 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMOTE: An Explainable architecture for Modelling the Other Through Empathy
Jun 01, 2023We can usually assume others have goals analogous to our own. This assumption can also, at times, be applied to multi-agent games - e.g. Agent 1's attraction to green pellets is analogous to Agent 2's attraction to red pellets. This "analogy" assumption is tied closely to the cognitive process known as empathy. Inspired by empathy, we design a simple and explainable architecture to model another agent's action-value function. This involves learning an "Imagination Network" to transform the other agent's observed state in order to produce a human-interpretable "empathetic state" which, when presented to the learning agent, produces behaviours that mimic the other agent. Our approach is applicable to multi-agent scenarios consisting of a single learning agent and other (independent) agents acting according to fixed policies. This architecture is particularly beneficial for (but not limited to) algorithms using a composite value or reward function. We show our method produces better performance in multi-agent games, where it robustly estimates the other's model in different environment configurations. Additionally, we show that the empathetic states are human interpretable, and thus verifiable.
Memory-Constrained Policy Optimization
Apr 20, 2022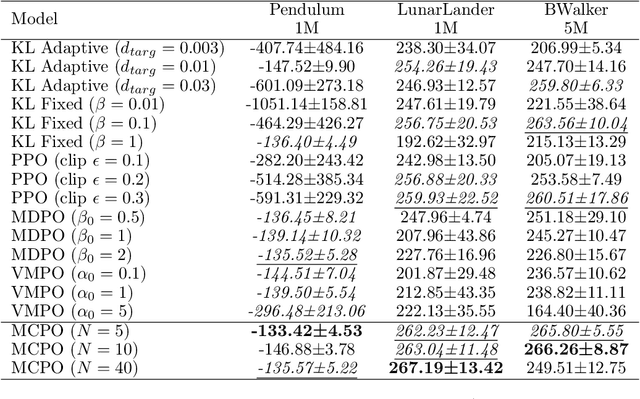


We introduce a new constrained optimization method for policy gradient reinforcement learning, which uses two trust regions to regulate each policy update. In addition to using the proximity of one single old policy as the first trust region as done by prior works, we propose to form a second trust region through the construction of another virtual policy that represents a wide range of past policies. We then enforce the new policy to stay closer to the virtual policy, which is beneficial in case the old policy performs badly. More importantly, we propose a mechanism to automatically build the virtual policy from a memory buffer of past policies, providing a new capability for dynamically selecting appropriate trust regions during the optimization process. Our proposed method, dubbed as Memory-Constrained Policy Optimization (MCPO), is examined on a diverse suite of environments including robotic locomotion control, navigation with sparse rewards and Atari games, consistently demonstrating competitive performance against recent on-policy constrained policy gradient methods.
Model-Based Episodic Memory Induces Dynamic Hybrid Controls
Nov 06, 2021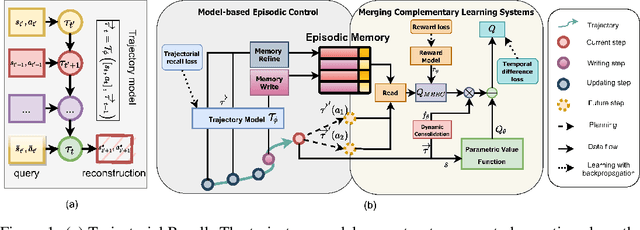
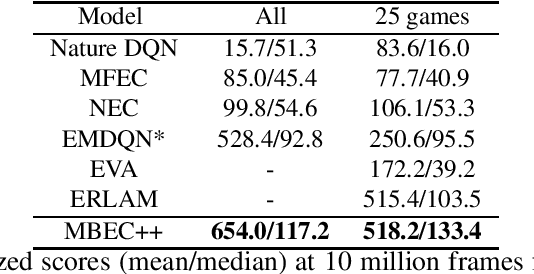
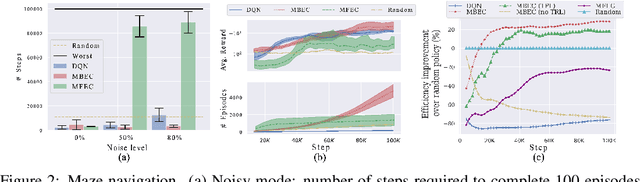
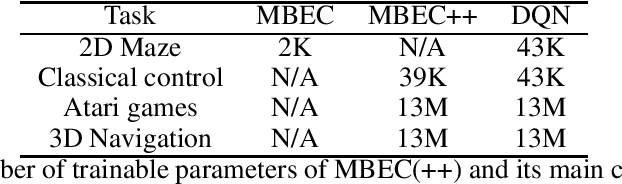
Episodic control enables sample efficiency in reinforcement learning by recalling past experiences from an episodic memory. We propose a new model-based episodic memory of trajectories addressing current limitations of episodic control. Our memory estimates trajectory values, guiding the agent towards good policies. Built upon the memory, we construct a complementary learning model via a dynamic hybrid control unifying model-based, episodic and habitual learning into a single architecture. Experiments demonstrate that our model allows significantly faster and better learning than other strong reinforcement learning agents across a variety of environments including stochastic and non-Markovian settings.
Plug and Play, Model-Based Reinforcement Learning
Aug 20, 2021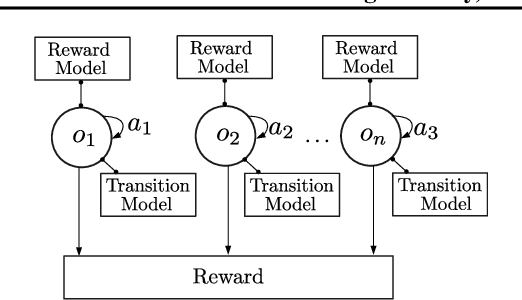
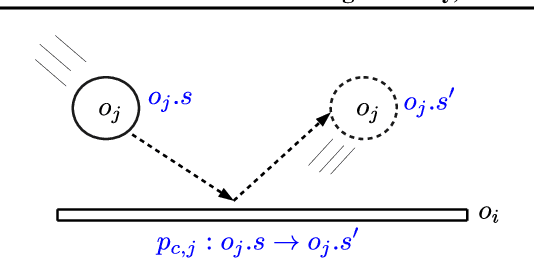
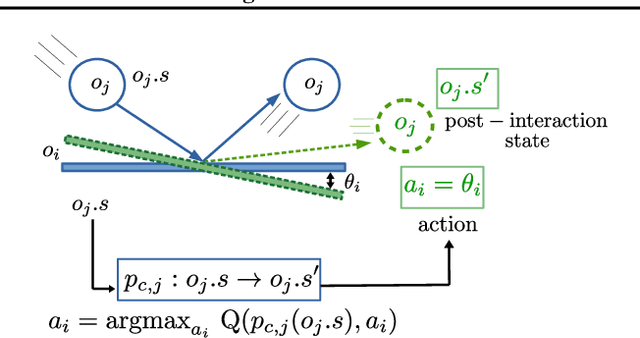
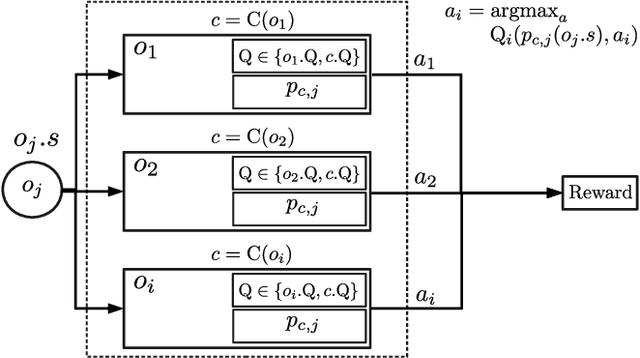
Sample-efficient generalisation of reinforcement learning approaches have always been a challenge, especially, for complex scenes with many components. In this work, we introduce Plug and Play Markov Decision Processes, an object-based representation that allows zero-shot integration of new objects from known object classes. This is achieved by representing the global transition dynamics as a union of local transition functions, each with respect to one active object in the scene. Transition dynamics from an object class can be pre-learnt and thus would be ready to use in a new environment. Each active object is also endowed with its reward function. Since there is no central reward function, addition or removal of objects can be handled efficiently by only updating the reward functions of objects involved. A new transfer learning mechanism is also proposed to adapt reward function in such cases. Experiments show that our representation can achieve sample-efficiency in a variety of set-ups.
A New Representation of Successor Features for Transfer across Dissimilar Environments
Jul 18, 2021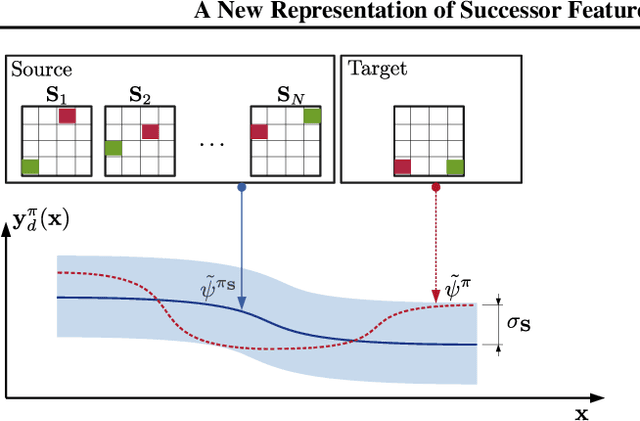
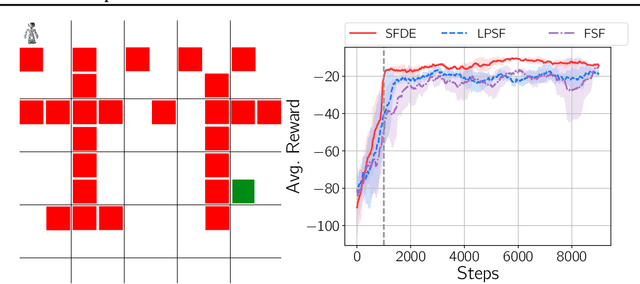
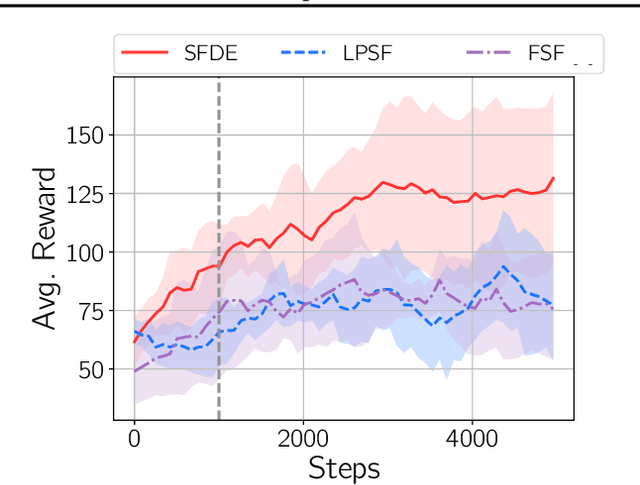
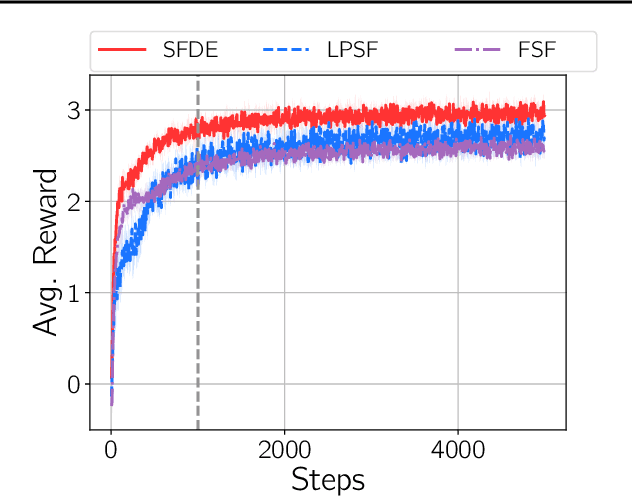
Transfer in reinforcement learning is usually achieved through generalisation across tasks. Whilst many studies have investigated transferring knowledge when the reward function changes, they have assumed that the dynamics of the environments remain consistent. Many real-world RL problems require transfer among environments with different dynamics. To address this problem, we propose an approach based on successor features in which we model successor feature functions with Gaussian Processes permitting the source successor features to be treated as noisy measurements of the target successor feature function. Our theoretical analysis proves the convergence of this approach as well as the bounded error on modelling successor feature functions with Gaussian Processes in environments with both different dynamics and rewards. We demonstrate our method on benchmark datasets and show that it outperforms current baselines.