 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHCC-3D: Hierarchical Compensatory Compression for 98% 3D Token Reduction in Vision-Language Models
Nov 13, 20253D understanding has drawn significant attention recently, leveraging Vision-Language Models (VLMs) to enable multi-modal reasoning between point cloud and text data. Current 3D-VLMs directly embed the 3D point clouds into 3D tokens, following large 2D-VLMs with powerful reasoning capabilities. However, this framework has a great computational cost limiting its application, where we identify that the bottleneck lies in processing all 3D tokens in the Large Language Model (LLM) part. This raises the question: how can we reduce the computational overhead introduced by 3D tokens while preserving the integrity of their essential information? To address this question, we introduce Hierarchical Compensatory Compression (HCC-3D) to efficiently compress 3D tokens while maintaining critical detail retention. Specifically, we first propose a global structure compression (GSC), in which we design global queries to compress all 3D tokens into a few key tokens while keeping overall structural information. Then, to compensate for the information loss in GSC, we further propose an adaptive detail mining (ADM) module that selectively recompresses salient but under-attended features through complementary scoring. Extensive experiments demonstrate that HCC-3D not only achieves extreme compression ratios (approximately 98%) compared to previous 3D-VLMs, but also achieves new state-of-the-art performance, showing the great improvements on both efficiency and performance.
RichControl: Structure- and Appearance-Rich Training-Free Spatial Control for Text-to-Image Generation
Jul 03, 2025Text-to-image (T2I) diffusion models have shown remarkable success in generating high-quality images from text prompts. Recent efforts extend these models to incorporate conditional images (e.g., depth or pose maps) for fine-grained spatial control. Among them, feature injection methods have emerged as a training-free alternative to traditional fine-tuning approaches. However, they often suffer from structural misalignment, condition leakage, and visual artifacts, especially when the condition image diverges significantly from natural RGB distributions. By revisiting existing methods, we identify a core limitation: the synchronous injection of condition features fails to account for the trade-off between domain alignment and structural preservation during denoising. Inspired by this observation, we propose a flexible feature injection framework that decouples the injection timestep from the denoising process. At its core is a structure-rich injection module, which enables the model to better adapt to the evolving interplay between alignment and structure preservation throughout the diffusion steps, resulting in more faithful structural generation. In addition, we introduce appearance-rich prompting and a restart refinement strategy to further enhance appearance control and visual quality. Together, these designs enable training-free generation that is both structure-rich and appearance-rich. Extensive experiments show that our approach achieves state-of-the-art performance across diverse zero-shot conditioning scenarios.
AVT: Unsupervised Learning of Transformation Equivariant Representations by Autoencoding Variational Transformations
Apr 01, 2019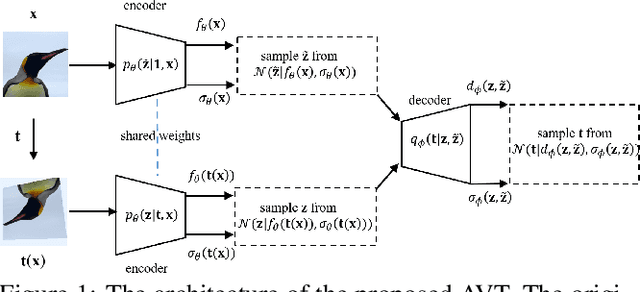
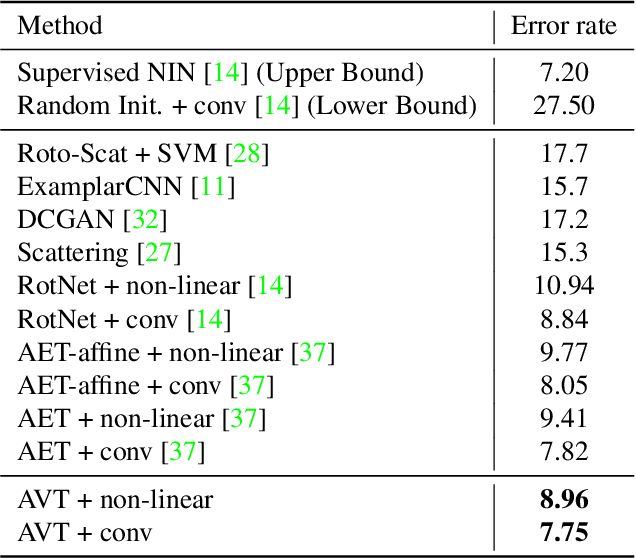
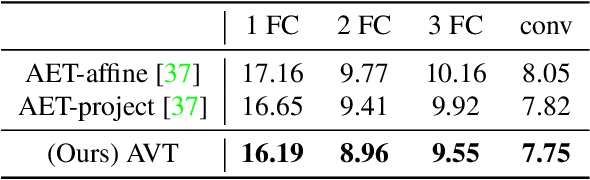
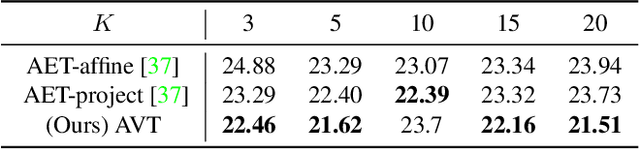
The learning of Transformation-Equivariant Representations (TERs), which is introduced by Hinton et al. \cite{hinton2011transforming}, has been considered as a principle to reveal visual structures under various transformations. It contains the celebrated Convolutional Neural Networks (CNNs) as a special case that only equivary to the translations. In contrast, we seek to train TERs for a generic class of transformations and train them in an {\em unsupervised} fashion. To this end, we present a novel principled method by Autoencoding Variational Transformations (AVT), compared with the conventional approach to autoencoding data. Formally, given transformed images, the AVT seeks to train the networks by maximizing the mutual information between the transformations and representations. This ensures the resultant TERs of individual images contain the {\em intrinsic} information about their visual structures that would equivary {\em extricably} under various transformations. Technically, we show that the resultant optimization problem can be efficiently solved by maximizing a variational lower-bound of the mutual information. This variational approach introduces a transformation decoder to approximate the intractable posterior of transformations, resulting in an autoencoding architecture with a pair of the representation encoder and the transformation decoder. Experiments demonstrate the proposed AVT model sets a new record for the performances on unsupervised tasks, greatly closing the performance gap to the supervised models.
AET vs. AED: Unsupervised Representation Learning by Auto-Encoding Transformations rather than Data
Jan 14, 2019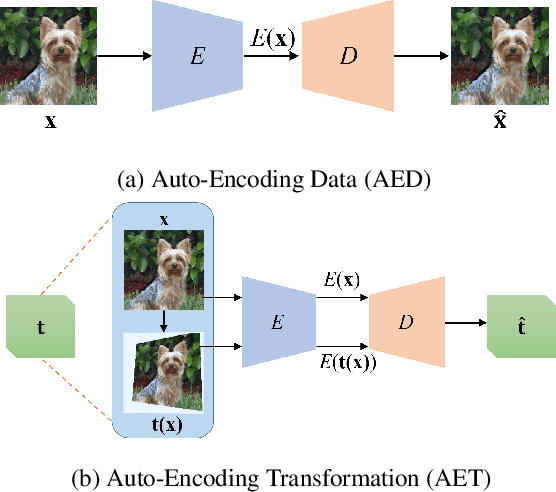
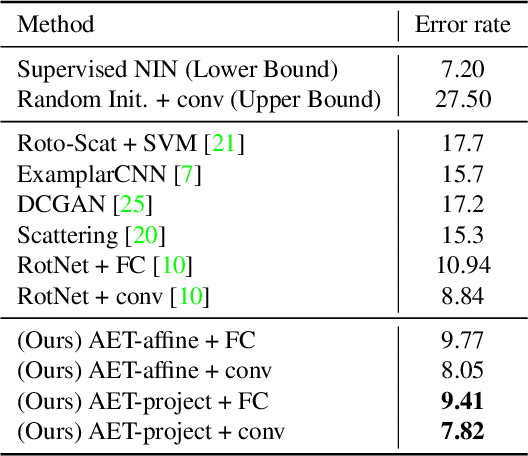
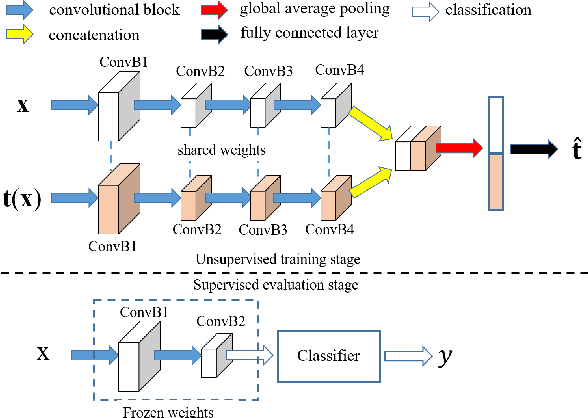

The success of deep neural networks often relies on a large amount of labeled examples, which can be difficult to obtain in many real scenarios. To address this challenge, unsupervised methods are strongly preferred for training neural networks without using any labeled data. In this paper, we present a novel paradigm of unsupervised representation learning by Auto-Encoding Transformation (AET) in contrast to the conventional Auto-Encoding Data (AED) approach. Given a randomly sampled transformation, AET seeks to predict it merely from the encoded features as accurately as possible at the output end. The idea is the following: as long as the unsupervised features successfully encode the essential information about the visual structures of original and transformed images, the transformation can be well predicted. We will show that this AET paradigm allows us to instantiate a large variety of transformations, from parameterized, to non-parameterized and GAN-induced ones. Our experiments show that AET greatly improves over existing unsupervised approaches, setting new state-of-the-art performances being greatly closer to the upper bounds by their fully supervised counterparts on CIFAR-10, ImageNet and Places datasets.
Gated Context Aggregation Network for Image Dehazing and Deraining
Nov 21, 2018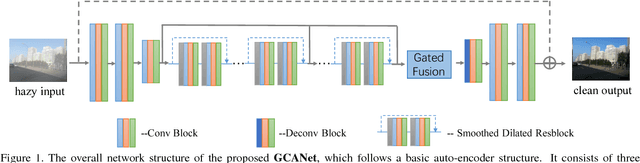

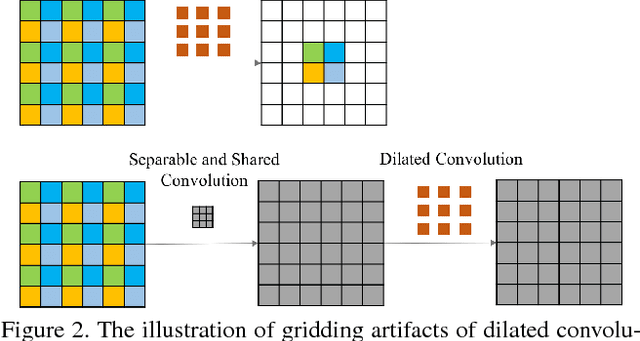

Image dehazing aims to recover the uncorrupted content from a hazy image. Instead of leveraging traditional low-level or handcrafted image priors as the restoration constraints, e.g., dark channels and increased contrast, we propose an end-to-end gated context aggregation network to directly restore the final haze-free image. In this network, we adopt the latest smoothed dilation technique to help remove the gridding artifacts caused by the widely-used dilated convolution with negligible extra parameters, and leverage a gated sub-network to fuse the features from different levels. Extensive experiments demonstrate that our method can surpass previous state-of-the-art methods by a large margin both quantitatively and qualitatively. In addition, to demonstrate the generality of the proposed method, we further apply it to the image deraining task, which also achieves the state-of-the-art performance.
CapProNet: Deep Feature Learning via Orthogonal Projections onto Capsule Subspaces
Oct 20, 2018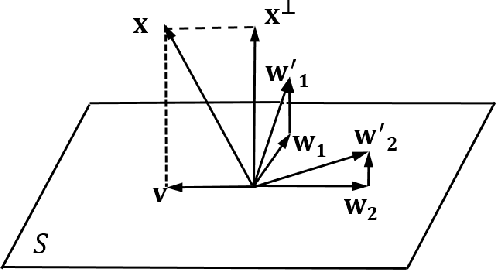
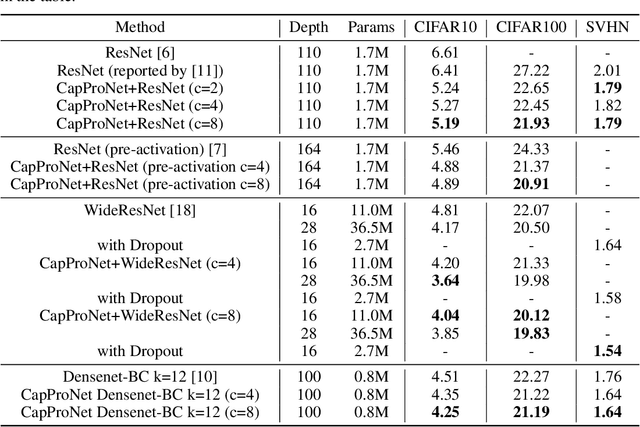

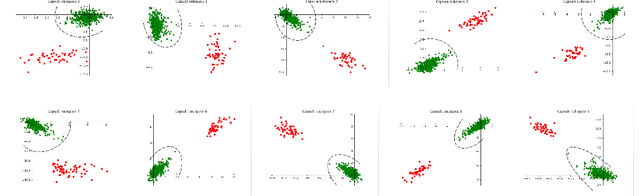
In this paper, we formalize the idea behind capsule nets of using a capsule vector rather than a neuron activation to predict the label of samples. To this end, we propose to learn a group of capsule subspaces onto which an input feature vector is projected. Then the lengths of resultant capsules are used to score the probability of belonging to different classes. We train such a Capsule Projection Network (CapProNet) by learning an orthogonal projection matrix for each capsule subspace, and show that each capsule subspace is updated until it contains input feature vectors corresponding to the associated class. We will also show that the capsule projection can be viewed as normalizing the multiple columns of the weight matrix simultaneously to form an orthogonal basis, which makes it more effective in incorporating novel components of input features to update capsule representations. In other words, the capsule projection can be viewed as a multi-dimensional weight normalization in capsule subspaces, where the conventional weight normalization is simply a special case of the capsule projection onto 1D lines. Only a small negligible computing overhead is incurred to train the network in low-dimensional capsule subspaces or through an alternative hyper-power iteration to estimate the normalization matrix. Experiment results on image datasets show the presented model can greatly improve the performance of the state-of-the-art ResNet backbones by $10-20\%$ and that of the Densenet by $5-7\%$ respectively at the same level of computing and memory expenses. The CapProNet establishes the competitive state-of-the-art performance for the family of capsule nets by significantly reducing test errors on the benchmark datasets.
Global versus Localized Generative Adversarial Nets
Mar 27, 2018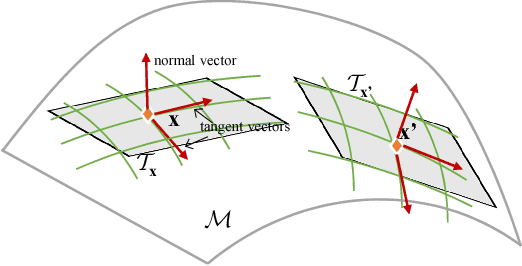
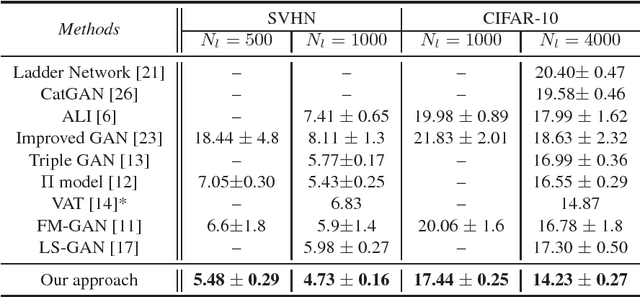


In this paper, we present a novel localized Generative Adversarial Net (GAN) to learn on the manifold of real data. Compared with the classic GAN that {\em globally} parameterizes a manifold, the Localized GAN (LGAN) uses local coordinate charts to parameterize distinct local geometry of how data points can transform at different locations on the manifold. Specifically, around each point there exists a {\em local} generator that can produce data following diverse patterns of transformations on the manifold. The locality nature of LGAN enables local generators to adapt to and directly access the local geometry without need to invert the generator in a global GAN. Furthermore, it can prevent the manifold from being locally collapsed to a dimensionally deficient tangent subspace by imposing an orthonormality prior between tangents. This provides a geometric approach to alleviating mode collapse at least locally on the manifold by imposing independence between data transformations in different tangent directions. We will also demonstrate the LGAN can be applied to train a robust classifier that prefers locally consistent classification decisions on the manifold, and the resultant regularizer is closely related with the Laplace-Beltrami operator. Our experiments show that the proposed LGANs can not only produce diverse image transformations, but also deliver superior classification performances.