 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScanpath Prediction on Information Visualisations
Paper and Code
Dec 04, 2021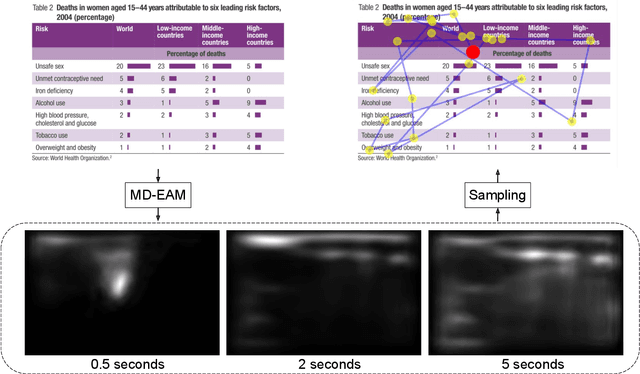
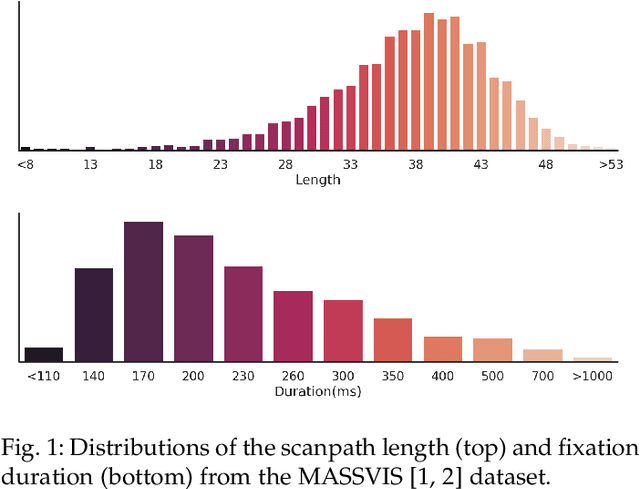
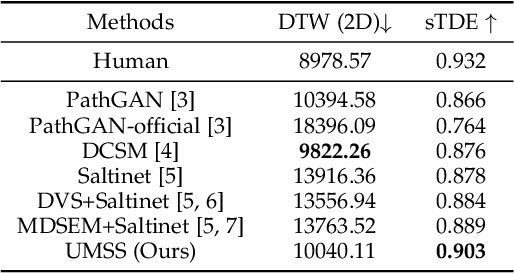
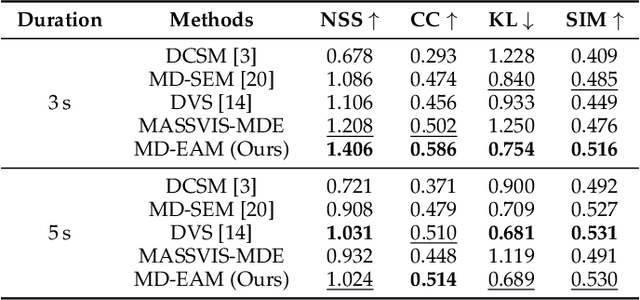
We propose Unified Model of Saliency and Scanpaths (UMSS) -- a model that learns to predict visual saliency and scanpaths (i.e. sequences of eye fixations) on information visualisations. Although scanpaths provide rich information about the importance of different visualisation elements during the visual exploration process, prior work has been limited to predicting aggregated attention statistics, such as visual saliency. We present in-depth analyses of gaze behaviour for different information visualisation elements (e.g. Title, Label, Data) on the popular MASSVIS dataset. We show that while, overall, gaze patterns are surprisingly consistent across visualisations and viewers, there are also structural differences in gaze dynamics for different elements. Informed by our analyses, UMSS first predicts multi-duration element-level saliency maps, then probabilistically samples scanpaths from them. Extensive experiments on MASSVIS show that our method consistently outperforms state-of-the-art methods with respect to several, widely used scanpath and saliency evaluation metrics. Our method achieves a relative improvement in sequence score of 11.5% for scanpath prediction, and a relative improvement in Pearson correlation coefficient of up to 23.6% for saliency prediction. These results are auspicious and point towards richer user models and simulations of visual attention on visualisations without the need for any eye tracking equipment.