 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGEAR: Geometry-Aware Rényi Information
Paper and Code
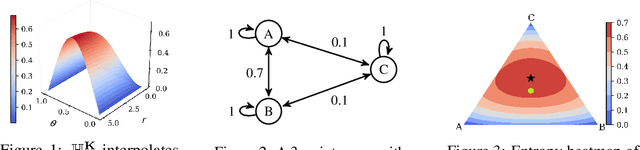


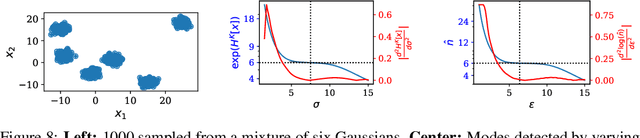
Shannon's seminal theory of information has been of paramount importance in the development of modern machine learning techniques. However, standard information measures deal with probability distributions over an alphabet considered as a mere set of symbols and disregard further geometric structure, which might be available in the form of a metric or similarity function. We advocate the use of a notion of entropy that reflects not only the relative abundances of symbols but also the similarities between them, which was originally introduced in theoretical ecology to study the diversity of biological communities. Echoing this idea, we propose a criterion for comparing two probability distributions (possibly degenerate and with non-overlapping supports) that takes into account the geometry of the space in which the distributions are defined. Our proposal exhibits performance on par with state-of-the-art methods based on entropy-regularized optimal transport, but enjoys a closed-form expression and thus a lower computational cost. We demonstrate the versatility of our proposal via experiments on a broad range of domains: computing image barycenters, approximating densities with a collection of (super-) samples; summarizing texts; assessing mode coverage; as well as training generative models.