 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimplicial Embeddings in Self-Supervised Learning and Downstream Classification
Paper and Code
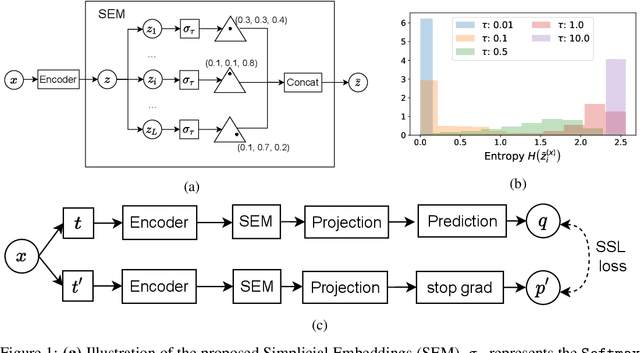

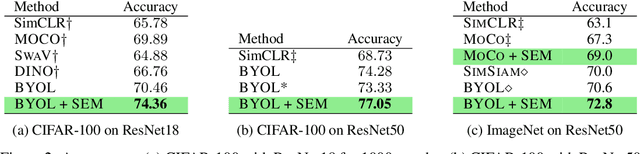
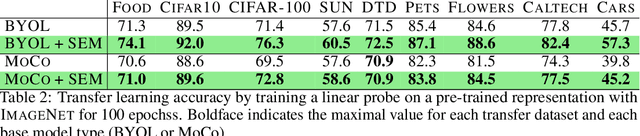
We introduce Simplicial Embeddings (SEMs) as a way to constrain the encoded representations of a self-supervised model to $L$ simplices of $V$ dimensions each using a Softmax operation. This procedure imposes a structure on the representations that reduce their expressivity for training downstream classifiers, which helps them generalize better. Specifically, we show that the temperature $\tau$ of the Softmax operation controls for the SEM representation's expressivity, allowing us to derive a tighter downstream classifier generalization bound than that for classifiers using unnormalized representations. We empirically demonstrate that SEMs considerably improve generalization on natural image datasets such as CIFAR-100 and ImageNet. Finally, we also present evidence of the emergence of semantically relevant features in SEMs, a pattern that is absent from baseline self-supervised models.