 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMI9 -- Agent Intelligence Protocol: Runtime Governance for Agentic AI Systems
Aug 05, 2025Agentic AI systems capable of reasoning, planning, and executing actions present fundamentally distinct governance challenges compared to traditional AI models. Unlike conventional AI, these systems exhibit emergent and unexpected behaviors during runtime, introducing novel agent-related risks that cannot be fully anticipated through pre-deployment governance alone. To address this critical gap, we introduce MI9, the first fully integrated runtime governance framework designed specifically for safety and alignment of agentic AI systems. MI9 introduces real-time controls through six integrated components: agency-risk index, agent-semantic telemetry capture, continuous authorization monitoring, Finite-State-Machine (FSM)-based conformance engines, goal-conditioned drift detection, and graduated containment strategies. Operating transparently across heterogeneous agent architectures, MI9 enables the systematic, safe, and responsible deployment of agentic systems in production environments where conventional governance approaches fall short, providing the foundational infrastructure for safe agentic AI deployment at scale. Detailed analysis through a diverse set of scenarios demonstrates MI9's systematic coverage of governance challenges that existing approaches fail to address, establishing the technical foundation for comprehensive agentic AI oversight.
Analyzing Scientific Publications using Domain-Specific Word Embedding and Topic Modelling
Dec 24, 2021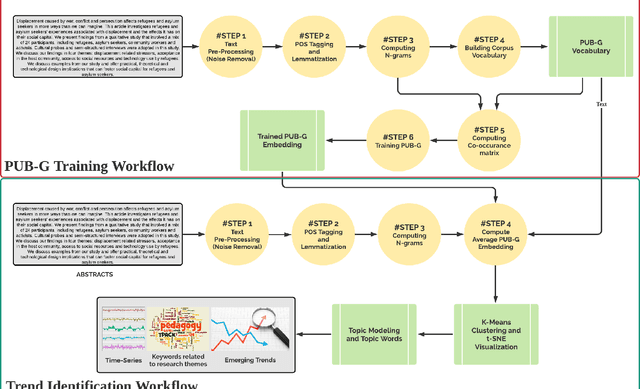
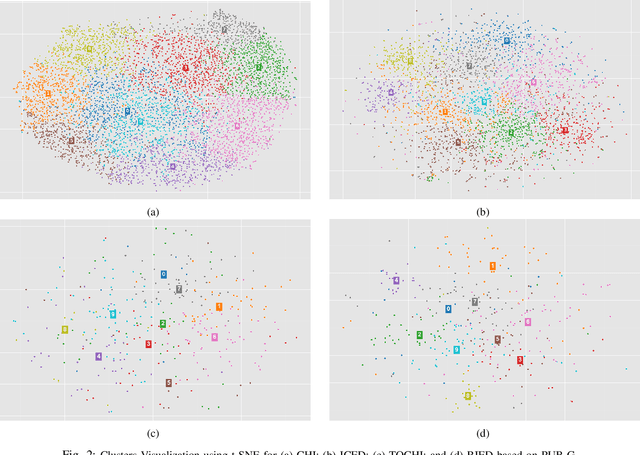
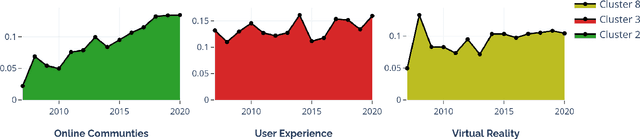
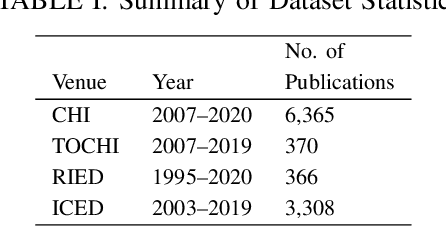
The scientific world is changing at a rapid pace, with new technology being developed and new trends being set at an increasing frequency. This paper presents a framework for conducting scientific analyses of academic publications, which is crucial to monitor research trends and identify potential innovations. This framework adopts and combines various techniques of Natural Language Processing, such as word embedding and topic modelling. Word embedding is used to capture semantic meanings of domain-specific words. We propose two novel scientific publication embedding, i.e., PUB-G and PUB-W, which are capable of learning semantic meanings of general as well as domain-specific words in various research fields. Thereafter, topic modelling is used to identify clusters of research topics within these larger research fields. We curated a publication dataset consisting of two conferences and two journals from 1995 to 2020 from two research domains. Experimental results show that our PUB-G and PUB-W embeddings are superior in comparison to other baseline embeddings by a margin of ~0.18-1.03 based on topic coherence.
Photozilla: A Large-Scale Photography Dataset and Visual Embedding for 20 Photography Styles
Jun 21, 2021


The advent of social media platforms has been a catalyst for the development of digital photography that engendered a boom in vision applications. With this motivation, we introduce a large-scale dataset termed 'Photozilla', which includes over 990k images belonging to 10 different photographic styles. The dataset is then used to train 3 classification models to automatically classify the images into the relevant style which resulted in an accuracy of ~96%. With the rapid evolution of digital photography, we have seen new types of photography styles emerging at an exponential rate. On that account, we present a novel Siamese-based network that uses the trained classification models as the base architecture to adapt and classify unseen styles with only 25 training samples. We report an accuracy of over 68% for identifying 10 other distinct types of photography styles. This dataset can be found at https://trisha025.github.io/Photozilla/
EPIC30M: An Epidemics Corpus Of Over 30 Million Relevant Tweets
Jun 22, 2020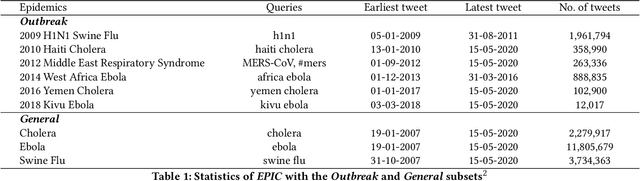

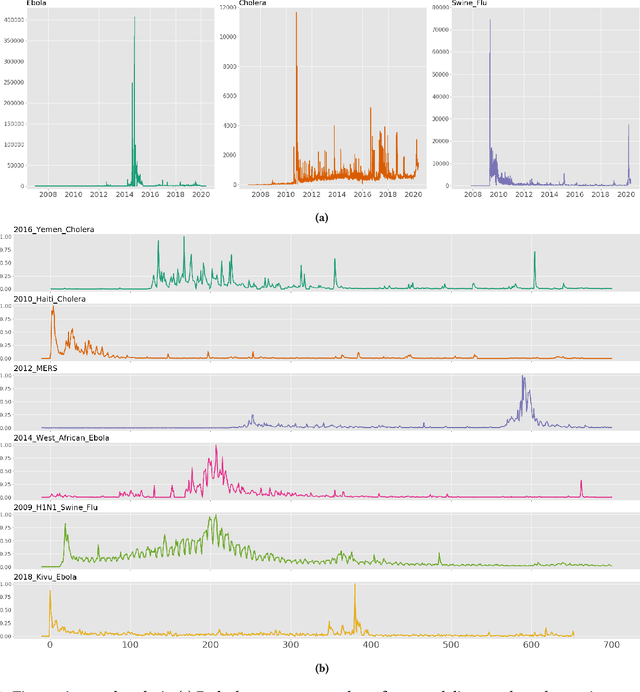
Since the start of COVID-19, several relevant corpora from various sources are presented in the literature that contain millions of data points. While these corpora are valuable in supporting many analyses on this specific pandemic, researchers require additional benchmark corpora that contain other epidemics to facilitate cross-epidemic pattern recognition and trend analysis tasks. During our other efforts on COVID-19 related work, we discover very little disease related corpora in the literature that are sizable and rich enough to support such cross-epidemic analysis tasks. In this paper, we present EPIC30M, a large-scale epidemic corpus that contains 30 millions micro-blog posts, i.e., tweets crawled from Twitter, from year 2006 to 2020. EPIC30M contains a subset of 26.2 millions tweets related to three general diseases, namely Ebola, Cholera and Swine Flu, and another subset of 4.7 millions tweets of six global epidemic outbreaks, including 2009 H1N1 Swine Flu, 2010 Haiti Cholera, 2012 Middle-East Respiratory Syndrome (MERS), 2013 West African Ebola, 2016 Yemen Cholera and 2018 Kivu Ebola. Furthermore, we explore and discuss the properties of the corpus with statistics of key terms and hashtags and trends analysis for each subset. Finally, we demonstrate the value and impact that EPIC30M could create through a discussion of multiple use cases of cross-epidemic research topics that attract growing interest in recent years. These use cases span multiple research areas, such as epidemiological modeling, pattern recognition, natural language understanding and economical modeling.
CrisisBERT: a Robust Transformer for Crisis Classification and Contextual Crisis Embedding
May 18, 2020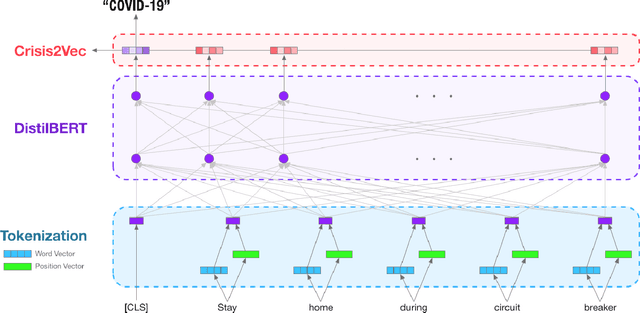

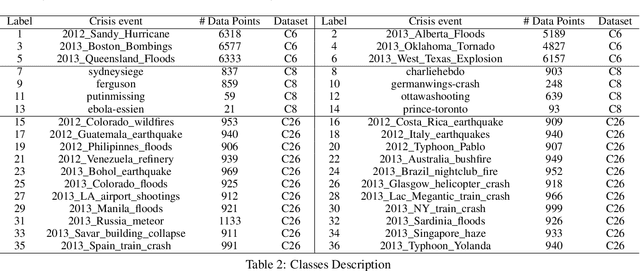
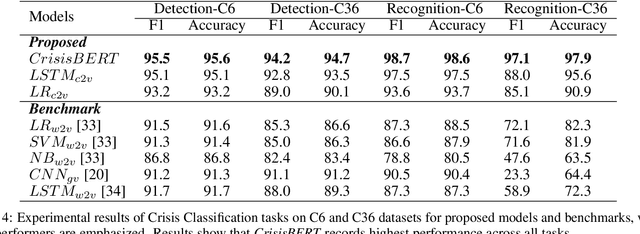
Classification of crisis events, such as natural disasters, terrorist attacks and pandemics, is a crucial task to create early signals and inform relevant parties for spontaneous actions to reduce overall damage. Despite crisis such as natural disasters can be predicted by professional institutions, certain events are first signaled by civilians, such as the recent COVID-19 pandemics. Social media platforms such as Twitter often exposes firsthand signals on such crises through high volume information exchange over half a billion tweets posted daily. Prior works proposed various crisis embeddings and classification using conventional Machine Learning and Neural Network models. However, none of the works perform crisis embedding and classification using state of the art attention-based deep neural networks models, such as Transformers and document-level contextual embeddings. This work proposes CrisisBERT, an end-to-end transformer-based model for two crisis classification tasks, namely crisis detection and crisis recognition, which shows promising results across accuracy and f1 scores. The proposed model also demonstrates superior robustness over benchmark, as it shows marginal performance compromise while extending from 6 to 36 events with only 51.4% additional data points. We also proposed Crisis2Vec, an attention-based, document-level contextual embedding architecture for crisis embedding, which achieve better performance than conventional crisis embedding methods such as Word2Vec and GloVe. To the best of our knowledge, our works are first to propose using transformer-based crisis classification and document-level contextual crisis embedding in the literature.