 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePicasso: Holistic Scene Reconstruction with Physics-Constrained Sampling
Feb 08, 2026In the presence of occlusions and measurement noise, geometrically accurate scene reconstructions -- which fit the sensor data -- can still be physically incorrect. For instance, when estimating the poses and shapes of objects in the scene and importing the resulting estimates into a simulator, small errors might translate to implausible configurations including object interpenetration or unstable equilibrium. This makes it difficult to predict the dynamic behavior of the scene using a digital twin, an important step in simulation-based planning and control of contact-rich behaviors. In this paper, we posit that object pose and shape estimation requires reasoning holistically over the scene (instead of reasoning about each object in isolation), accounting for object interactions and physical plausibility. Towards this goal, our first contribution is Picasso, a physics-constrained reconstruction pipeline that builds multi-object scene reconstructions by considering geometry, non-penetration, and physics. Picasso relies on a fast rejection sampling method that reasons over multi-object interactions, leveraging an inferred object contact graph to guide samples. Second, we propose the Picasso dataset, a collection of 10 contact-rich real-world scenes with ground truth annotations, as well as a metric to quantify physical plausibility, which we open-source as part of our benchmark. Finally, we provide an extensive evaluation of Picasso on our newly introduced dataset and on the YCB-V dataset, and show it largely outperforms the state of the art while providing reconstructions that are both physically plausible and more aligned with human intuition.
Box Pose and Shape Estimation and Domain Adaptation for Large-Scale Warehouse Automation
Jul 01, 2025
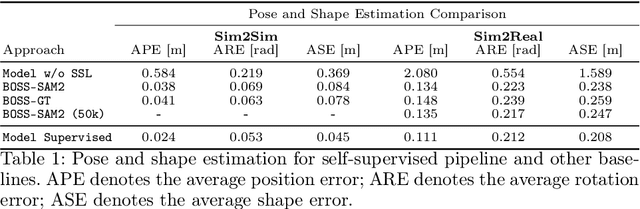
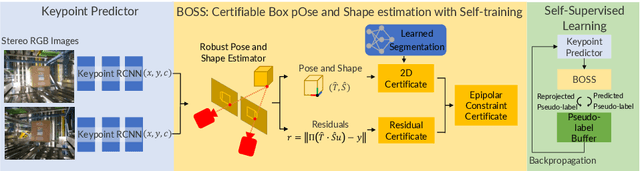
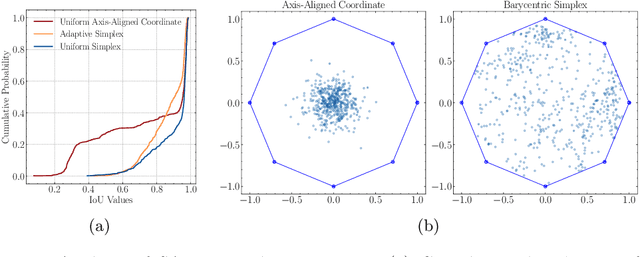
Modern warehouse automation systems rely on fleets of intelligent robots that generate vast amounts of data -- most of which remains unannotated. This paper develops a self-supervised domain adaptation pipeline that leverages real-world, unlabeled data to improve perception models without requiring manual annotations. Our work focuses specifically on estimating the pose and shape of boxes and presents a correct-and-certify pipeline for self-supervised box pose and shape estimation. We extensively evaluate our approach across a range of simulated and real industrial settings, including adaptation to a large-scale real-world dataset of 50,000 images. The self-supervised model significantly outperforms models trained solely in simulation and shows substantial improvements over a zero-shot 3D bounding box estimation baseline.
APISR: Anime Production Inspired Real-World Anime Super-Resolution
Mar 03, 2024



While real-world anime super-resolution (SR) has gained increasing attention in the SR community, existing methods still adopt techniques from the photorealistic domain. In this paper, we analyze the anime production workflow and rethink how to use characteristics of it for the sake of the real-world anime SR. First, we argue that video networks and datasets are not necessary for anime SR due to the repetition use of hand-drawing frames. Instead, we propose an anime image collection pipeline by choosing the least compressed and the most informative frames from the video sources. Based on this pipeline, we introduce the Anime Production-oriented Image (API) dataset. In addition, we identify two anime-specific challenges of distorted and faint hand-drawn lines and unwanted color artifacts. We address the first issue by introducing a prediction-oriented compression module in the image degradation model and a pseudo-ground truth preparation with enhanced hand-drawn lines. In addition, we introduce the balanced twin perceptual loss combining both anime and photorealistic high-level features to mitigate unwanted color artifacts and increase visual clarity. We evaluate our method through extensive experiments on the public benchmark, showing our method outperforms state-of-the-art approaches by a large margin.
SIM-Sync: From Certifiably Optimal Synchronization over the 3D Similarity Group to Scene Reconstruction with Learned Depth
Sep 11, 2023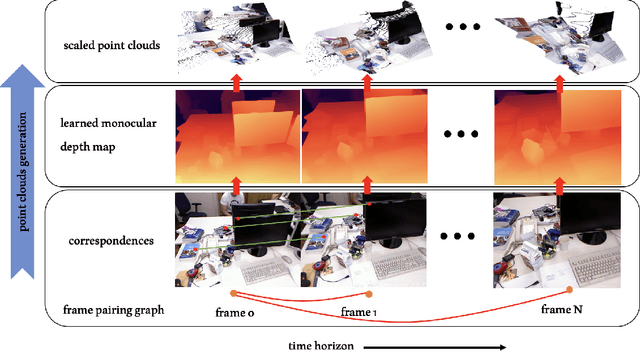

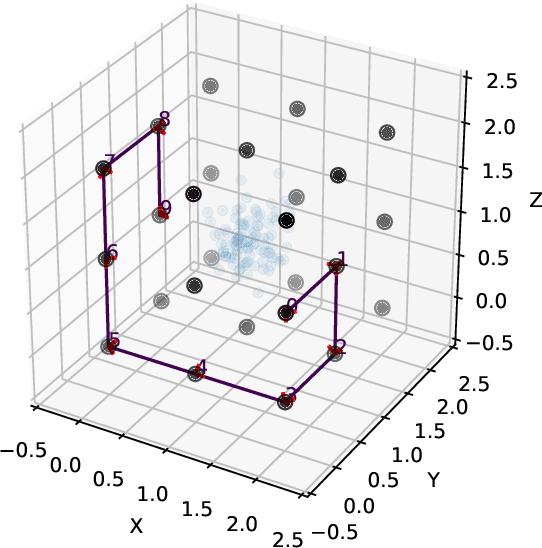

This paper presents SIM-Sync, a certifiably optimal algorithm that estimates camera trajectory and 3D scene structure directly from multiview image keypoints. SIM-Sync fills the gap between pose graph optimization and bundle adjustment; the former admits efficient global optimization but requires relative pose measurements and the latter directly consumes image keypoints but is difficult to optimize globally (due to camera projective geometry). The bridge to this gap is a pretrained depth prediction network. Given a graph with nodes representing monocular images taken at unknown camera poses and edges containing pairwise image keypoint correspondences, SIM-Sync first uses a pretrained depth prediction network to lift the 2D keypoints into 3D scaled point clouds, where the scaling of the per-image point cloud is unknown due to the scale ambiguity in monocular depth prediction. SIM-Sync then seeks to synchronize jointly the unknown camera poses and scaling factors (i.e., over the 3D similarity group). The SIM-Sync formulation, despite nonconvex, allows designing an efficient certifiably optimal solver that is almost identical to the SE-Sync algorithm. We demonstrate the tightness, robustness, and practical usefulness of SIM-Sync in both simulated and real experiments. In simulation, we show (i) SIM-Sync compares favorably with SE-Sync in scale-free synchronization, and (ii) SIM-Sync can be used together with robust estimators to tolerate a high amount of outliers. In real experiments, we show (a) SIM-Sync achieves similar performance as Ceres on bundle adjustment datasets, and (b) SIM-Sync performs on par with ORB-SLAM3 on the TUM dataset with zero-shot depth prediction.
Fully Proprioceptive Slip-Velocity-Aware State Estimation for Mobile Robots via Invariant Kalman Filtering and Disturbance Observer
Sep 29, 2022
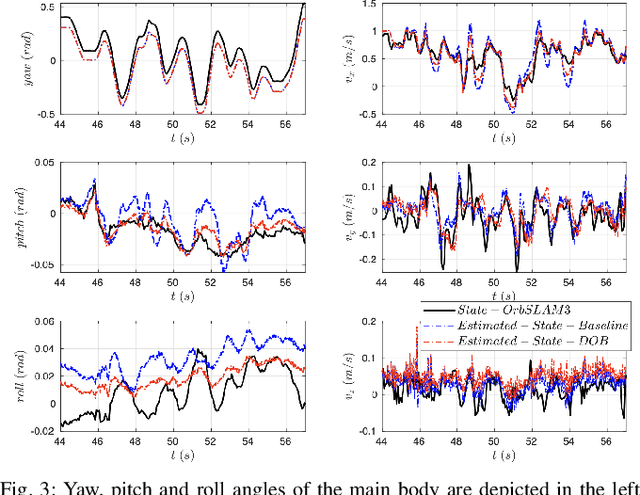
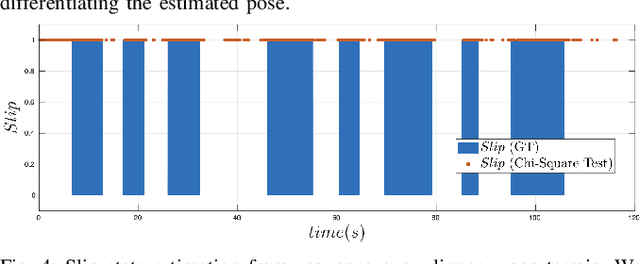

This paper develops a novel slip estimator using the invariant observer design theory and Disturbance Observer (DOB). The proposed state estimator for mobile robots is fully proprioceptive and combines data from an inertial measurement unit and body velocity within a Right Invariant Extended Kalman Filter (RI-EKF). By embedding the slip velocity into $\mathrm{SE}_3(3)$ Lie group, the developed DOB-based RI-EKF provides real-time accurate velocity and slip velocity estimates on different terrains. Experimental results using a Husky wheeled robot confirm the mathematical derivations and show better performance than a standard RI-EKF baseline. Open source software is available for download and reproducing the presented results.