 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAFT: Towards Out-of-Distribution Generalization in Fine-Tuning
Jul 03, 2024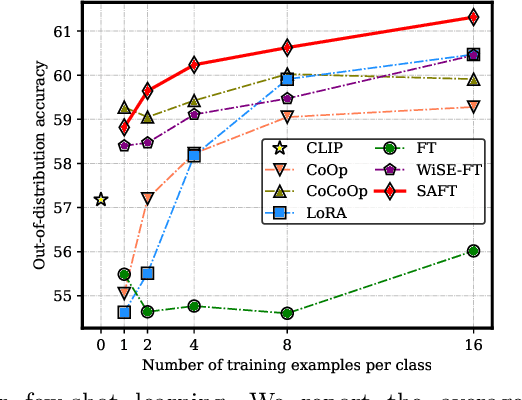
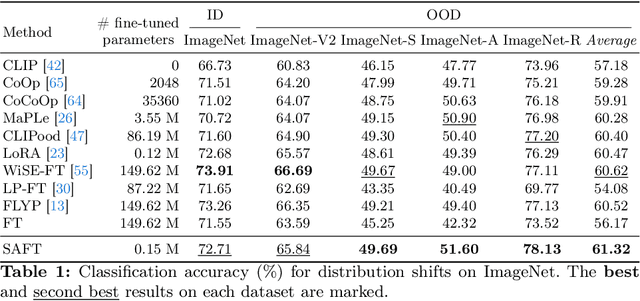
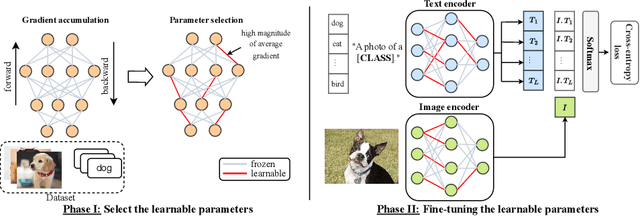
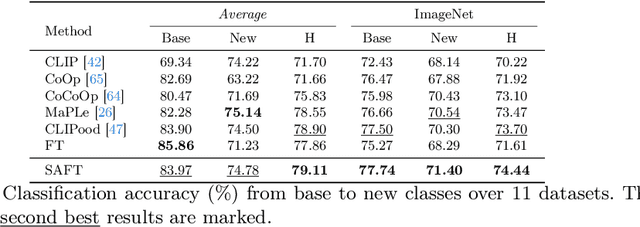
Handling distribution shifts from training data, known as out-of-distribution (OOD) generalization, poses a significant challenge in the field of machine learning. While a pre-trained vision-language model like CLIP has demonstrated remarkable zero-shot performance, further adaptation of the model to downstream tasks leads to undesirable degradation for OOD data. In this work, we introduce Sparse Adaptation for Fine-Tuning (SAFT), a method that prevents fine-tuning from forgetting the general knowledge in the pre-trained model. SAFT only updates a small subset of important parameters whose gradient magnitude is large, while keeping the other parameters frozen. SAFT is straightforward to implement and conceptually simple. Extensive experiments show that with only 0.1% of the model parameters, SAFT can significantly improve the performance of CLIP. It consistently outperforms baseline methods across several benchmarks. On the few-shot learning benchmark of ImageNet and its variants, SAFT gives a gain of 5.15% on average over the conventional fine-tuning method in OOD settings.
LSDAT: Low-Rank and Sparse Decomposition for Decision-based Adversarial Attack
Mar 22, 2021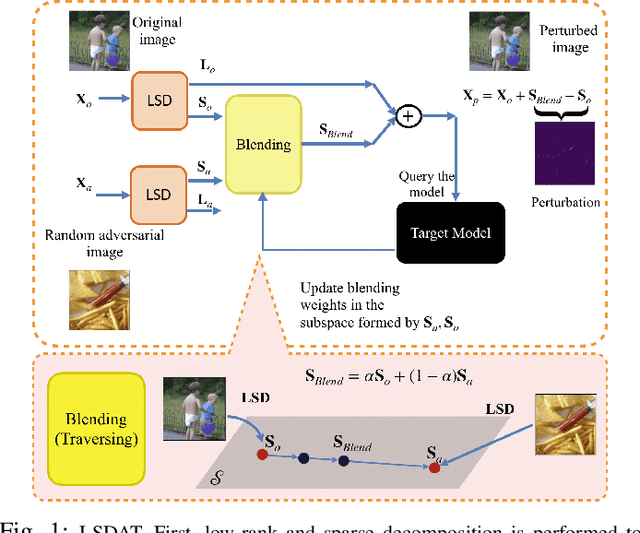


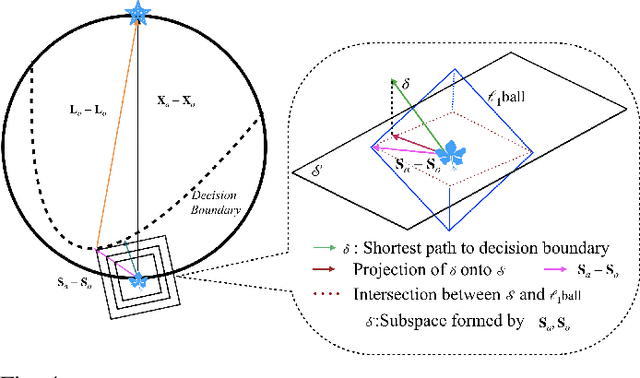
We propose LSDAT, an image-agnostic decision-based black-box attack that exploits low-rank and sparse decomposition (LSD) to dramatically reduce the number of queries and achieve superior fooling rates compared to the state-of-the-art decision-based methods under given imperceptibility constraints. LSDAT crafts perturbations in the low-dimensional subspace formed by the sparse component of the input sample and that of an adversarial sample to obtain query-efficiency. The specific perturbation of interest is obtained by traversing the path between the input and adversarial sparse components. It is set forth that the proposed sparse perturbation is the most aligned sparse perturbation with the shortest path from the input sample to the decision boundary for some initial adversarial sample (the best sparse approximation of shortest path, likely to fool the model). Theoretical analyses are provided to justify the functionality of LSDAT. Unlike other dimensionality reduction based techniques aimed at improving query efficiency (e.g, ones based on FFT), LSD works directly in the image pixel domain to guarantee that non-$\ell_2$ constraints, such as sparsity, are satisfied. LSD offers better control over the number of queries and provides computational efficiency as it performs sparse decomposition of the input and adversarial images only once to generate all queries. We demonstrate $\ell_0$, $\ell_2$ and $\ell_\infty$ bounded attacks with LSDAT to evince its efficiency compared to baseline decision-based attacks in diverse low-query budget scenarios as outlined in the experiments.
Odyssey: Creation, Analysis and Detection of Trojan Models
Jul 16, 2020
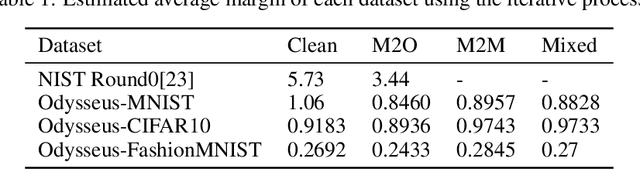


Along with the success of deep neural network (DNN) models in solving variousreal world problems, rise the threats to these models that aim to degrade theirintegrity. Trojan attack is one of the recent variant of data poisoning attacks thatinvolves manipulation or modification of the model to act balefully. This can occurwhen an attacker interferes with the training pipeline by inserting triggers into someof the training samples and trains the model to act maliciously only for samplesthat are stamped with trigger. Since the knowledge of such triggers is only privy to the attacker, detection of Trojan behaviour is a challenge task. Unlike any of the existing Trojan detectors, a robust detector should not rely on any assumption about Trojan attack. In this paper, we develop a detector based upon the analysis of intrinsic properties of DNN that could get affected by a Trojan attack. To have a comprehensive study, we propose, Odysseus, the largest Trojan dataset with over 3,000 trained DNN models, both clean and Trojan. It covers a large spectrum of attacks; generated by leveraging the versatility in designing a trigger and mapping (source to target class) type. Our findings reveal that Trojan attacks affect the classifier margin and shape of decision boundary around the manifold of the clean data. Combining these two factors leads to an efficient Trojan detector; operates irrespective of any knowledge of the Trojan attack; that sets the first baseline for this task with accuracy above 83%.
Subspace Capsule Network
Feb 07, 2020
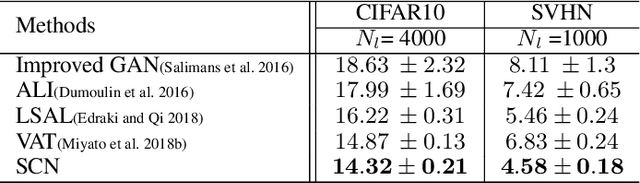


Convolutional neural networks (CNNs) have become a key asset to most of fields in AI. Despite their successful performance, CNNs suffer from a major drawback. They fail to capture the hierarchy of spatial relation among different parts of an entity. As a remedy to this problem, the idea of capsules was proposed by Hinton. In this paper, we propose the SubSpace Capsule Network (SCN) that exploits the idea of capsule networks to model possible variations in the appearance or implicitly defined properties of an entity through a group of capsule subspaces instead of simply grouping neurons to create capsules. A capsule is created by projecting an input feature vector from a lower layer onto the capsule subspace using a learnable transformation. This transformation finds the degree of alignment of the input with the properties modeled by the capsule subspace. We show that SCN is a general capsule network that can successfully be applied to both discriminative and generative models without incurring computational overhead compared to CNN during test time. Effectiveness of SCN is evaluated through a comprehensive set of experiments on supervised image classification, semi-supervised image classification and high-resolution image generation tasks using the generative adversarial network (GAN) framework. SCN significantly improves the performance of the baseline models in all 3 tasks.
CapProNet: Deep Feature Learning via Orthogonal Projections onto Capsule Subspaces
Oct 20, 2018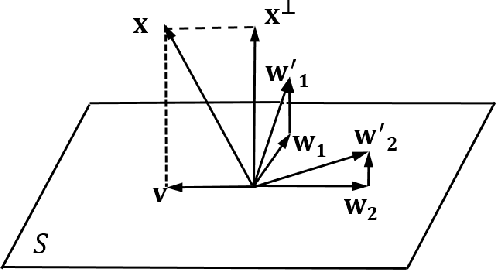
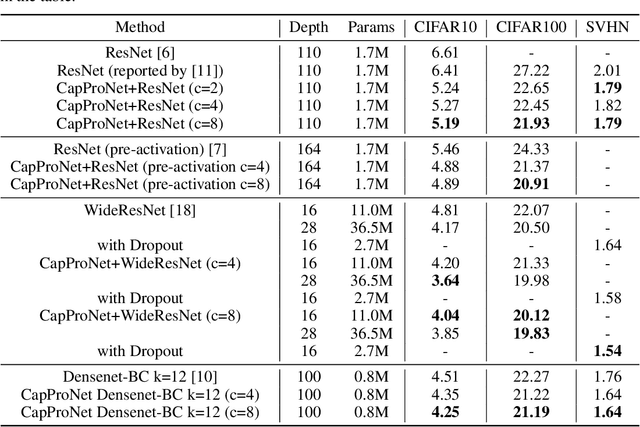

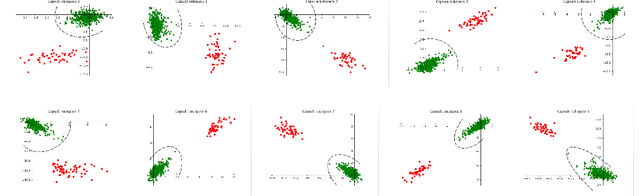
In this paper, we formalize the idea behind capsule nets of using a capsule vector rather than a neuron activation to predict the label of samples. To this end, we propose to learn a group of capsule subspaces onto which an input feature vector is projected. Then the lengths of resultant capsules are used to score the probability of belonging to different classes. We train such a Capsule Projection Network (CapProNet) by learning an orthogonal projection matrix for each capsule subspace, and show that each capsule subspace is updated until it contains input feature vectors corresponding to the associated class. We will also show that the capsule projection can be viewed as normalizing the multiple columns of the weight matrix simultaneously to form an orthogonal basis, which makes it more effective in incorporating novel components of input features to update capsule representations. In other words, the capsule projection can be viewed as a multi-dimensional weight normalization in capsule subspaces, where the conventional weight normalization is simply a special case of the capsule projection onto 1D lines. Only a small negligible computing overhead is incurred to train the network in low-dimensional capsule subspaces or through an alternative hyper-power iteration to estimate the normalization matrix. Experiment results on image datasets show the presented model can greatly improve the performance of the state-of-the-art ResNet backbones by $10-20\%$ and that of the Densenet by $5-7\%$ respectively at the same level of computing and memory expenses. The CapProNet establishes the competitive state-of-the-art performance for the family of capsule nets by significantly reducing test errors on the benchmark datasets.
Global versus Localized Generative Adversarial Nets
Mar 27, 2018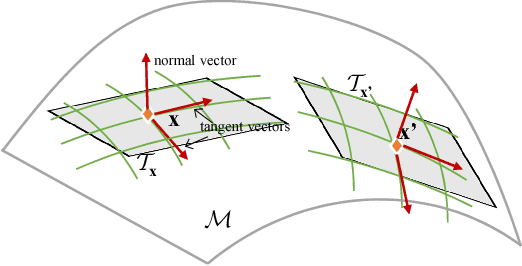
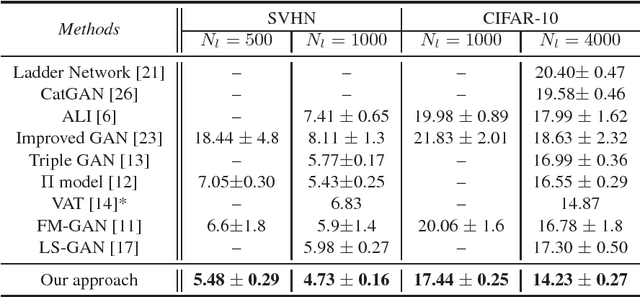


In this paper, we present a novel localized Generative Adversarial Net (GAN) to learn on the manifold of real data. Compared with the classic GAN that {\em globally} parameterizes a manifold, the Localized GAN (LGAN) uses local coordinate charts to parameterize distinct local geometry of how data points can transform at different locations on the manifold. Specifically, around each point there exists a {\em local} generator that can produce data following diverse patterns of transformations on the manifold. The locality nature of LGAN enables local generators to adapt to and directly access the local geometry without need to invert the generator in a global GAN. Furthermore, it can prevent the manifold from being locally collapsed to a dimensionally deficient tangent subspace by imposing an orthonormality prior between tangents. This provides a geometric approach to alleviating mode collapse at least locally on the manifold by imposing independence between data transformations in different tangent directions. We will also demonstrate the LGAN can be applied to train a robust classifier that prefers locally consistent classification decisions on the manifold, and the resultant regularizer is closely related with the Laplace-Beltrami operator. Our experiments show that the proposed LGANs can not only produce diverse image transformations, but also deliver superior classification performances.