 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint2Pose: Occlusion-Recovering 6D Pose Tracking and 3D Reconstruction for Multiple Unknown Objects Via 2D Point Trackers
Apr 12, 2026We present Point2Pose, a model-free method for causal 6D pose tracking of multiple rigid objects from monocular RGB-D video. Initialized only from sparse image points on the objects to be tracked, our approach tracks multiple unseen objects without requiring object CAD models or category priors. Point2Pose leverages a 2D point tracker to obtain long-range correspondences, enabling instant recovery after complete occlusion. Simultaneously, the system incrementally reconstructs an online Truncated Signed Distance Function (TSDF) representation of the tracked targets. Alongside the method, we introduce a new multi-object tracking dataset comprising both simulation and real-world sequences, with motion-capture ground truth for evaluation. Experiments show that Point2Pose achieves performance comparable to the state-of-the-art methods on a severe-occlusion benchmark, while additionally supporting multi-object tracking and recovery from complete occlusion, capabilities that are not supported by previous model-free tracking approaches.
Equivariant Neural Networks for General Linear Symmetries on Lie Algebras
Oct 27, 2025Encoding symmetries is a powerful inductive bias for improving the generalization of deep neural networks. However, most existing equivariant models are limited to simple symmetries like rotations, failing to address the broader class of general linear transformations, GL(n), that appear in many scientific domains. We introduce Reductive Lie Neurons (ReLNs), a novel neural network architecture exactly equivariant to these general linear symmetries. ReLNs are designed to operate directly on a wide range of structured inputs, including general n-by-n matrices. ReLNs introduce a novel adjoint-invariant bilinear layer to achieve stable equivariance for both Lie-algebraic features and matrix-valued inputs, without requiring redesign for each subgroup. This architecture overcomes the limitations of prior equivariant networks that only apply to compact groups or simple vector data. We validate ReLNs' versatility across a spectrum of tasks: they outperform existing methods on algebraic benchmarks with sl(3) and sp(4) symmetries and achieve competitive results on a Lorentz-equivariant particle physics task. In 3D drone state estimation with geometric uncertainty, ReLNs jointly process velocities and covariances, yielding significant improvements in trajectory accuracy. ReLNs provide a practical and general framework for learning with broad linear group symmetries on Lie algebras and matrix-valued data. Project page: https://reductive-lie-neuron.github.io/
High-Bandwidth Tactile-Reactive Control for Grasp Adjustment
Sep 19, 2025Vision-only grasping systems are fundamentally constrained by calibration errors, sensor noise, and grasp pose prediction inaccuracies, leading to unavoidable contact uncertainty in the final stage of grasping. High-bandwidth tactile feedback, when paired with a well-designed tactile-reactive controller, can significantly improve robustness in the presence of perception errors. This paper contributes to controller design by proposing a purely tactile-feedback grasp-adjustment algorithm. The proposed controller requires neither prior knowledge of the object's geometry nor an accurate grasp pose, and is capable of refining a grasp even when starting from a crude, imprecise initial configuration and uncertain contact points. Through simulation studies and real-world experiments on a 15-DoF arm-hand system (featuring an 8-DoF hand) equipped with fingertip tactile sensors operating at 200 Hz, we demonstrate that our tactile-reactive grasping framework effectively improves grasp stability.
Riemannian Direct Trajectory Optimization of Rigid Bodies on Matrix Lie Groups
May 05, 2025



Designing dynamically feasible trajectories for rigid bodies is a fundamental problem in robotics. Although direct trajectory optimization is widely applied to solve this problem, inappropriate parameterizations of rigid body dynamics often result in slow convergence and violations of the intrinsic topological structure of the rotation group. This paper introduces a Riemannian optimization framework for direct trajectory optimization of rigid bodies. We first use the Lie Group Variational Integrator to formulate the discrete rigid body dynamics on matrix Lie groups. We then derive the closed-form first- and second-order Riemannian derivatives of the dynamics. Finally, this work applies a line-search Riemannian Interior Point Method (RIPM) to perform trajectory optimization with general nonlinear constraints. As the optimization is performed on matrix Lie groups, it is correct-by-construction to respect the topological structure of the rotation group and be free of singularities. The paper demonstrates that both the derivative evaluations and Newton steps required to solve the RIPM exhibit linear complexity with respect to the planning horizon and system degrees of freedom. Simulation results illustrate that the proposed method is faster than conventional methods by an order of magnitude in challenging robotics tasks.
Debiasing 6-DOF IMU via Hierarchical Learning of Continuous Bias Dynamics
Apr 13, 2025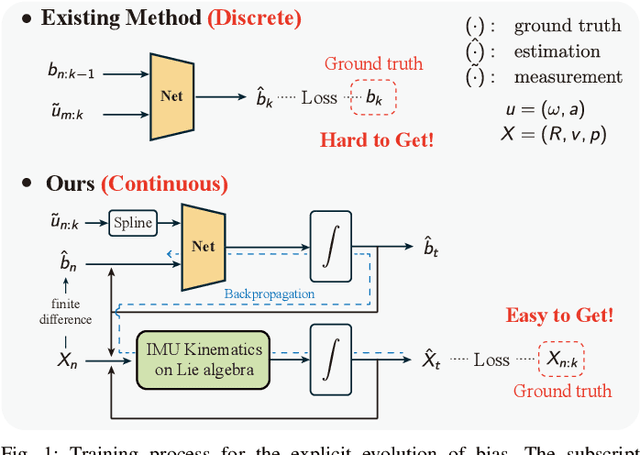
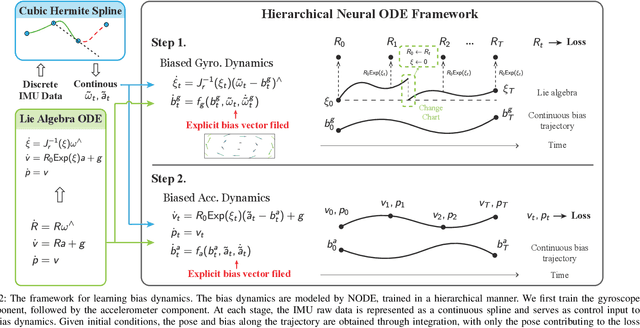
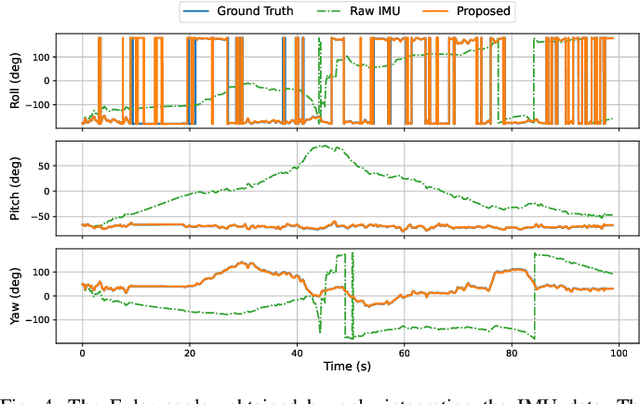
This paper develops a deep learning approach to the online debiasing of IMU gyroscopes and accelerometers. Most existing methods rely on implicitly learning a bias term to compensate for raw IMU data. Explicit bias learning has recently shown its potential as a more interpretable and motion-independent alternative. However, it remains underexplored and faces challenges, particularly the need for ground truth bias data, which is rarely available. To address this, we propose a neural ordinary differential equation (NODE) framework that explicitly models continuous bias dynamics, requiring only pose ground truth, often available in datasets. This is achieved by extending the canonical NODE framework to the matrix Lie group for IMU kinematics with a hierarchical training strategy. The validation on two public datasets and one real-world experiment demonstrates significant accuracy improvements in IMU measurements, reducing errors in both pure IMU integration and visual-inertial odometry.
Dynamic-SUPERB Phase-2: A Collaboratively Expanding Benchmark for Measuring the Capabilities of Spoken Language Models with 180 Tasks
Nov 08, 2024



Multimodal foundation models, such as Gemini and ChatGPT, have revolutionized human-machine interactions by seamlessly integrating various forms of data. Developing a universal spoken language model that comprehends a wide range of natural language instructions is critical for bridging communication gaps and facilitating more intuitive interactions. However, the absence of a comprehensive evaluation benchmark poses a significant challenge. We present Dynamic-SUPERB Phase-2, an open and evolving benchmark for the comprehensive evaluation of instruction-based universal speech models. Building upon the first generation, this second version incorporates 125 new tasks contributed collaboratively by the global research community, expanding the benchmark to a total of 180 tasks, making it the largest benchmark for speech and audio evaluation. While the first generation of Dynamic-SUPERB was limited to classification tasks, Dynamic-SUPERB Phase-2 broadens its evaluation capabilities by introducing a wide array of novel and diverse tasks, including regression and sequence generation, across speech, music, and environmental audio. Evaluation results indicate that none of the models performed well universally. SALMONN-13B excelled in English ASR, while WavLLM demonstrated high accuracy in emotion recognition, but current models still require further innovations to handle a broader range of tasks. We will soon open-source all task data and the evaluation pipeline.
Tensegrity Robot Proprioceptive State Estimation with Geometric Constraints
Oct 31, 2024



Tensegrity robots, characterized by a synergistic assembly of rigid rods and elastic cables, form robust structures that are resistant to impacts. However, this design introduces complexities in kinematics and dynamics, complicating control and state estimation. This work presents a novel proprioceptive state estimator for tensegrity robots. The estimator initially uses the geometric constraints of 3-bar prism tensegrity structures, combined with IMU and motor encoder measurements, to reconstruct the robot's shape and orientation. It then employs a contact-aided invariant extended Kalman filter with forward kinematics to estimate the global position and orientation of the tensegrity robot. The state estimator's accuracy is assessed against ground truth data in both simulated environments and real-world tensegrity robot applications. It achieves an average drift percentage of 4.2%, comparable to the state estimation performance of traditional rigid robots. This state estimator advances the state of the art in tensegrity robot state estimation and has the potential to run in real-time using onboard sensors, paving the way for full autonomy of tensegrity robots in unstructured environments.
Legged Robot State Estimation within Non-inertial Environments
Mar 24, 2024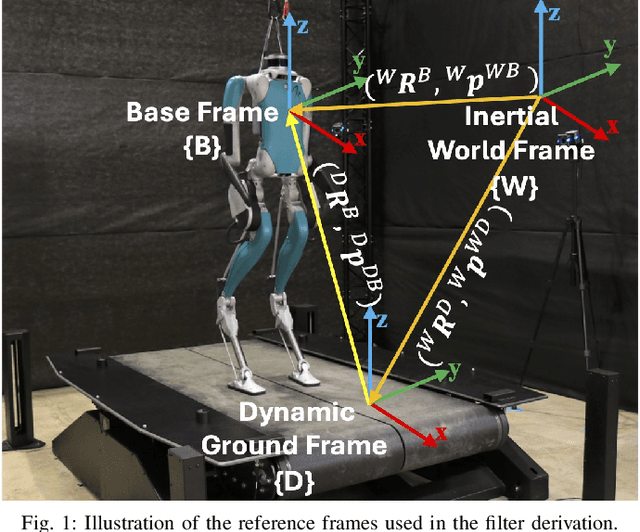

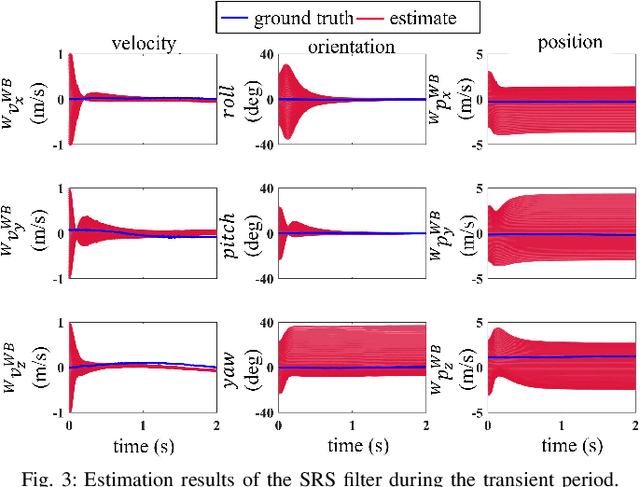
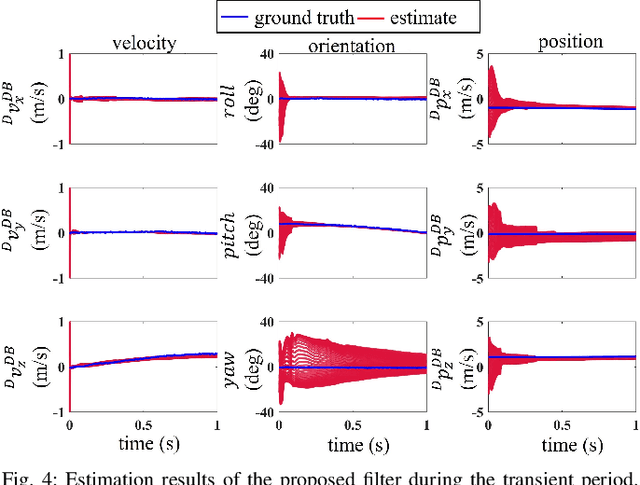
This paper investigates the robot state estimation problem within a non-inertial environment. The proposed state estimation approach relaxes the common assumption of static ground in the system modeling. The process and measurement models explicitly treat the movement of the non-inertial environments without requiring knowledge of its motion in the inertial frame or relying on GPS or sensing environmental landmarks. Further, the proposed state estimator is formulated as an invariant extended Kalman filter (InEKF) with the deterministic part of its process model obeying the group-affine property, leading to log-linear error dynamics. The observability analysis of the filter confirms that the robot's pose (i.e., position and orientation) and velocity relative to the non-inertial environment are observable. Hardware experiments on a humanoid robot moving on a rotating and translating treadmill demonstrate the high convergence rate and accuracy of the proposed InEKF even under significant treadmill pitch sway, as well as large estimation errors.
Proprioceptive Invariant Robot State Estimation
Nov 07, 2023



This paper reports on developing a real-time invariant proprioceptive robot state estimation framework called DRIFT. A didactic introduction to invariant Kalman filtering is provided to make this cutting-edge symmetry-preserving approach accessible to a broader range of robotics applications. Furthermore, this work dives into the development of a proprioceptive state estimation framework for dead reckoning that only consumes data from an onboard inertial measurement unit and kinematics of the robot, with two optional modules, a contact estimator and a gyro filter for low-cost robots, enabling a significant capability on a variety of robotics platforms to track the robot's state over long trajectories in the absence of perceptual data. Extensive real-world experiments using a legged robot, an indoor wheeled robot, a field robot, and a full-size vehicle, as well as simulation results with a marine robot, are provided to understand the limits of DRIFT.
Lie Neurons: Adjoint-Equivariant Neural Networks for Semisimple Lie Algebras
Oct 06, 2023



This paper proposes an adjoint-equivariant neural network that takes Lie algebra data as input. Various types of equivariant neural networks have been proposed in the literature, which treat the input data as elements in a vector space carrying certain types of transformations. In comparison, we aim to process inputs that are transformations between vector spaces. The change of basis on transformation is described by conjugations, inducing the adjoint-equivariance relationship that our model is designed to capture. Leveraging the invariance property of the Killing form, the proposed network is a general framework that works for arbitrary semisimple Lie algebras. Our network possesses a simple structure that can be viewed as a Lie algebraic generalization of a multi-layer perceptron (MLP). This work extends the application of equivariant feature learning. As an example, we showcase its value in homography modeling using sl(3) Lie algebra.