine learning models in healthcare are different than solutions in malware detection. This is because the models are complex, and most of them work as a black-box. Recently, the increased ability for malware authors to bypass antimalware systems has forced security specialists to look to machine learning for creating robust detection systems. If these systems are to be relied on in the industry, then, among other challenges, they must also explain their predictions. The objective of this paper is to evaluate the current state-of-the-art ML models interpretability techniques when applied to ML-based malware detectors. We demonstrate interpretability techniques in practice and evaluate the effectiveness of existing interpretability techniques in the malware analysis domain.