 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing Fast and Slow: Bimodal 3D Scene Graphs for Open-set Tasks
May 29, 2026Open-set task execution can significantly benefit from seamlessly switching between coarse and fine scene representations depending on the context and the evolving information as the robot explores the environment. For example, it is often sufficient to start with a coarse scene representation initially and only employ a finer, more granular scene representation when the robot encounters regions which are likely to contain the task relevant objects. Hence, in this work, we propose BiMoSG, a bimodal 3D scene graph generation approach for open-set tasks. BiMoSG employs a "fast" mode by default to efficiently generate a coarse 3D scene graph and can switch to a "slow" mode for generating a finer open vocabulary 3D scene graph of task relevant objects. We demonstrate that our proposed 3D scene graph generation approach is significantly faster than the open-source state-of-the-art approaches. This allows us to integrate the scene graph generation process with task execution for real-time deployment.
Efficient Generation of Diverse Cooperative Agents with World Models
Jun 09, 2025A major bottleneck in the training process for Zero-Shot Coordination (ZSC) agents is the generation of partner agents that are diverse in collaborative conventions. Current Cross-play Minimization (XPM) methods for population generation can be very computationally expensive and sample inefficient as the training objective requires sampling multiple types of trajectories. Each partner agent in the population is also trained from scratch, despite all of the partners in the population learning policies of the same coordination task. In this work, we propose that simulated trajectories from the dynamics model of an environment can drastically speed up the training process for XPM methods. We introduce XPM-WM, a framework for generating simulated trajectories for XPM via a learned World Model (WM). We show XPM with simulated trajectories removes the need to sample multiple trajectories. In addition, we show our proposed method can effectively generate partners with diverse conventions that match the performance of previous methods in terms of SP population training reward as well as training partners for ZSC agents. Our method is thus, significantly more sample efficient and scalable to a larger number of partners.
MERLION: Marine ExploRation with Language guIded Online iNformative Visual Sampling and Enhancement
Mar 10, 2025Autonomous and targeted underwater visual monitoring and exploration using Autonomous Underwater Vehicles (AUVs) can be a challenging task due to both online and offline constraints. The online constraints comprise limited onboard storage capacity and communication bandwidth to the surface, whereas the offline constraints entail the time and effort required for the selection of desired key frames from the video data. An example use case of targeted underwater visual monitoring is finding the most interesting visual frames of fish in a long sequence of an AUV's visual experience. This challenge of targeted informative sampling is further aggravated in murky waters with poor visibility. In this paper, we present MERLION, a novel framework that provides semantically aligned and visually enhanced summaries for murky underwater marine environment monitoring and exploration. Specifically, our framework integrates (a) an image-text model for semantically aligning the visual samples to the users' needs, (b) an image enhancement model for murky water visual data and (c) an informative sampler for summarizing the monitoring experience. We validate our proposed MERLION framework on real-world data with user studies and present qualitative and quantitative results using our evaluation metric and show improved results compared to the state-of-the-art approaches. We have open-sourced the code for MERLION at the following link https://github.com/MARVL-Lab/MERLION.git.
Robot Guided Evacuation with Viewpoint Constraints
Sep 28, 2024
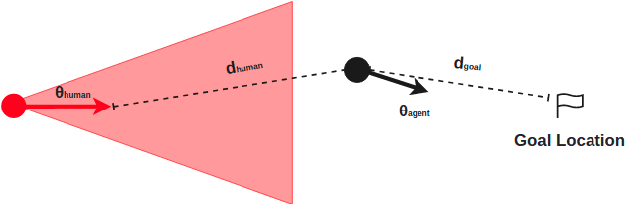
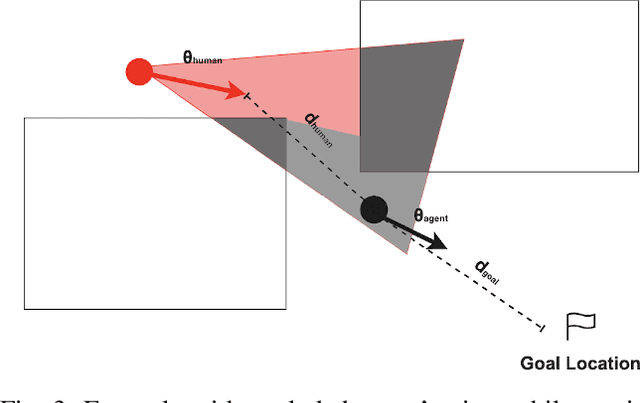
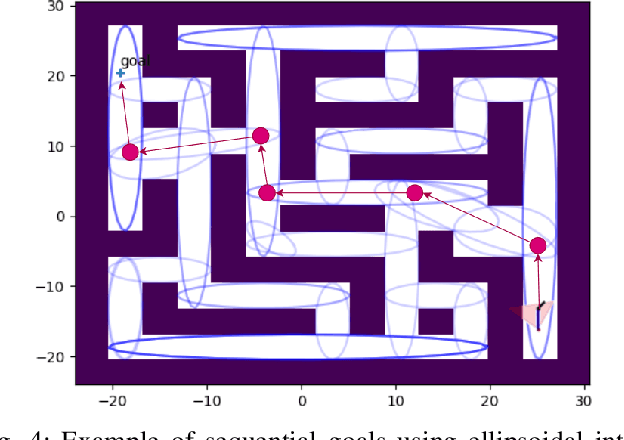
We present a viewpoint-based non-linear Model Predictive Control (MPC) for evacuation guiding robots. Specifically, the proposed MPC algorithm enables evacuation guiding robots to track and guide cooperative human targets in emergency scenarios. Our algorithm accounts for the environment layout as well as distances between the robot and human target and distance to the goal location. A key challenge for evacuation guiding robot is the trade-off between its planned motion for leading the target toward a goal position and staying in the target's viewpoint while maintaining line-of-sight for guiding. We illustrate the effectiveness of our proposed evacuation guiding algorithm in both simulated and real-world environments with an Unmanned Aerial Vehicle (UAV) guiding a human. Our results suggest that using the contextual information from the environment for motion planning, increases the visibility of the guiding UAV to the human while achieving faster total evacuation time.
Robust Vehicle Localization and Tracking in Rain using Street Maps
Sep 02, 2024



GPS-based vehicle localization and tracking suffers from unstable positional information commonly experienced in tunnel segments and in dense urban areas. Also, both Visual Odometry (VO) and Visual Inertial Odometry (VIO) are susceptible to adverse weather conditions that causes occlusions or blur on the visual input. In this paper, we propose a novel approach for vehicle localization that uses street network based map information to correct drifting odometry estimates and intermittent GPS measurements especially, in adversarial scenarios such as driving in rain and tunnels. Specifically, our approach is a flexible fusion algorithm that integrates intermittent GPS, drifting IMU and VO estimates together with 2D map information for robust vehicle localization and tracking. We refer to our approach as Map-Fusion. We robustly evaluate our proposed approach on four geographically diverse datasets from different countries ranging across clear and rain weather conditions. These datasets also include challenging visual segments in tunnels and underpasses. We show that with the integration of the map information, our Map-Fusion algorithm reduces the error of the state-of-the-art VO and VIO approaches across all datasets. We also validate our proposed algorithm in a real-world environment and in real-time on a hardware constrained mobile robot. Map-Fusion achieved 2.46m error in clear weather and 6.05m error in rain weather for a 150m route.
Online Informative Sampling using Semantic Features in Underwater Environments
Feb 06, 2024The underwater world remains largely unexplored, with Autonomous Underwater Vehicles (AUVs) playing a crucial role in sub-sea explorations. However, continuous monitoring of underwater environments using AUVs can generate a significant amount of data. In addition, sending live data feed from an underwater environment requires dedicated on-board data storage options for AUVs which can hinder requirements of other higher priority tasks. Informative sampling techniques offer a solution by condensing observations. In this paper, we present a semantically-aware online informative sampling (ON-IS) approach which samples an AUV's visual experience in real-time. Specifically, we obtain visual features from a fine-tuned object detection model to align the sampling outcomes with the desired semantic information. Our contributions are (a) a novel Semantic Online Informative Sampling (SON-IS) algorithm, (b) a user study to validate the proposed approach and (c) a novel evaluation metric to score our proposed algorithm with respect to the suggested samples by human subjects
Evaluating Visual Odometry Methods for Autonomous Driving in Rain
Sep 11, 2023



The increasing demand for autonomous vehicles has created a need for robust navigation systems that can also operate effectively in adverse weather conditions. Visual odometry is a technique used in these navigation systems, enabling the estimation of vehicle position and motion using input from onboard cameras. However, visual odometry accuracy can be significantly impacted in challenging weather conditions, such as heavy rain, snow, or fog. In this paper, we evaluate a range of visual odometry methods, including our DROIDSLAM based heuristic approach. Specifically, these algorithms are tested on both clear and rainy weather urban driving data to evaluate their robustness. We compiled a dataset comprising of a range of rainy weather conditions from different cities. This includes, the Oxford Robotcar dataset from Oxford, the 4Seasons dataset from Munich and an internal dataset collected in Singapore. We evaluated different visual odometry algorithms for both monocular and stereo camera setups using the Absolute Trajectory Error (ATE). Our evaluation suggests that the Depth and Flow for Visual Odometry (DF-VO) algorithm with monocular setup worked well for short range distances (< 500m) and our proposed DROID-SLAM based heuristic approach for the stereo setup performed relatively well for long-term localization. Both algorithms performed consistently well across all rain conditions.
Localization with Anticipation for Autonomous Urban Driving in Rain
Jun 15, 2023



This paper presents a localization algorithm for autonomous urban vehicles under rain weather conditions. In adverse weather, human drivers anticipate the location of the ego-vehicle based on the control inputs they provide and surrounding road contextual information. Similarly, in our approach for localization in rain weather, we use visual data, along with a global reference path and vehicle motion model for anticipating and better estimating the pose of the ego-vehicle in each frame. The global reference path contains useful road contextual information such as the angle of turn which can be potentially used to improve the localization accuracy especially when sensors are compromised. We experimented on the Oxford Robotcar Dataset and our internal dataset from Singapore to validate our localization algorithm in both clear and rain weather conditions. Our method improves localization accuracy by 50.83% in rain weather and 34.32% in clear weather when compared to baseline algorithms.
A Hierarchical Approach to Population Training for Human-AI Collaboration
May 26, 2023A major challenge for deep reinforcement learning (DRL) agents is to collaborate with novel partners that were not encountered by them during the training phase. This is specifically worsened by an increased variance in action responses when the DRL agents collaborate with human partners due to the lack of consistency in human behaviors. Recent work have shown that training a single agent as the best response to a diverse population of training partners significantly increases an agent's robustness to novel partners. We further enhance the population-based training approach by introducing a Hierarchical Reinforcement Learning (HRL) based method for Human-AI Collaboration. Our agent is able to learn multiple best-response policies as its low-level policy while at the same time, it learns a high-level policy that acts as a manager which allows the agent to dynamically switch between the low-level best-response policies based on its current partner. We demonstrate that our method is able to dynamically adapt to novel partners of different play styles and skill levels in the 2-player collaborative Overcooked game environment. We also conducted a human study in the same environment to test the effectiveness of our method when partnering with real human subjects.
Multi-Target Pursuit by a Decentralized Heterogeneous UAV Swarm using Deep Multi-Agent Reinforcement Learning
Mar 03, 2023Multi-agent pursuit-evasion tasks involving intelligent targets are notoriously challenging coordination problems. In this paper, we investigate new ways to learn such coordinated behaviors of unmanned aerial vehicles (UAVs) aimed at keeping track of multiple evasive targets. Within a Multi-Agent Reinforcement Learning (MARL) framework, we specifically propose a variant of the Multi-Agent Deep Deterministic Policy Gradient (MADDPG) method. Our approach addresses multi-target pursuit-evasion scenarios within non-stationary and unknown environments with random obstacles. In addition, given the critical role played by collective exploration in terms of detecting possible targets, we implement heterogeneous roles for the pursuers for enhanced exploratory actions balanced by exploitation (i.e. tracking) of previously identified targets. Our proposed role-based MADDPG algorithm is not only able to track multiple targets, but also is able to explore for possible targets by means of the proposed Voronoi-based rewarding policy. We implemented, tested and validated our approach in a simulation environment prior to deploying a real-world multi-robot system comprising of Crazyflie drones. Our results demonstrate that a multi-agent pursuit team has the ability to learn highly efficient coordinated control policies in terms of target tracking and exploration even when confronted with multiple fast evasive targets in complex environments.