 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT-FT: An Efficient Automated Feature Transformation Using GPT for Sequence Reconstruction and Performance Enhancement
Aug 28, 2025



Feature transformation plays a critical role in enhancing machine learning model performance by optimizing data representations. Recent state-of-the-art approaches address this task as a continuous embedding optimization problem, converting discrete search into a learnable process. Although effective, these methods often rely on sequential encoder-decoder structures that cause high computational costs and parameter requirements, limiting scalability and efficiency. To address these limitations, we propose a novel framework that accomplishes automated feature transformation through four steps: transformation records collection, embedding space construction with a revised Generative Pre-trained Transformer (GPT) model, gradient-ascent search, and autoregressive reconstruction. In our approach, the revised GPT model serves two primary functions: (a) feature transformation sequence reconstruction and (b) model performance estimation and enhancement for downstream tasks by constructing the embedding space. Such a multi-objective optimization framework reduces parameter size and accelerates transformation processes. Experimental results on benchmark datasets show that the proposed framework matches or exceeds baseline performance, with significant gains in computational efficiency. This work highlights the potential of transformer-based architectures for scalable, high-performance automated feature transformation.
DA-VPT: Semantic-Guided Visual Prompt Tuning for Vision Transformers
May 29, 2025Visual Prompt Tuning (VPT) has become a promising solution for Parameter-Efficient Fine-Tuning (PEFT) approach for Vision Transformer (ViT) models by partially fine-tuning learnable tokens while keeping most model parameters frozen. Recent research has explored modifying the connection structures of the prompts. However, the fundamental correlation and distribution between the prompts and image tokens remain unexplored. In this paper, we leverage metric learning techniques to investigate how the distribution of prompts affects fine-tuning performance. Specifically, we propose a novel framework, Distribution Aware Visual Prompt Tuning (DA-VPT), to guide the distributions of the prompts by learning the distance metric from their class-related semantic data. Our method demonstrates that the prompts can serve as an effective bridge to share semantic information between image patches and the class token. We extensively evaluated our approach on popular benchmarks in both recognition and segmentation tasks. The results demonstrate that our approach enables more effective and efficient fine-tuning of ViT models by leveraging semantic information to guide the learning of the prompts, leading to improved performance on various downstream vision tasks.
StyleRec: A Benchmark Dataset for Prompt Recovery in Writing Style Transformation
Apr 06, 2025



Prompt Recovery, reconstructing prompts from the outputs of large language models (LLMs), has grown in importance as LLMs become ubiquitous. Most users access LLMs through APIs without internal model weights, relying only on outputs and logits, which complicates recovery. This paper explores a unique prompt recovery task focused on reconstructing prompts for style transfer and rephrasing, rather than typical question-answering. We introduce a dataset created with LLM assistance, ensuring quality through multiple techniques, and test methods like zero-shot, few-shot, jailbreak, chain-of-thought, fine-tuning, and a novel canonical-prompt fallback for poor-performing cases. Our results show that one-shot and fine-tuning yield the best outcomes but highlight flaws in traditional sentence similarity metrics for evaluating prompt recovery. Contributions include (1) a benchmark dataset, (2) comprehensive experiments on prompt recovery strategies, and (3) identification of limitations in current evaluation metrics, all of which advance general prompt recovery research, where the structure of the input prompt is unrestricted.
REFORMER: A ChatGPT-Driven Data Synthesis Framework Elevating Text-to-SQL Models
Apr 06, 2025



The existing Text-to-SQL models suffer from a shortage of training data, inhibiting their ability to fully facilitate the applications of SQL queries in new domains. To address this challenge, various data synthesis techniques have been employed to generate more diverse and higher quality data. In this paper, we propose REFORMER, a framework that leverages ChatGPT's prowess without the need for additional training, to facilitate the synthesis of (question, SQL query) pairs tailored to new domains. Our data augmentation approach is based on a "retrieve-and-edit" method, where we generate new questions by filling masked question using explanation of SQL queries with the help of ChatGPT. Furthermore, we demonstrate that cycle consistency remains a valuable method of validation when applied appropriately. Our experimental results show that REFORMER consistently outperforms previous data augmentation methods. To further investigate the power of ChatGPT and create a general data augmentation method, we also generate the new data by paraphrasing the question in the dataset and by paraphrasing the description of a new SQL query that is generated by ChatGPT as well. Our results affirm that paraphrasing questions generated by ChatGPT help augment the original data.
Sigma: A dataset for text-to-code semantic parsing with statistical analysis
Apr 05, 2025In the domain of semantic parsing, significant progress has been achieved in Text-to-SQL and question-answering tasks, both of which focus on extracting information from data sources in their native formats. However, the inherent constraints of their formal meaning representations, such as SQL programming language or basic logical forms, hinder their ability to analyze data from various perspectives, such as conducting statistical analyses. To address this limitation and inspire research in this field, we design SIGMA, a new dataset for Text-to-Code semantic parsing with statistical analysis. SIGMA comprises 6000 questions with corresponding Python code labels, spanning across 160 databases. Half of the questions involve query types, which return information in its original format, while the remaining 50% are statistical analysis questions, which perform statistical operations on the data. The Python code labels in our dataset cover 4 types of query types and 40 types of statistical analysis patterns. We evaluated the SIGMA dataset using three different baseline models: LGESQL, SmBoP, and SLSQL. The experimental results show that the LGESQL model with ELECTRA outperforms all other models, achieving 83.37% structure accuracy. In terms of execution accuracy, the SmBoP model, when combined with GraPPa and T5, reaches 76.38%.
Knowledge Graph Reasoning with Self-supervised Reinforcement Learning
May 22, 2024



Reinforcement learning (RL) is an effective method of finding reasoning pathways in incomplete knowledge graphs (KGs). To overcome the challenges of a large action space, a self-supervised pre-training method is proposed to warm up the policy network before the RL training stage. To alleviate the distributional mismatch issue in general self-supervised RL (SSRL), in our supervised learning (SL) stage, the agent selects actions based on the policy network and learns from generated labels; this self-generation of labels is the intuition behind the name self-supervised. With this training framework, the information density of our SL objective is increased and the agent is prevented from getting stuck with the early rewarded paths. Our self-supervised RL (SSRL) method improves the performance of RL by pairing it with the wide coverage achieved by SL during pretraining, since the breadth of the SL objective makes it infeasible to train an agent with that alone. We show that our SSRL model meets or exceeds current state-of-the-art results on all Hits@k and mean reciprocal rank (MRR) metrics on four large benchmark KG datasets. This SSRL method can be used as a plug-in for any RL architecture for a KGR task. We adopt two RL architectures, i.e., MINERVA and MultiHopKG as our baseline RL models and experimentally show that our SSRL model consistently outperforms both baselines on all of these four KG reasoning tasks. Full code for the paper available at https://github.com/owenonline/Knowledge-Graph-Reasoning-with-Self-supervised-Reinforcement-Learning.
Ar-Spider: Text-to-SQL in Arabic
Feb 22, 2024In Natural Language Processing (NLP), one of the most important tasks is text-to-SQL semantic parsing, which focuses on enabling users to interact with the database in a more natural manner. In recent years, text-to-SQL has made significant progress, but most were English-centric. In this paper, we introduce Ar-Spider 1, the first Arabic cross-domain text-to-SQL dataset. Due to the unique nature of the language, two major challenges have been encountered, namely schema linguistic and SQL structural challenges. In order to handle these issues and conduct the experiments, we adopt two baseline models LGESQL [4] and S2SQL [12], both of which are tested with two cross-lingual models to alleviate the effects of schema linguistic and SQL structure linking challenges. The baselines demonstrate decent single-language performance on our Arabic text-to-SQL dataset, Ar-Spider, achieving 62.48% for S2SQL and 65.57% for LGESQL, only 8.79% below the highest results achieved by the baselines when trained in English dataset. To achieve better performance on Arabic text-to-SQL, we propose the context similarity relationship (CSR) approach, which results in a significant increase in the overall performance of about 1.52% for S2SQL and 1.06% for LGESQL and closes the gap between Arabic and English languages to 7.73%.
Learning Semantic Proxies from Visual Prompts for Parameter-Efficient Fine-Tuning in Deep Metric Learning
Feb 04, 2024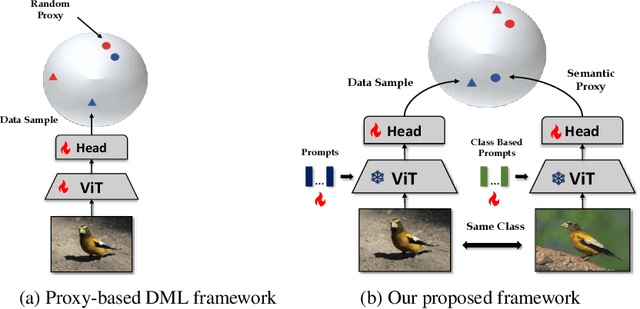
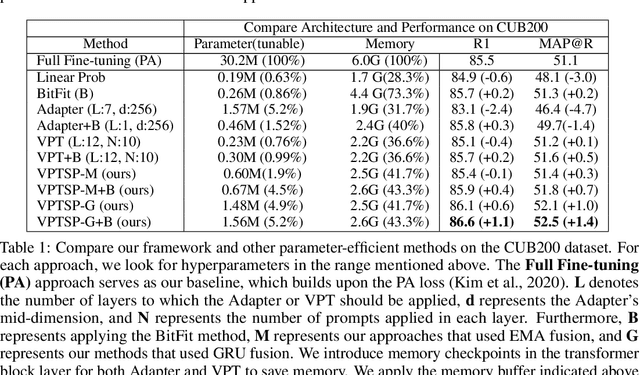
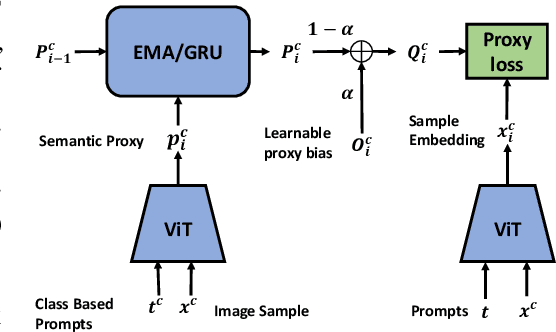
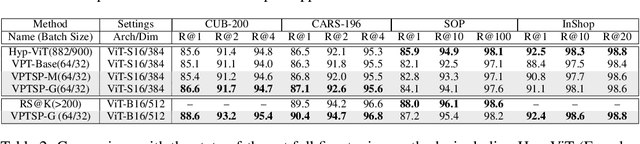
Deep Metric Learning (DML) has long attracted the attention of the machine learning community as a key objective. Existing solutions concentrate on fine-tuning the pre-trained models on conventional image datasets. As a result of the success of recent pre-trained models trained from larger-scale datasets, it is challenging to adapt the model to the DML tasks in the local data domain while retaining the previously gained knowledge. In this paper, we investigate parameter-efficient methods for fine-tuning the pre-trained model for DML tasks. In particular, we propose a novel and effective framework based on learning Visual Prompts (VPT) in the pre-trained Vision Transformers (ViT). Based on the conventional proxy-based DML paradigm, we augment the proxy by incorporating the semantic information from the input image and the ViT, in which we optimize the visual prompts for each class. We demonstrate that our new approximations with semantic information are superior to representative capabilities, thereby improving metric learning performance. We conduct extensive experiments to demonstrate that our proposed framework is effective and efficient by evaluating popular DML benchmarks. In particular, we demonstrate that our fine-tuning method achieves comparable or even better performance than recent state-of-the-art full fine-tuning works of DML while tuning only a small percentage of total parameters.
BA-LINS: A Frame-to-Frame Bundle Adjustment for LiDAR-Inertial Navigation
Jan 21, 2024



Bundle Adjustment (BA) has been proven to improve the accuracy of the LiDAR mapping. However, the BA method has not been properly employed in a dead-reckoning navigation system. In this paper, we present a frame-to-frame (F2F) BA for LiDAR-inertial navigation, named BA-LINS. Based on the direct F2F point-cloud association, the same-plane points are associated among the LiDAR keyframes. Hence, the plane-point BA measurement can be constructed using the same-plane points. The LiDAR BA measurements and the inertial measurement unit (IMU)-preintegration measurements are tightly integrated under the framework of factor graph optimization. An effective adaptive covariance estimation algorithm for LiDAR BA measurements is proposed to further improve the accuracy of BA-LINS. We conduct exhaustive real-world experiments on public and private datasets to examine the proposed BA-LINS. The results demonstrate that BA-LINS yields superior accuracy to state-of-the-art methods. Compared to the baseline system FF-LINS, the absolute translation accuracy and state-estimation efficiency of BA-LINS are improved by 29.5% and 28.7%, respectively, on the private dataset. Besides, the ablation experiment results exhibit that the proposed adaptive covariance estimation algorithm can notably improve the accuracy and robustness of BA-LINS.
Towards Improved Proxy-based Deep Metric Learning via Data-Augmented Domain Adaptation
Jan 01, 2024
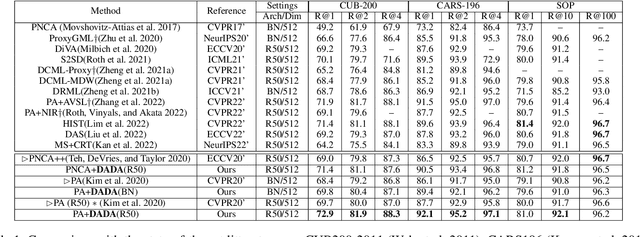


Deep Metric Learning (DML) plays an important role in modern computer vision research, where we learn a distance metric for a set of image representations. Recent DML techniques utilize the proxy to interact with the corresponding image samples in the embedding space. However, existing proxy-based DML methods focus on learning individual proxy-to-sample distance while the overall distribution of samples and proxies lacks attention. In this paper, we present a novel proxy-based DML framework that focuses on aligning the sample and proxy distributions to improve the efficiency of proxy-based DML losses. Specifically, we propose the Data-Augmented Domain Adaptation (DADA) method to adapt the domain gap between the group of samples and proxies. To the best of our knowledge, we are the first to leverage domain adaptation to boost the performance of proxy-based DML. We show that our method can be easily plugged into existing proxy-based DML losses. Our experiments on benchmarks, including the popular CUB-200-2011, CARS196, Stanford Online Products, and In-Shop Clothes Retrieval, show that our learning algorithm significantly improves the existing proxy losses and achieves superior results compared to the existing methods.