 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSRSR: Enhancing Semantic Accuracy in Real-World Image Super-Resolution with Spatially Re-Focused Text-Conditioning
Oct 26, 2025Existing diffusion-based super-resolution approaches often exhibit semantic ambiguities due to inaccuracies and incompleteness in their text conditioning, coupled with the inherent tendency for cross-attention to divert towards irrelevant pixels. These limitations can lead to semantic misalignment and hallucinated details in the generated high-resolution outputs. To address these, we propose a novel, plug-and-play spatially re-focused super-resolution (SRSR) framework that consists of two core components: first, we introduce Spatially Re-focused Cross-Attention (SRCA), which refines text conditioning at inference time by applying visually-grounded segmentation masks to guide cross-attention. Second, we introduce a Spatially Targeted Classifier-Free Guidance (STCFG) mechanism that selectively bypasses text influences on ungrounded pixels to prevent hallucinations. Extensive experiments on both synthetic and real-world datasets demonstrate that SRSR consistently outperforms seven state-of-the-art baselines in standard fidelity metrics (PSNR and SSIM) across all datasets, and in perceptual quality measures (LPIPS and DISTS) on two real-world benchmarks, underscoring its effectiveness in achieving both high semantic fidelity and perceptual quality in super-resolution.
BO-Muse: A human expert and AI teaming framework for accelerated experimental design
Mar 03, 2023In this paper we introduce BO-Muse, a new approach to human-AI teaming for the optimization of expensive black-box functions. Inspired by the intrinsic difficulty of extracting expert knowledge and distilling it back into AI models and by observations of human behaviour in real-world experimental design, our algorithm lets the human expert take the lead in the experimental process. The human expert can use their domain expertise to its full potential, while the AI plays the role of a muse, injecting novelty and searching for areas of weakness to break the human out of over-exploitation induced by cognitive entrenchment. With mild assumptions, we show that our algorithm converges sub-linearly, at a rate faster than the AI or human alone. We validate our algorithm using synthetic data and with human experts performing real-world experiments.
Memory-Constrained Policy Optimization
Apr 20, 2022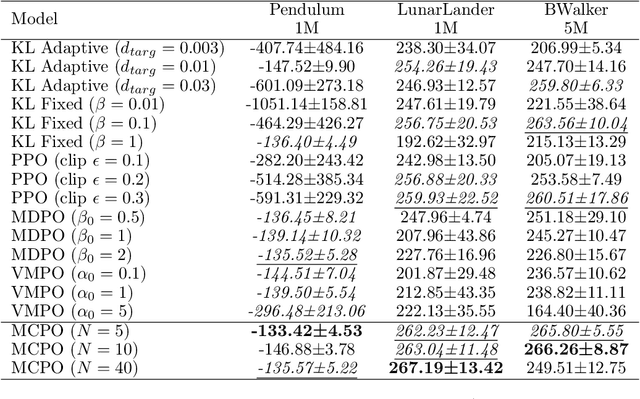


We introduce a new constrained optimization method for policy gradient reinforcement learning, which uses two trust regions to regulate each policy update. In addition to using the proximity of one single old policy as the first trust region as done by prior works, we propose to form a second trust region through the construction of another virtual policy that represents a wide range of past policies. We then enforce the new policy to stay closer to the virtual policy, which is beneficial in case the old policy performs badly. More importantly, we propose a mechanism to automatically build the virtual policy from a memory buffer of past policies, providing a new capability for dynamically selecting appropriate trust regions during the optimization process. Our proposed method, dubbed as Memory-Constrained Policy Optimization (MCPO), is examined on a diverse suite of environments including robotic locomotion control, navigation with sparse rewards and Atari games, consistently demonstrating competitive performance against recent on-policy constrained policy gradient methods.
Episodic Policy Gradient Training
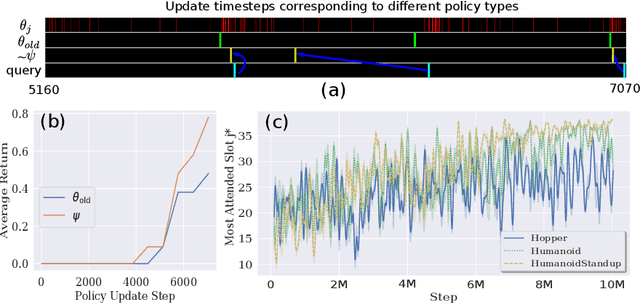
Dec 03, 2021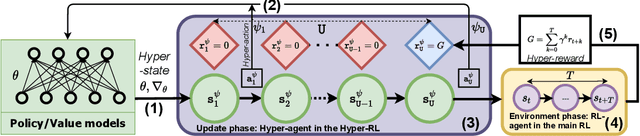

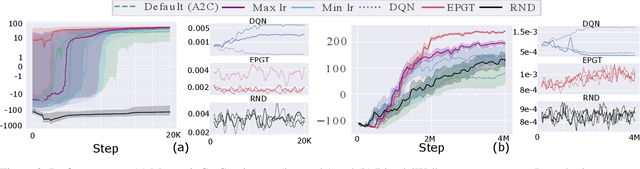
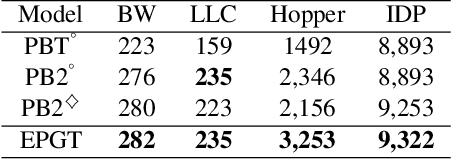
We introduce a novel training procedure for policy gradient methods wherein episodic memory is used to optimize the hyperparameters of reinforcement learning algorithms on-the-fly. Unlike other hyperparameter searches, we formulate hyperparameter scheduling as a standard Markov Decision Process and use episodic memory to store the outcome of used hyperparameters and their training contexts. At any policy update step, the policy learner refers to the stored experiences, and adaptively reconfigures its learning algorithm with the new hyperparameters determined by the memory. This mechanism, dubbed as Episodic Policy Gradient Training (EPGT), enables an episodic learning process, and jointly learns the policy and the learning algorithm's hyperparameters within a single run. Experimental results on both continuous and discrete environments demonstrate the advantage of using the proposed method in boosting the performance of various policy gradient algorithms.
Model-Based Episodic Memory Induces Dynamic Hybrid Controls
Nov 06, 2021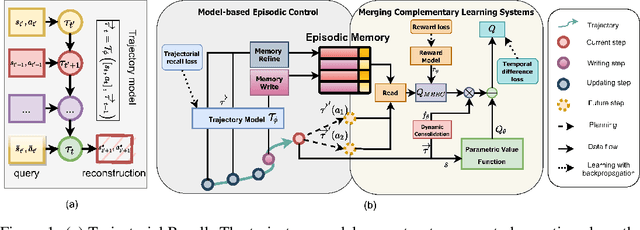
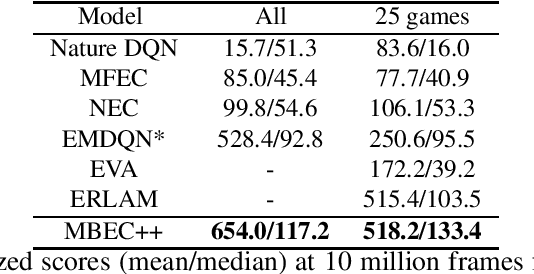
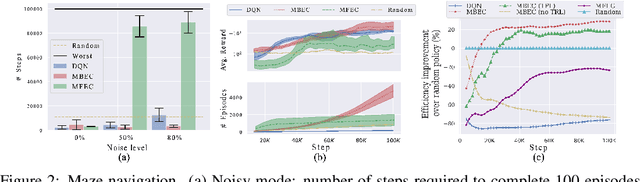
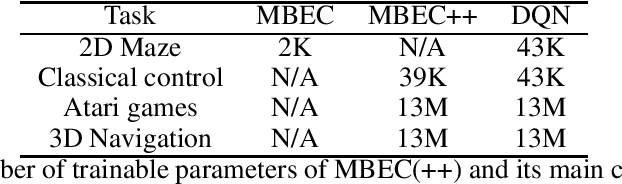
Episodic control enables sample efficiency in reinforcement learning by recalling past experiences from an episodic memory. We propose a new model-based episodic memory of trajectories addressing current limitations of episodic control. Our memory estimates trajectory values, guiding the agent towards good policies. Built upon the memory, we construct a complementary learning model via a dynamic hybrid control unifying model-based, episodic and habitual learning into a single architecture. Experiments demonstrate that our model allows significantly faster and better learning than other strong reinforcement learning agents across a variety of environments including stochastic and non-Markovian settings.
Balanced Q-learning: Combining the Influence of Optimistic and Pessimistic Targets
Nov 03, 2021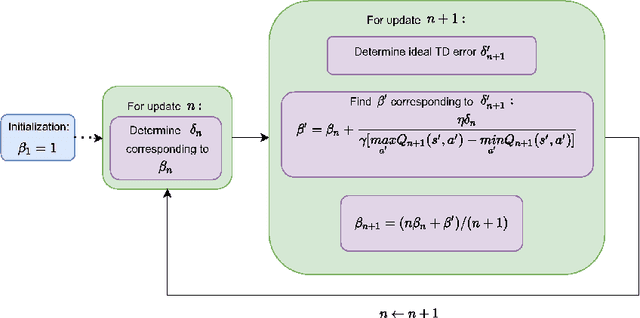
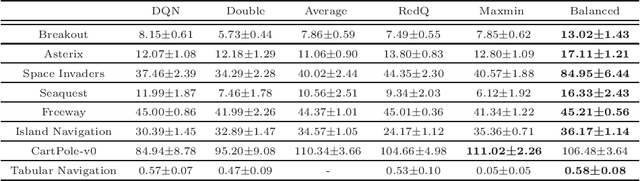
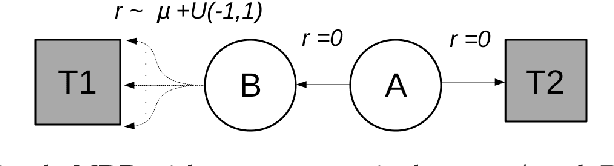
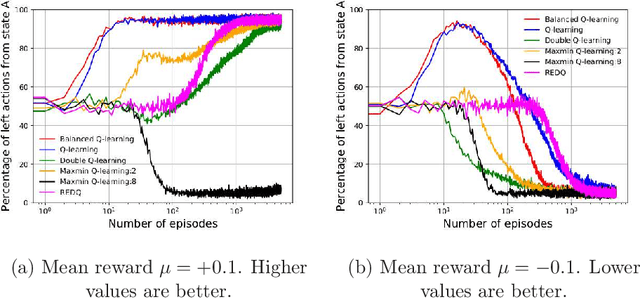
The optimistic nature of the Q-learning target leads to an overestimation bias, which is an inherent problem associated with standard $Q-$learning. Such a bias fails to account for the possibility of low returns, particularly in risky scenarios. However, the existence of biases, whether overestimation or underestimation, need not necessarily be undesirable. In this paper, we analytically examine the utility of biased learning, and show that specific types of biases may be preferable, depending on the scenario. Based on this finding, we design a novel reinforcement learning algorithm, Balanced Q-learning, in which the target is modified to be a convex combination of a pessimistic and an optimistic term, whose associated weights are determined online, analytically. We prove the convergence of this algorithm in a tabular setting, and empirically demonstrate its superior learning performance in various environments.
Plug and Play, Model-Based Reinforcement Learning
Aug 20, 2021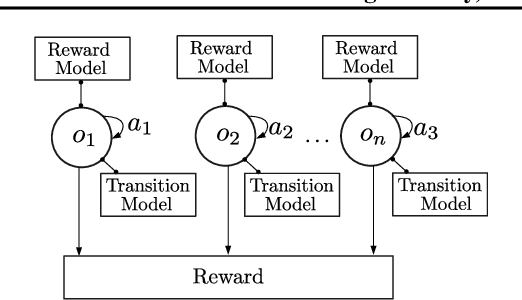
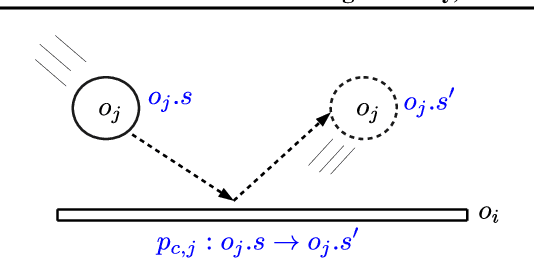
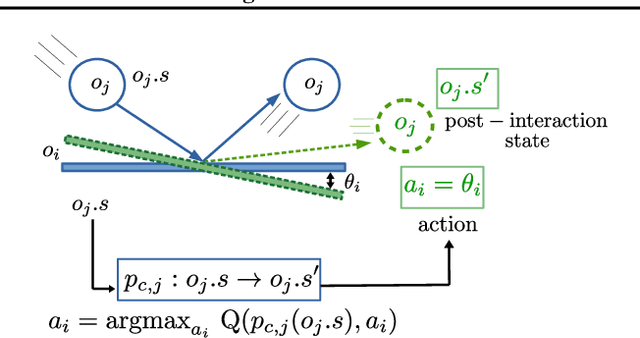
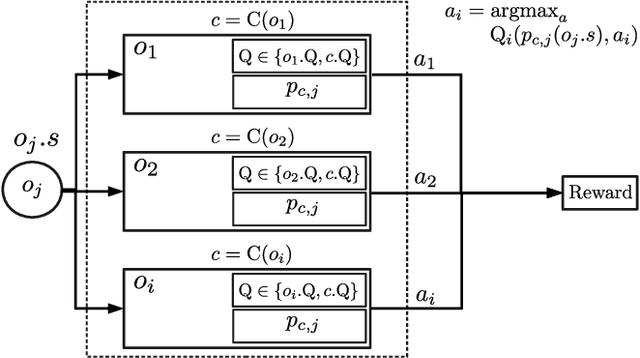
Sample-efficient generalisation of reinforcement learning approaches have always been a challenge, especially, for complex scenes with many components. In this work, we introduce Plug and Play Markov Decision Processes, an object-based representation that allows zero-shot integration of new objects from known object classes. This is achieved by representing the global transition dynamics as a union of local transition functions, each with respect to one active object in the scene. Transition dynamics from an object class can be pre-learnt and thus would be ready to use in a new environment. Each active object is also endowed with its reward function. Since there is no central reward function, addition or removal of objects can be handled efficiently by only updating the reward functions of objects involved. A new transfer learning mechanism is also proposed to adapt reward function in such cases. Experiments show that our representation can achieve sample-efficiency in a variety of set-ups.
A New Representation of Successor Features for Transfer across Dissimilar Environments
Jul 18, 2021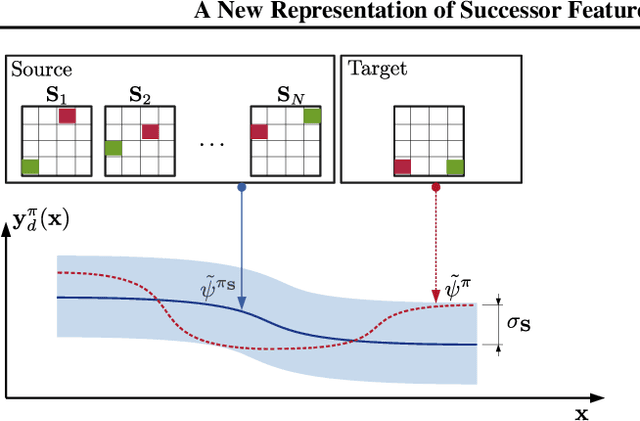
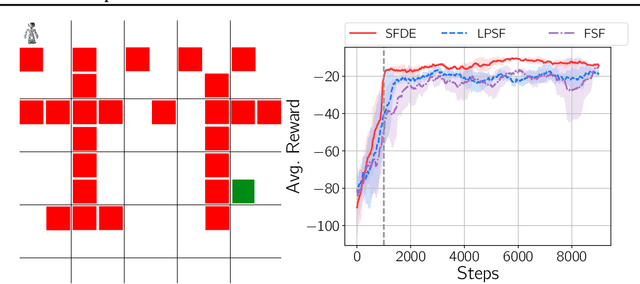
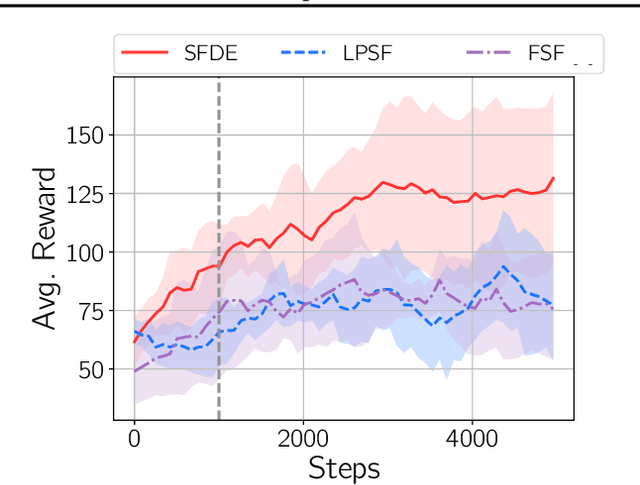
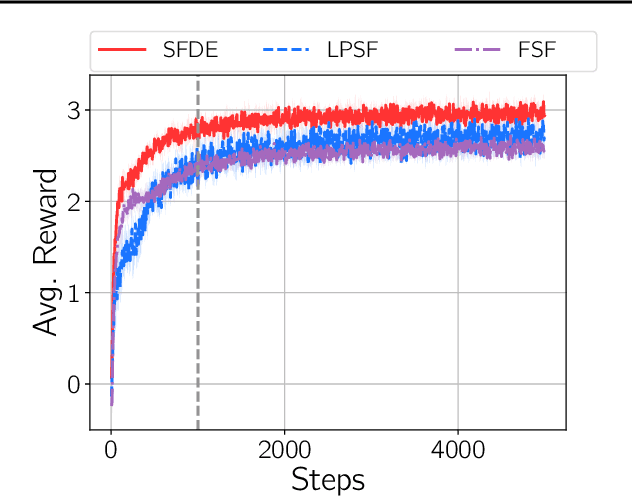
Transfer in reinforcement learning is usually achieved through generalisation across tasks. Whilst many studies have investigated transferring knowledge when the reward function changes, they have assumed that the dynamics of the environments remain consistent. Many real-world RL problems require transfer among environments with different dynamics. To address this problem, we propose an approach based on successor features in which we model successor feature functions with Gaussian Processes permitting the source successor features to be treated as noisy measurements of the target successor feature function. Our theoretical analysis proves the convergence of this approach as well as the bounded error on modelling successor feature functions with Gaussian Processes in environments with both different dynamics and rewards. We demonstrate our method on benchmark datasets and show that it outperforms current baselines.
Cost-aware Multi-objective Bayesian optimisation
Sep 09, 2019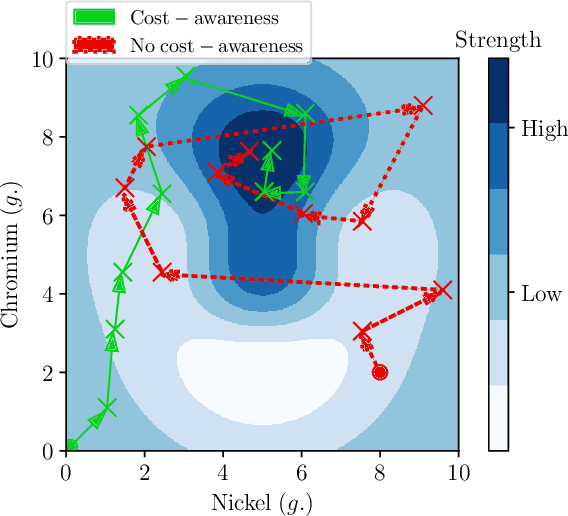
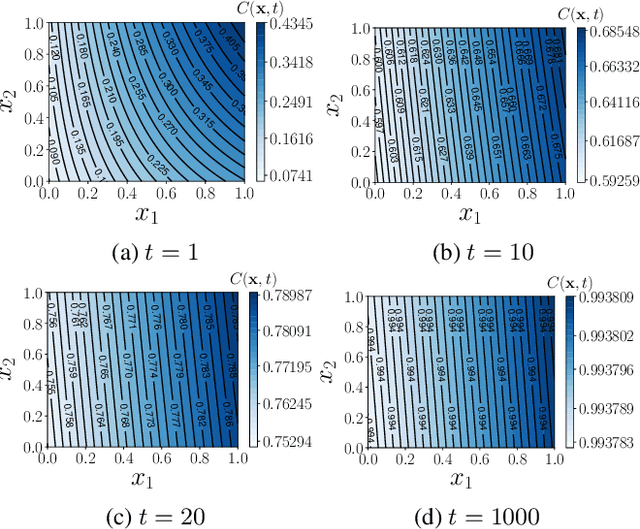
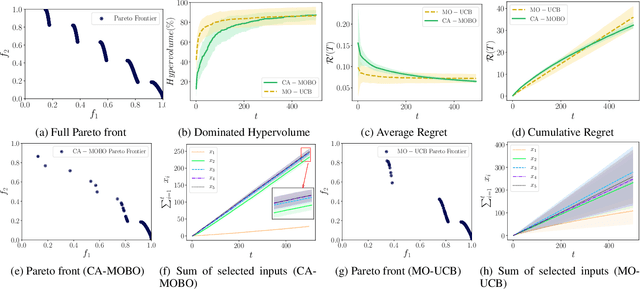
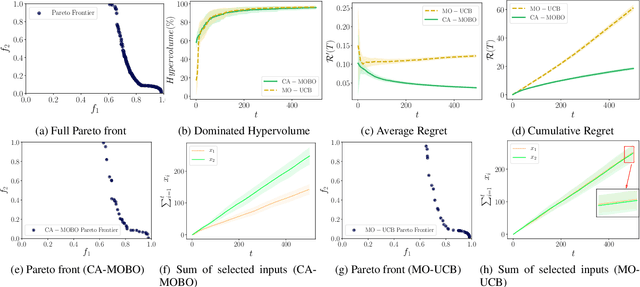
The notion of expense in Bayesian optimisation generally refers to the uniformly expensive cost of function evaluations over the whole search space. However, in some scenarios, the cost of evaluation for black-box objective functions is non-uniform since different inputs from search space may incur different costs for function evaluations. We introduce a cost-aware multi-objective Bayesian optimisation with non-uniform evaluation cost over objective functions by defining cost-aware constraints over the search space. The cost-aware constraints are a sorted tuple of indexes that demonstrate the ordering of dimensions of the search space based on the user's prior knowledge about their cost of usage. We formulate a new multi-objective Bayesian optimisation acquisition function with detailed analysis of the convergence that incorporates this cost-aware constraints while optimising the objective functions. We demonstrate our algorithm based on synthetic and real-world problems in hyperparameter tuning of neural networks and random forests.
Stable Bayesian Optimisation via Direct Stability Quantification
Feb 21, 2019
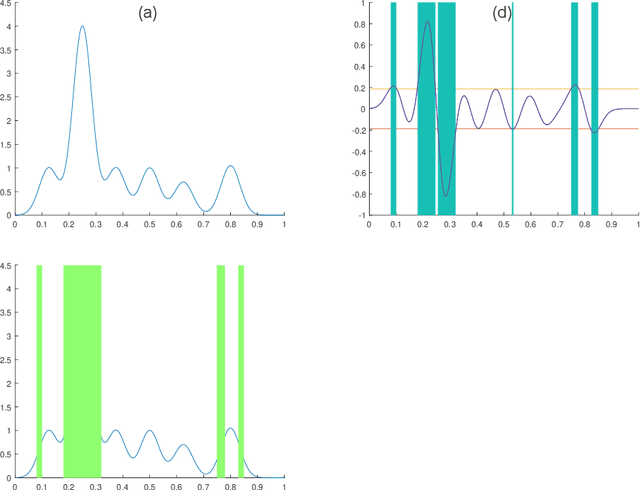
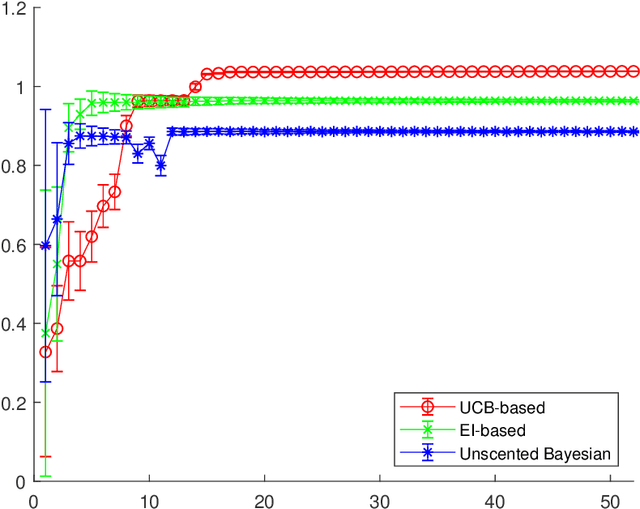
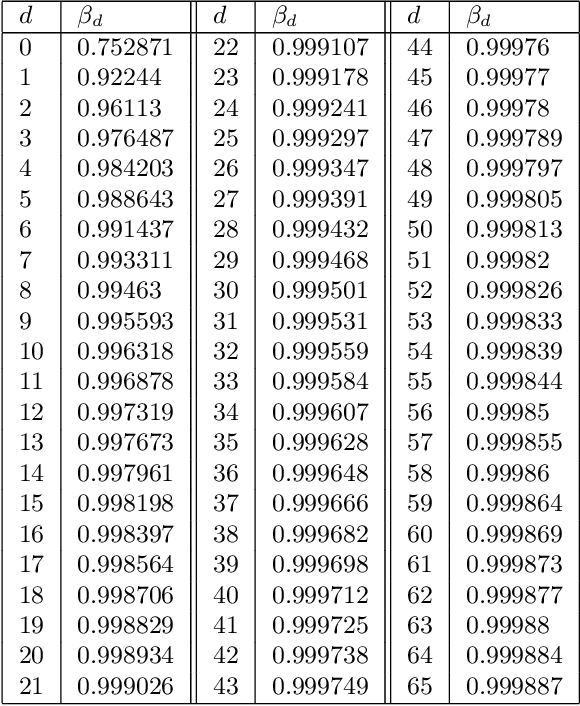
In this paper we consider the problem of finding stable maxima of expensive (to evaluate) functions. We are motivated by the optimisation of physical and industrial processes where, for some input ranges, small and unavoidable variations in inputs lead to unacceptably large variation in outputs. Our approach uses multiple gradient Gaussian Process models to estimate the probability that worst-case output variation for specified input perturbation exceeded the desired maxima, and these probabilities are then used to (a) guide the optimisation process toward solutions satisfying our stability criteria and (b) post-filter results to find the best stable solution. We exhibit our algorithm on synthetic and real-world problems and demonstrate that it is able to effectively find stable maxima.