 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlug and Play, Model-Based Reinforcement Learning
Paper and Code
Aug 20, 2021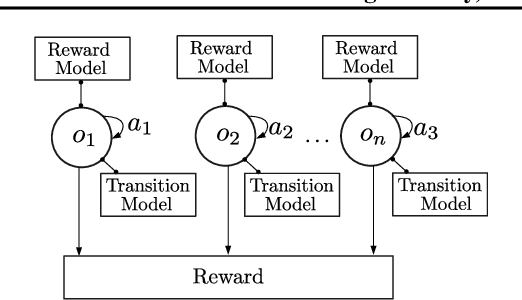
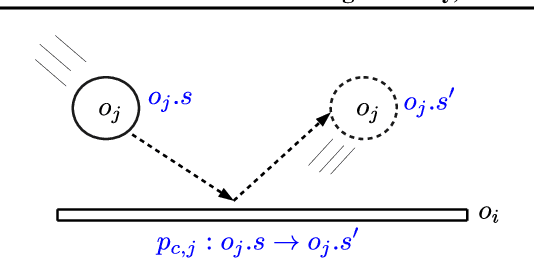
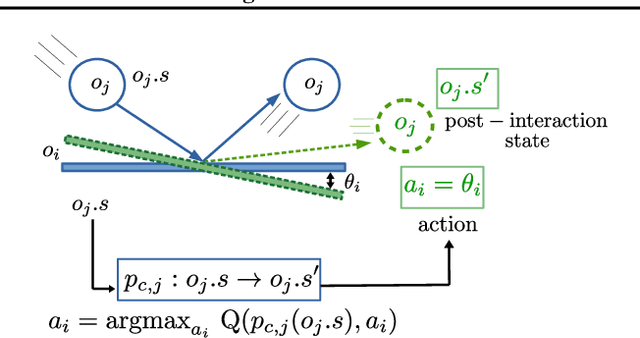
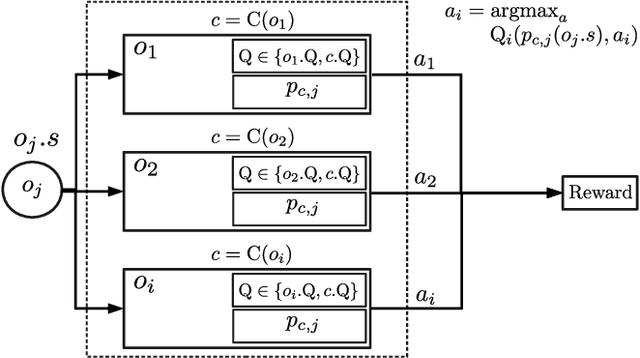
Sample-efficient generalisation of reinforcement learning approaches have always been a challenge, especially, for complex scenes with many components. In this work, we introduce Plug and Play Markov Decision Processes, an object-based representation that allows zero-shot integration of new objects from known object classes. This is achieved by representing the global transition dynamics as a union of local transition functions, each with respect to one active object in the scene. Transition dynamics from an object class can be pre-learnt and thus would be ready to use in a new environment. Each active object is also endowed with its reward function. Since there is no central reward function, addition or removal of objects can be handled efficiently by only updating the reward functions of objects involved. A new transfer learning mechanism is also proposed to adapt reward function in such cases. Experiments show that our representation can achieve sample-efficiency in a variety of set-ups.