 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Learning of Control Primitives: Skill Discovery via Reset-Games
Paper and Code
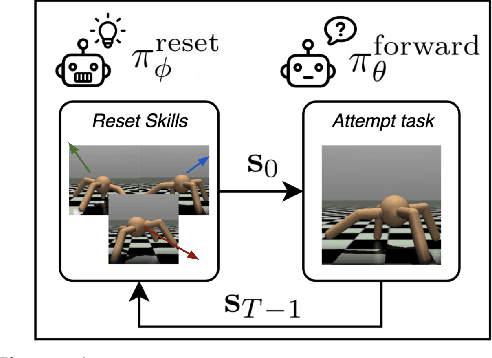
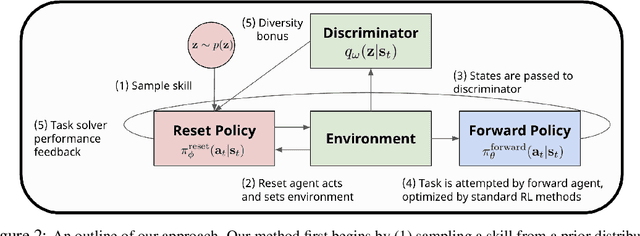

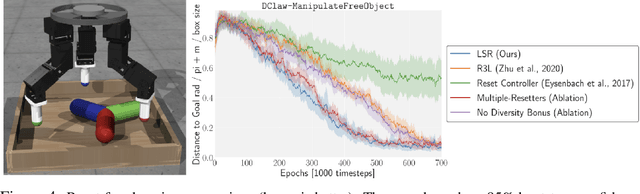
Reinforcement learning has the potential to automate the acquisition of behavior in complex settings, but in order for it to be successfully deployed, a number of practical challenges must be addressed. First, in real world settings, when an agent attempts a task and fails, the environment must somehow "reset" so that the agent can attempt the task again. While easy in simulation, this could require considerable human effort in the real world, especially if the number of trials is very large. Second, real world learning often involves complex, temporally extended behavior that is often difficult to acquire with random exploration. While these two problems may at first appear unrelated, in this work, we show how a single method can allow an agent to acquire skills with minimal supervision while removing the need for resets. We do this by exploiting the insight that the need to "reset" an agent to a broad set of initial states for a learning task provides a natural setting to learn a diverse set of "reset-skills". We propose a general-sum game formulation that balances the objectives of resetting and learning skills, and demonstrate that this approach improves performance on reset-free tasks, and additionally show that the skills we obtain can be used to significantly accelerate downstream learning.