 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDA-VPT: Semantic-Guided Visual Prompt Tuning for Vision Transformers
May 29, 2025Visual Prompt Tuning (VPT) has become a promising solution for Parameter-Efficient Fine-Tuning (PEFT) approach for Vision Transformer (ViT) models by partially fine-tuning learnable tokens while keeping most model parameters frozen. Recent research has explored modifying the connection structures of the prompts. However, the fundamental correlation and distribution between the prompts and image tokens remain unexplored. In this paper, we leverage metric learning techniques to investigate how the distribution of prompts affects fine-tuning performance. Specifically, we propose a novel framework, Distribution Aware Visual Prompt Tuning (DA-VPT), to guide the distributions of the prompts by learning the distance metric from their class-related semantic data. Our method demonstrates that the prompts can serve as an effective bridge to share semantic information between image patches and the class token. We extensively evaluated our approach on popular benchmarks in both recognition and segmentation tasks. The results demonstrate that our approach enables more effective and efficient fine-tuning of ViT models by leveraging semantic information to guide the learning of the prompts, leading to improved performance on various downstream vision tasks.
Learning Semantic Proxies from Visual Prompts for Parameter-Efficient Fine-Tuning in Deep Metric Learning
Feb 04, 2024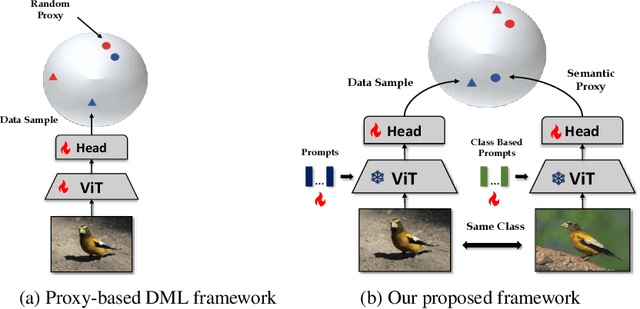
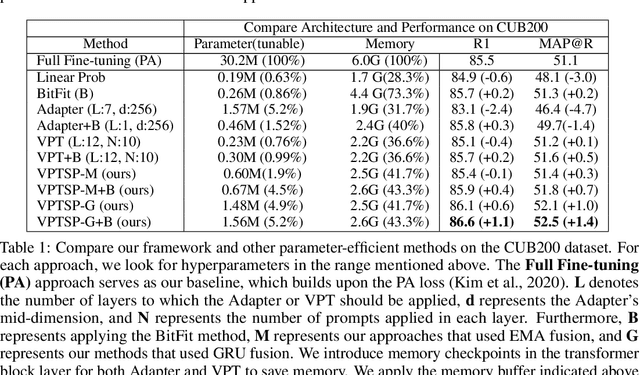
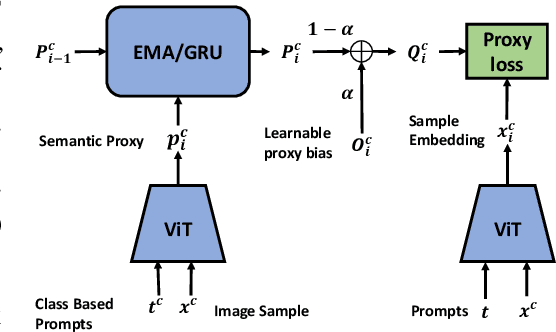
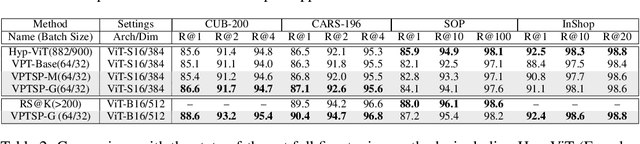
Deep Metric Learning (DML) has long attracted the attention of the machine learning community as a key objective. Existing solutions concentrate on fine-tuning the pre-trained models on conventional image datasets. As a result of the success of recent pre-trained models trained from larger-scale datasets, it is challenging to adapt the model to the DML tasks in the local data domain while retaining the previously gained knowledge. In this paper, we investigate parameter-efficient methods for fine-tuning the pre-trained model for DML tasks. In particular, we propose a novel and effective framework based on learning Visual Prompts (VPT) in the pre-trained Vision Transformers (ViT). Based on the conventional proxy-based DML paradigm, we augment the proxy by incorporating the semantic information from the input image and the ViT, in which we optimize the visual prompts for each class. We demonstrate that our new approximations with semantic information are superior to representative capabilities, thereby improving metric learning performance. We conduct extensive experiments to demonstrate that our proposed framework is effective and efficient by evaluating popular DML benchmarks. In particular, we demonstrate that our fine-tuning method achieves comparable or even better performance than recent state-of-the-art full fine-tuning works of DML while tuning only a small percentage of total parameters.
Towards Improved Proxy-based Deep Metric Learning via Data-Augmented Domain Adaptation
Jan 01, 2024
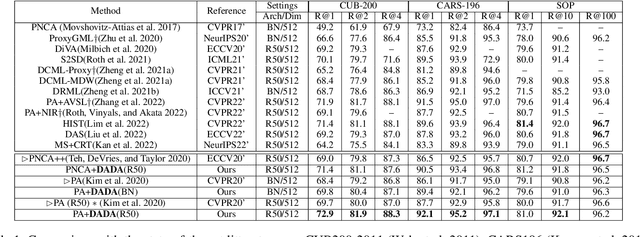


Deep Metric Learning (DML) plays an important role in modern computer vision research, where we learn a distance metric for a set of image representations. Recent DML techniques utilize the proxy to interact with the corresponding image samples in the embedding space. However, existing proxy-based DML methods focus on learning individual proxy-to-sample distance while the overall distribution of samples and proxies lacks attention. In this paper, we present a novel proxy-based DML framework that focuses on aligning the sample and proxy distributions to improve the efficiency of proxy-based DML losses. Specifically, we propose the Data-Augmented Domain Adaptation (DADA) method to adapt the domain gap between the group of samples and proxies. To the best of our knowledge, we are the first to leverage domain adaptation to boost the performance of proxy-based DML. We show that our method can be easily plugged into existing proxy-based DML losses. Our experiments on benchmarks, including the popular CUB-200-2011, CARS196, Stanford Online Products, and In-Shop Clothes Retrieval, show that our learning algorithm significantly improves the existing proxy losses and achieves superior results compared to the existing methods.
Neural-Base Music Generation for Intelligence Duplication
Oct 20, 2023There are two aspects of machine learning and artificial intelligence: (1) interpreting information, and (2) inventing new useful information. Much advance has been made for (1) with a focus on pattern recognition techniques (e.g., interpreting visual data). This paper focuses on (2) with intelligent duplication (ID) for invention. We explore the possibility of learning a specific individual's creative reasoning in order to leverage the learned expertise and talent to invent new information. More specifically, we employ a deep learning system to learn from the great composer Beethoven and capture his composition ability in a hash-based knowledge base. This new form of knowledge base provides a reasoning facility to drive the music composition through a novel music generation method.
Beyond the Deep Metric Learning: Enhance the Cross-Modal Matching with Adversarial Discriminative Domain Regularization
Oct 27, 2020
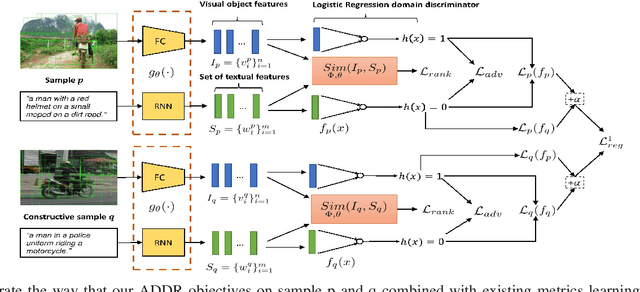
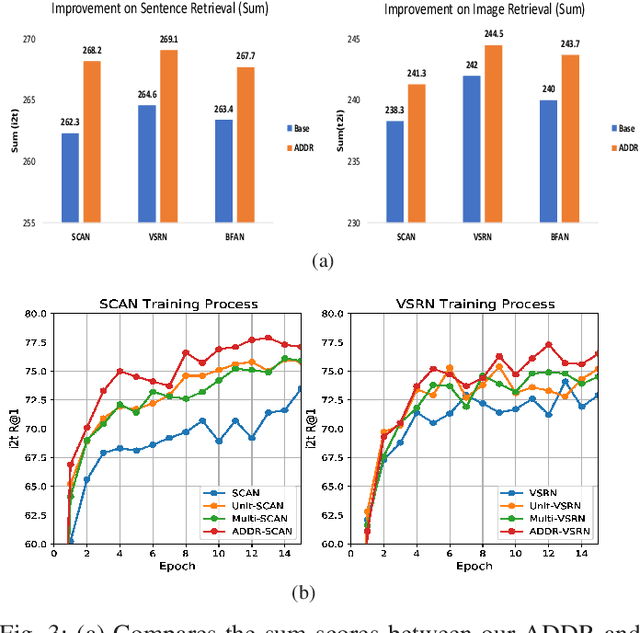

Matching information across image and text modalities is a fundamental challenge for many applications that involve both vision and natural language processing. The objective is to find efficient similarity metrics to compare the similarity between visual and textual information. Existing approaches mainly match the local visual objects and the sentence words in a shared space with attention mechanisms. The matching performance is still limited because the similarity computation is based on simple comparisons of the matching features, ignoring the characteristics of their distribution in the data. In this paper, we address this limitation with an efficient learning objective that considers the discriminative feature distributions between the visual objects and sentence words. Specifically, we propose a novel Adversarial Discriminative Domain Regularization (ADDR) learning framework, beyond the paradigm metric learning objective, to construct a set of discriminative data domains within each image-text pairs. Our approach can generally improve the learning efficiency and the performance of existing metrics learning frameworks by regulating the distribution of the hidden space between the matching pairs. The experimental results show that this new approach significantly improves the overall performance of several popular cross-modal matching techniques (SCAN, VSRN, BFAN) on the MS-COCO and Flickr30K benchmarks.