 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Agentic Reasoning Through Self-Regulated Simulative Planning
May 21, 2026How should an agent decide when and how to plan? A dominant approach builds agents as reactive policies with adaptive computation (e.g., chain-of-thought), trained end-to-end expecting planning to emerge implicitly. Without control over the presence, structure, or horizon of planning, these systems dramatically increase reasoning length, yielding inefficient token use without reliable accuracy gains. We argue efficient agentic reasoning benefits from decomposing decision-making into three systems: simulative reasoning (System II) grounding deliberation in future-state prediction via a world model; self-regulation (System III) deciding when and how deeply to plan via a learned configurator; and reactive execution (System I) handling fine-grained action. Simulative reasoning provides unified planning across diverse tasks without per-domain engineering, while self-regulation ensures the planner is invoked only when needed. To test this, we develop SR$^2$AM (Self-Regulated Simulative Reasoning Agentic LLM), realizing both as distinct stages within an LLM's chain-of-thought, with the LLM as world model. We explore two instantiations: recording decisions from a prompted multi-module system (v0.1) and reconstructing structured plans from traces of pretrained reasoning LLMs (v1.0), trained via supervised then reinforcement learning (RL). Across math, science, tabular analysis, and web information seeking, v0.1-8B and v1.0-30B achieve Pass@1 competitive with 120-355B and 685B-1T parameter systems respectively, while v1.0-30B uses 25.8-95.3% fewer reasoning tokens than comparable agentic LLMs. RL increases average planning horizon by 22.8% while planning frequency grows only 2.0%, showing it learns to plan further ahead rather than more often. More broadly, learned self-regulation instantiates a principle we expect to extend beyond planning to how agents govern their own learning and adaptation.
IsoCompute Playbook: Optimally Scaling Sampling Compute for LLM RL
Mar 12, 2026While scaling laws guide compute allocation for LLM pre-training, analogous prescriptions for reinforcement learning (RL) post-training of large language models (LLMs) remain poorly understood. We study the compute-optimal allocation of sampling compute for on-policy RL methods in LLMs, framing scaling as a compute-constrained optimization over three resources: parallel rollouts per problem, number of problems per batch, and number of update steps. We find that the compute-optimal number of parallel rollouts per problem increases predictably with compute budget and then saturates. This trend holds across both easy and hard problems, though driven by different mechanisms: solution sharpening on easy problems and coverage expansion on hard problems. We further show that increasing the number of parallel rollouts mitigates interference across problems, while the number of problems per batch primarily affects training stability and can be chosen within a broad range. Validated across base models and data distributions, our results recast RL scaling laws as prescriptive allocation rules and provide practical guidance for compute-efficient LLM RL post-training.
K2-Think: A Parameter-Efficient Reasoning System
Sep 09, 2025K2-Think is a reasoning system that achieves state-of-the-art performance with a 32B parameter model, matching or surpassing much larger models like GPT-OSS 120B and DeepSeek v3.1. Built on the Qwen2.5 base model, our system shows that smaller models can compete at the highest levels by combining advanced post-training and test-time computation techniques. The approach is based on six key technical pillars: Long Chain-of-thought Supervised Finetuning, Reinforcement Learning with Verifiable Rewards (RLVR), Agentic planning prior to reasoning, Test-time Scaling, Speculative Decoding, and Inference-optimized Hardware, all using publicly available open-source datasets. K2-Think excels in mathematical reasoning, achieving state-of-the-art scores on public benchmarks for open-source models, while also performing strongly in other areas such as Code and Science. Our results confirm that a more parameter-efficient model like K2-Think 32B can compete with state-of-the-art systems through an integrated post-training recipe that includes long chain-of-thought training and strategic inference-time enhancements, making open-source reasoning systems more accessible and affordable. K2-Think is freely available at k2think.ai, offering best-in-class inference speeds of over 2,000 tokens per second per request via the Cerebras Wafer-Scale Engine.
SoftQE: Learned Representations of Queries Expanded by LLMs
Feb 20, 2024



We investigate the integration of Large Language Models (LLMs) into query encoders to improve dense retrieval without increasing latency and cost, by circumventing the dependency on LLMs at inference time. SoftQE incorporates knowledge from LLMs by mapping embeddings of input queries to those of the LLM-expanded queries. While improvements over various strong baselines on in-domain MS-MARCO metrics are marginal, SoftQE improves performance by 2.83 absolute percentage points on average on five out-of-domain BEIR tasks.
Accelerating Gradient-based Meta Learner
Oct 27, 2021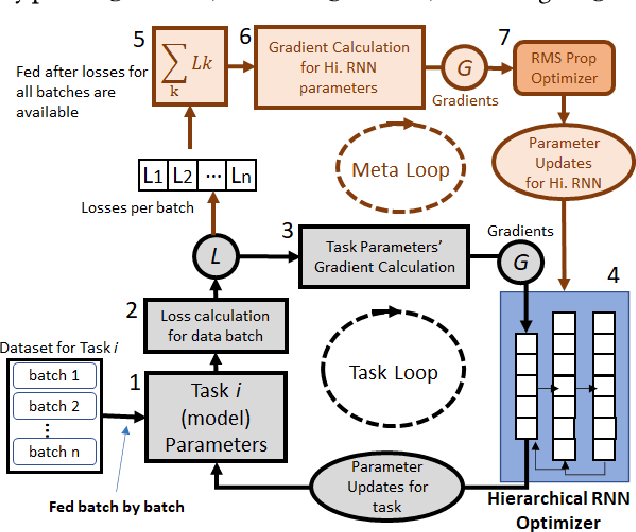

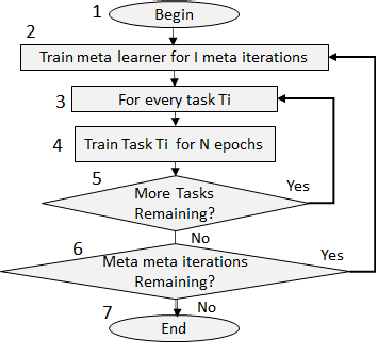
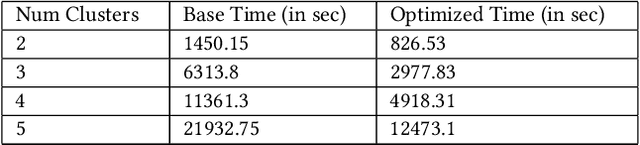
Meta Learning has been in focus in recent years due to the meta-learner model's ability to adapt well and generalize to new tasks, thus, reducing both the time and data requirements for learning. However, a major drawback of meta learner is that, to reach to a state from where learning new tasks becomes feasible with less data, it requires a large number of iterations and a lot of time. We address this issue by proposing various acceleration techniques to speed up meta learning algorithms such as MAML (Model Agnostic Meta Learning). We present 3.73X acceleration on a well known RNN optimizer based meta learner proposed in literature [11]. We introduce a novel method of training tasks in clusters, which not only accelerates the meta learning process but also improves model accuracy performance. Keywords: Meta learning, RNN optimizer, AGI, Performance optimization
CBIR using Pre-Trained Neural Networks
Oct 27, 2021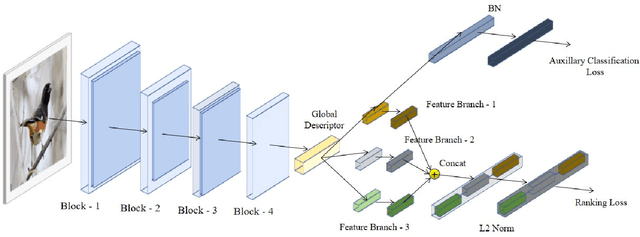

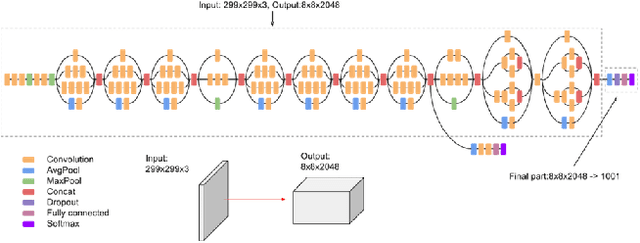
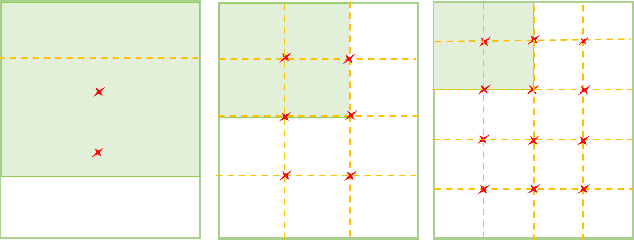
Much of the recent research work in image retrieval, has been focused around using Neural Networks as the core component. Many of the papers in other domain have shown that training multiple models, and then combining their outcomes, provide good results. This is since, a single Neural Network model, may not extract sufficient information from the input. In this paper, we aim to follow a different approach. Instead of the using a single model, we use a pretrained Inception V3 model, and extract activation of its last fully connected layer, which forms a low dimensional representation of the image. This feature matrix, is then divided into branches and separate feature extraction is done for each branch, to obtain multiple features flattened into a vector. Such individual vectors are then combined, to get a single combined feature. We make use of CUB200-2011 Dataset, which comprises of 200 birds classes to train the model on. We achieved a training accuracy of 99.46% and validation accuracy of 84.56% for the same. On further use of 3 branched global descriptors, we improve the validation accuracy to 88.89%. For this, we made use of MS-RMAC feature extraction method.