 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePA-LVIO: Real-Time LiDAR-Visual-Inertial Odometry and Mapping with Pose-Only Bundle Adjustment
Mar 17, 2026Real-time LiDAR-visual-inertial odometry and mapping is crucial for navigation and planning tasks in intelligent transportation systems. This study presents a pose-only bundle adjustment (PA) LiDAR-visual-inertial odometry (LVIO), named PA-LVIO, to meet the urgent need for real-time navigation and mapping. The proposed PA framework for LiDAR and visual measurements is highly accurate and efficient, and it can derive reliable frame-to-frame constraints within multiple frames. A marginalization-free and frame-to-map (F2M) LiDAR measurement model is integrated into the state estimator to eliminate odometry drifts. Meanwhile, an IMU-centric online spatial-temporal calibration is employed to obtain a pixel-wise LiDAR-camera alignment. With accurate estimated odometry and extrinsics, a high-quality and RGB-rendered point-cloud map can be built. Comprehensive experiments are conducted on both public and private datasets collected by wheeled robot, unmanned aerial vehicle (UAV), and handheld devices with 28 sequences and more than 50 km trajectories. Sufficient results demonstrate that the proposed PA-LVIO yields superior or comparable performance to state-of-the-art LVIO methods, in terms of the odometry accuracy and mapping quality. Besides, PA-LVIO can run in real-time on both the desktop PC and the onboard ARM computer.
FlashLabs Chroma 1.0: A Real-Time End-to-End Spoken Dialogue Model with Personalized Voice Cloning
Jan 16, 2026Recent end-to-end spoken dialogue systems leverage speech tokenizers and neural audio codecs to enable LLMs to operate directly on discrete speech representations. However, these models often exhibit limited speaker identity preservation, hindering personalized voice interaction. In this work, we present Chroma 1.0, the first open-source, real-time, end-to-end spoken dialogue model that achieves both low-latency interaction and high-fidelity personalized voice cloning. Chroma achieves sub-second end-to-end latency through an interleaved text-audio token schedule (1:2) that supports streaming generation, while maintaining high-quality personalized voice synthesis across multi-turn conversations. Our experimental results demonstrate that Chroma achieves a 10.96% relative improvement in speaker similarity over the human baseline, with a Real-Time Factor (RTF) of 0.43, while maintaining strong reasoning and dialogue capabilities. Our code and models are publicly available at https://github.com/FlashLabs-AI-Corp/FlashLabs-Chroma and https://huggingface.co/FlashLabs/Chroma-4B .
MR-ULINS: A Tightly-Coupled UWB-LiDAR-Inertial Estimator with Multi-Epoch Outlier Rejection
Aug 11, 2024



The LiDAR-inertial odometry (LIO) and the ultra-wideband (UWB) have been integrated together to achieve driftless positioning in global navigation satellite system (GNSS)-denied environments. However, the UWB may be affected by systematic range errors (such as the clock drift and the antenna phase center offset) and non-line-of-sight (NLOS) signals, resulting in reduced robustness. In this study, we propose a UWB-LiDAR-inertial estimator (MR-ULINS) that tightly integrates the UWB range, LiDAR frame-to-frame, and IMU measurements within the multi-state constraint Kalman filter (MSCKF) framework. The systematic range errors are precisely modeled to be estimated and compensated online. Besides, we propose a multi-epoch outlier rejection algorithm for UWB NLOS by utilizing the relative accuracy of the LIO. Specifically, the relative trajectory of the LIO is employed to verify the consistency of all range measurements within the sliding window. Extensive experiment results demonstrate that MR-ULINS achieves a positioning accuracy of around 0.1 m in complex indoor environments with severe NLOS interference. Ablation experiments show that the online estimation and multi-epoch outlier rejection can effectively improve the positioning accuracy. Besides, MR-ULINS maintains high accuracy and robustness in LiDAR-degenerated scenes and UWB-challenging conditions with spare base stations.
MSC-LIO: An MSCKF-Based LiDAR-Inertial Odometry with Same-Plane-Point Tracking
Jul 10, 2024
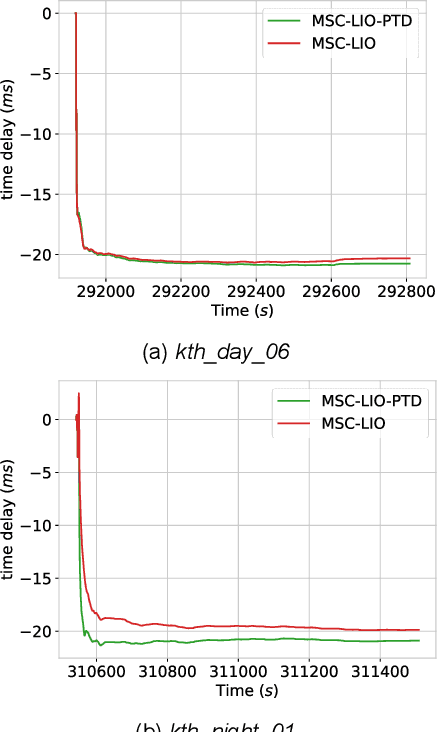

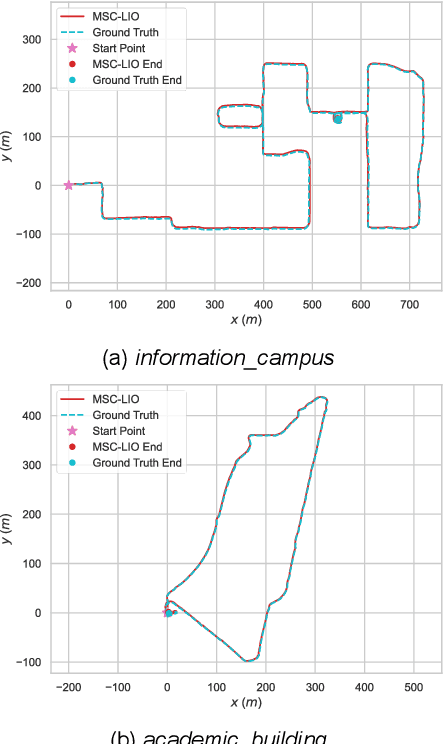
The multi-state constraint Kalman filter (MSCKF) has been proven to be more efficient than graph optimization for visual-based odometry while with similar accuracy. However, it has not yet been properly considered and studied for LiDAR-based odometry. In this paper, we propose a novel tightly coupled LiDAR-inertial odometry based on the MSCKF framework, named MSC-LIO. An efficient LiDAR same-plane-point (LSPP) tracking method, without explicit feature extraction, is present for frame-to-frame data associations. The tracked LSPPs are employed to build an LSPP measurement model, which constructs a multi-state constraint. Besides, we propose an effective point-velocity-based LiDAR-IMU time-delay (LITD) estimation method, which is derived from the proposed LSPP tracking method. Extensive experiments were conducted on both public and private datasets. The results demonstrate that the proposed MSC-LIO yields higher accuracy and efficiency than the state-of-the-art methods. The ablation experiment results indicate that the data-association efficiency is improved by nearly 3 times using the LSPP tracking method. Besides, the proposed LITD estimation method can effectively and accurately estimate the LITD.
Boosting Large-scale Parallel Training Efficiency with C4: A Communication-Driven Approach
Jun 07, 2024

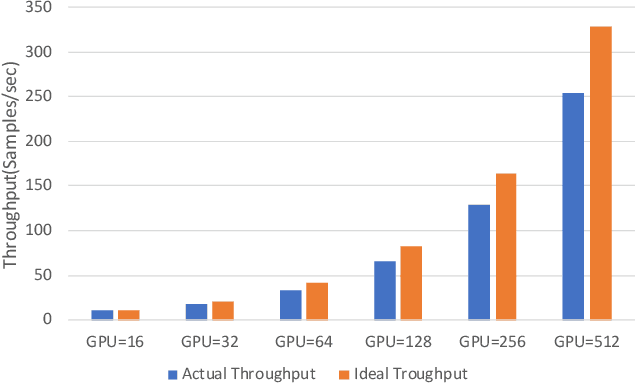

The emergence of Large Language Models (LLMs) has necessitated the adoption of parallel training techniques, involving the deployment of thousands of GPUs to train a single model. Unfortunately, we have found that the efficiency of current parallel training is often suboptimal, largely due to the following two main issues. Firstly, hardware failures are inevitable, leading to interruptions in the training tasks. The inability to quickly identify the faulty components results in a substantial waste of GPU resources. Secondly, since GPUs must wait for parameter synchronization to complete before proceeding to the next round of computation, network congestions can greatly increase the waiting time for GPUs. To address these challenges, this paper introduces a communication-driven solution, namely the C4. The key insights of C4 are two folds. First, in parallel training, collective communication exhibits periodic and homogeneous characteristics, so any anomalies are certainly due to some form of hardware malfunction. By leveraging this feature, C4 can rapidly identify the faulty components, swiftly isolate the anomaly, and restart the task, thereby avoiding resource wastage caused by delays in anomaly detection. Second, the predictable communication model of collective communication, involving few large flows, allows C4 to efficiently execute traffic planning, substantially reducing network congestion. C4 has been extensively implemented across our production systems, cutting error-induced overhead by roughly 30% and enhancing runtime performance by about 15% for certain applications with moderate communication costs.
SE-LIO: Semantics-enhanced Solid-State-LiDAR-Inertial Odometry for Tree-rich Environments
Dec 04, 2023



In this letter, we propose a semantics-enhanced solid-state-LiDAR-inertial odometry (SE-LIO) in tree-rich environments. Multiple LiDAR frames are first merged and compensated with the inertial navigation system (INS) to increase the point-cloud coverage, thus improving the accuracy of semantic segmentation. The unstructured point clouds, such as tree leaves and dynamic objects, are then removed with the semantic information. Furthermore, the pole-like point clouds, primarily tree trunks, are modeled as cylinders to improve positioning accuracy. An adaptive piecewise cylinder-fitting method is proposed to accommodate environments with a high prevalence of curved tree trunks. Finally, the iterated error-state Kalman filter (IESKF) is employed for state estimation. Point-to-cylinder and point-to-plane constraints are tightly coupled with the prior constraints provided by the INS to obtain the maximum a posteriori estimation. Targeted experiments are conducted in complex campus and park environments to evaluate the performance of SE-LIO. The proposed methods, including removing the unstructured point clouds and the adaptive cylinder fitting, yield improved accuracy. Specifically, the positioning accuracy of the proposed SE-LIO is improved by 43.1% compared to the plane-based LIO.
PICASSO: Unleashing the Potential of GPU-centric Training for Wide-and-deep Recommender Systems
Apr 17, 2022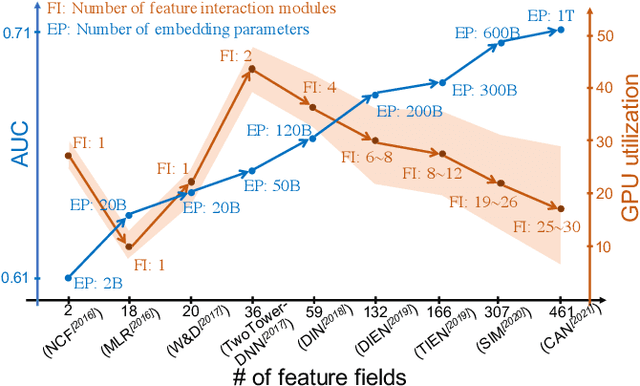

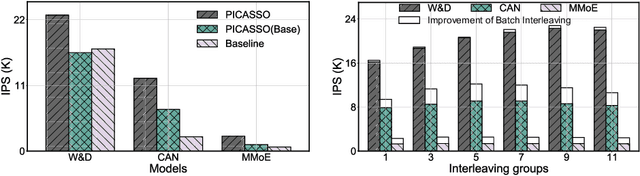
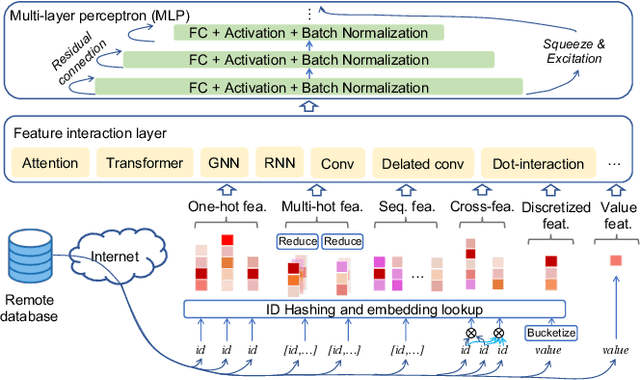
The development of personalized recommendation has significantly improved the accuracy of information matching and the revenue of e-commerce platforms. Recently, it has 2 trends: 1) recommender systems must be trained timely to cope with ever-growing new products and ever-changing user interests from online marketing and social network; 2) SOTA recommendation models introduce DNN modules to improve prediction accuracy. Traditional CPU-based recommender systems cannot meet these two trends, and GPU- centric training has become a trending approach. However, we observe that GPU devices in training recommender systems are underutilized, and they cannot attain an expected throughput improvement as what it has achieved in CV and NLP areas. This issue can be explained by two characteristics of these recommendation models: First, they contain up to a thousand input feature fields, introducing fragmentary and memory-intensive operations; Second, the multiple constituent feature interaction submodules introduce substantial small-sized compute kernels. To remove this roadblock to the development of recommender systems, we propose a novel framework named PICASSO to accelerate the training of recommendation models on commodity hardware. Specifically, we conduct a systematic analysis to reveal the bottlenecks encountered in training recommendation models. We leverage the model structure and data distribution to unleash the potential of hardware through our packing, interleaving, and caching optimization. Experiments show that PICASSO increases the hardware utilization by an order of magnitude on the basis of SOTA baselines and brings up to 6x throughput improvement for a variety of industrial recommendation models. Using the same hardware budget in production, PICASSO on average shortens the walltime of daily training tasks by 7 hours, significantly reducing the delay of continuous delivery.